Эта тема объясняет, как работать с последовательностью и данными временных рядов для классификации и задач регрессии с помощью сетей долгой краткосрочной памяти (LSTM). Для примера, показывающего, как классифицировать данные о последовательности с помощью сети LSTM, смотрите, что Классификация Последовательностей Использует Глубокое обучение.
Сеть LSTM является типом рекуррентной нейронной сети (RNN), которая может изучить долгосрочные зависимости между временными шагами данных о последовательности.
Базовые компоненты сети LSTM являются входным слоем последовательности и слоем LSTM. Последовательность ввела входную последовательность слоя или данные временных рядов в сеть. Слой LSTM изучает долгосрочные зависимости между временными шагами данных о последовательности.
Эта схема иллюстрирует архитектуру простой сети LSTM для классификации. Сеть запускается с входного слоя последовательности, сопровождаемого слоем LSTM. Чтобы предсказать метки класса, сеть заканчивается полносвязным слоем, softmax слоем и классификацией выходной слой.
![]()
Эта схема иллюстрирует архитектуру простой сети LSTM для регрессии. Сеть запускается с входного слоя последовательности, сопровождаемого слоем LSTM. Сетевые концы с полносвязным слоем и регрессией выводят слой.
![]()
Эта схема иллюстрирует архитектуру сети для видео классификации. Чтобы ввести последовательности изображений к сети, используйте входной слой последовательности. Чтобы использовать сверточные слои, чтобы извлечь функции, то есть, применить сверточные операции к каждой системе координат видео независимо, используют слой сворачивания последовательности, сопровождаемый сверточными слоями, и затем слоем разворачивания последовательности. Чтобы использовать слои LSTM, чтобы извлечь уроки из последовательностей векторов, используйте сглаживать слой, сопровождаемый LSTM, и выведите слои.

Чтобы создать сеть LSTM для классификации последовательностей к метке, создайте массив слоя, содержащий входной слой последовательности, слой LSTM, полносвязный слой, softmax слой и классификацию выходной слой.
Установите размер входного слоя последовательности к количеству функций входных данных. Установите размер полносвязного слоя к количеству классов. Вы не должны задавать длину последовательности.
Для слоя LSTM задайте количество скрытых модулей и режима вывода 'last'.
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Для примера, показывающего, как обучить сеть LSTM для классификации последовательностей к метке и классифицировать новые данные, смотрите, что Классификация Последовательностей Использует Глубокое обучение.
Чтобы создать сеть LSTM для классификации от последовательности к последовательности, используйте ту же архитектуру что касается классификации последовательностей к метке, но установите режим вывода слоя LSTM к 'sequence'.
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','sequence') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Чтобы создать сеть LSTM для sequence-one регрессии, создайте массив слоя, содержащий входной слой последовательности, слой LSTM, полносвязный слой и регрессию выходной слой.
Установите размер входного слоя последовательности к количеству функций входных данных. Установите размер полносвязного слоя к количеству ответов. Вы не должны задавать длину последовательности.
Для слоя LSTM задайте количество скрытых модулей и режима вывода 'last'.
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numResponses) regressionLayer];
Чтобы создать сеть LSTM для регрессии от последовательности к последовательности, используйте ту же архитектуру что касается sequence-one регрессии, но установите режим вывода слоя LSTM к 'sequence'.
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','sequence') fullyConnectedLayer(numResponses) regressionLayer];
Для примера, показывающего, как обучить сеть LSTM для регрессии от последовательности к последовательности и предсказать на новых данных, смотрите, что Регрессия От последовательности к последовательности Использует Глубокое обучение.
Чтобы создать нейронную сеть для глубокого обучения для данных, содержащих последовательности изображений, такие как видеоданные и медицинские изображения, задайте вход последовательности изображений с помощью входного слоя последовательности.
Чтобы использовать сверточные слои, чтобы извлечь функции, то есть, применить сверточные операции к каждой системе координат видео независимо, используют слой сворачивания последовательности, сопровождаемый сверточными слоями, и затем слоем разворачивания последовательности. Чтобы использовать слои LSTM, чтобы извлечь уроки из последовательностей векторов, используйте сглаживать слой, сопровождаемый LSTM, и выведите слои.
inputSize = [28 28 1]; filterSize = 5; numFilters = 20; numHiddenUnits = 200; numClasses = 10; layers = [ ... sequenceInputLayer(inputSize,'Name','input') sequenceFoldingLayer('Name','fold') convolution2dLayer(filterSize,numFilters,'Name','conv') batchNormalizationLayer('Name','bn') reluLayer('Name','relu') sequenceUnfoldingLayer('Name','unfold') flattenLayer('Name','flatten') lstmLayer(numHiddenUnits,'OutputMode','last','Name','lstm') fullyConnectedLayer(numClasses, 'Name','fc') softmaxLayer('Name','softmax') classificationLayer('Name','classification')];
Преобразуйте слои в график слоев и соедините miniBatchSize выход слоя сворачивания последовательности к соответствующему входу слоя разворачивания последовательности.
lgraph = layerGraph(layers); lgraph = connectLayers(lgraph,'fold/miniBatchSize','unfold/miniBatchSize');
Для примера, показывающего, как обучить нейронную сеть для глубокого обучения видео классификации, смотрите, Классифицируют Видео Используя Глубокое обучение.
Можно сделать сети LSTM глубже путем вставки дополнительных слоев LSTM с режимом вывода 'sequence' перед слоем LSTM. Чтобы предотвратить сверхподбор кривой, можно вставить слои уволенного после слоев LSTM.
Для сетей классификации последовательностей к метке режимом вывода последнего слоя LSTM должен быть 'last'.
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,'OutputMode','sequence') dropoutLayer(0.2) lstmLayer(numHiddenUnits2,'OutputMode','last') dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Для сетей классификации от последовательности к последовательности режимом вывода последнего слоя LSTM должен быть 'sequence'.
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,'OutputMode','sequence') dropoutLayer(0.2) lstmLayer(numHiddenUnits2,'OutputMode','sequence') dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
| Слой | Описание |
|---|---|
| Последовательность ввела входные данные о последовательности слоя к сети. | |
| Слой LSTM изучает долгосрочные зависимости между временными шагами в данных о последовательности и временных рядах. | |
| Двунаправленный слой LSTM (BiLSTM) изучает двунаправленные долгосрочные зависимости между временными шагами данных о последовательности или временных рядов. Эти зависимости могут быть полезными, когда это необходимо, сеть, чтобы извлечь уроки из полных временных рядов на каждом временном шаге. | |
| Слой ГРУ изучает зависимости между временными шагами в данных о последовательности и временных рядах. | |
| Слой сворачивания последовательности преобразует пакет последовательностей изображений к пакету изображений. Используйте слой сворачивания последовательности, чтобы выполнить операции свертки на временных шагах последовательностей изображений независимо. | |
| Слой разворачивания последовательности восстанавливает структуру последовательности входных данных после сворачивания последовательности. | |
| Сглаживать слой сворачивает пространственные размерности входа в размерность канала. | |
| Слой встраивания слова сопоставляет словари с векторами. |
Чтобы классифицировать или сделать предсказания на новых данных, используйте classify и predict.
Сети LSTM могут помнить состояние сети между предсказаниями. Сетевое состояние полезно, когда у вас нет полных временных рядов заранее, или если вы хотите сделать несколько предсказаний на долговременном ряде.
Чтобы предсказать и классифицировать на частях временных рядов и обновить сетевое состояние, используйте predictAndUpdateState и classifyAndUpdateState. Чтобы сбросить сетевое состояние между предсказаниями, используйте resetState.
Для примера, показывающего, как предсказать будущие временные шаги последовательности, смотрите, что Временные ряды Предсказывают Используя Глубокое обучение.
Сети LSTM поддерживают входные данные с различными длинами последовательности. Когда передающие данные через сеть, клавиатуры программного обеспечения, обрезают или разделяют последовательности так, чтобы все последовательности в каждом мини-пакете имели заданную длину. Можно задать длины последовательности, и значение раньше заполняло последовательности с помощью SequenceLength и SequencePaddingValue аргументы пары "имя-значение" в trainingOptions.
После обучения сети используйте тот же мини-пакетный размер и дополнение опций при использовании classify, predict, classifyAndUpdateState, predictAndUpdateState, и activations функции.
Чтобы уменьшать объем дополнения или отброшенных данных при дополнении или усечении последовательностей, попытайтесь сортировать данные по длине последовательности. Чтобы отсортировать данные по длине последовательности, сначала получите количество столбцов каждой последовательности путем применения size(X,2) к каждой последовательности с помощью cellfun. Затем отсортируйте длины последовательности с помощью sort, и используйте второй выход, чтобы переупорядочить исходные последовательности.
sequenceLengths = cellfun(@(X) size(X,2), XTrain); [sequenceLengthsSorted,idx] = sort(sequenceLengths); XTrain = XTrain(idx);
Следующие рисунки показывают длины последовательности отсортированных и неотсортированных данных в столбчатых диаграммах.

Если вы задаете длину последовательности 'longest', затем программное обеспечение заполняет последовательности так, чтобы все последовательности в мини-пакете имели ту же длину как самая длинная последовательность в мини-пакете. Эта опция является значением по умолчанию.
Следующие фигуры иллюстрируют эффект установки 'SequenceLength' к 'longest'.

Если вы задаете длину последовательности 'shortest', затем программное обеспечение обрезает последовательности так, чтобы все последовательности в мини-пакете имели ту же длину как самая короткая последовательность в том мини-пакете. Остающиеся данные в последовательностях отбрасываются.
Следующие фигуры иллюстрируют эффект установки 'SequenceLength' к 'shortest'.

Если вы устанавливаете длину последовательности на целочисленное значение, то программное обеспечение заполняет все последовательности в мини-пакете к самому близкому кратному заданная длина, которая больше самой долгой длины последовательности в мини-пакете. Затем программное обеспечение разделяет каждую последовательность в меньшие последовательности заданной длины. Если разделение происходит, то программное обеспечение создает дополнительные мини-пакеты.
Используйте эту опцию, если полные последовательности не умещаются в памяти. В качестве альтернативы можно попытаться сократить количество последовательностей на мини-пакет путем установки 'MiniBatchSize' опция в trainingOptions к нижнему значению.
Если вы задаете длину последовательности как положительное целое число, то программные процессы меньшие последовательности в последовательных итерациях. Сеть обновляет сетевое состояние между последовательностями разделения.
Следующие фигуры иллюстрируют эффект установки 'SequenceLength' к 5.

Местоположение дополнения и усечения может повлиять на обучение, классификацию и точность предсказания. Попытайтесь установить 'SequencePaddingDirection' опция в trainingOptions к 'left' или 'right' и смотрите, который является лучшим для ваших данных.
Поскольку слои LSTM обрабатывают данные о последовательности один временной шаг за один раз, когда слой OutputMode свойством является 'last', любое дополнение в итоговых временных шагах может негативно влиять на слой выход. Чтобы заполнить или обрезать данные о последовательности слева, установите 'SequencePaddingDirection' опция к 'left'.
Для сетей от последовательности к последовательности (когда OutputMode свойством является 'sequence' для каждого слоя LSTM), любой дополняющий в первых временных шагах может негативно влиять на предсказания для более ранних временных шагов. Чтобы заполнить или обрезать данные о последовательности справа, установите 'SequencePaddingDirection' опция к 'right'.
Следующие фигуры иллюстрируют дополнительные данные о последовательности слева и справа.

Следующие фигуры иллюстрируют данные о последовательности усечения слева и справа.

Чтобы повторно сосредоточить обучающие данные автоматически в учебное время с помощью нулевой центральной нормализации, установите Normalization опция sequenceInputLayer к 'zerocenter'. В качестве альтернативы можно нормировать данные о последовательности первым вычислением среднего и стандартного отклонения на функцию всех последовательностей. Затем для каждого учебного наблюдения вычтите среднее значение и разделитесь на стандартное отклонение.
mu = mean([XTrain{:}],2);
sigma = std([XTrain{:}],0,2);
XTrain = cellfun(@(X) (X-mu)./sigma,XTrain,'UniformOutput',false);Используйте хранилища данных в последовательности, временных рядах и данных сигнала, когда данные будут слишком большими, чтобы уместиться в памяти или выполнить определенные операции при чтении пакетов данных.
Чтобы узнать больше, смотрите, Обучат сеть Используя Данные о Последовательности Из памяти и Классифицируют текстовые Данные Из памяти Используя Глубокое обучение.
Исследуйте и визуализируйте функции, усвоенные сетями LSTM из последовательности и данных временных рядов путем извлечения активаций с помощью activations функция. Чтобы узнать больше, смотрите, Визуализируют Активации Сети LSTM.
Эта схема иллюстрирует поток временных рядов, X с C показывает (каналы) длины S через слой LSTM. В схеме, и обозначьте выход (также известный как скрытое состояние) и состояние ячейки на временном шаге t, соответственно.
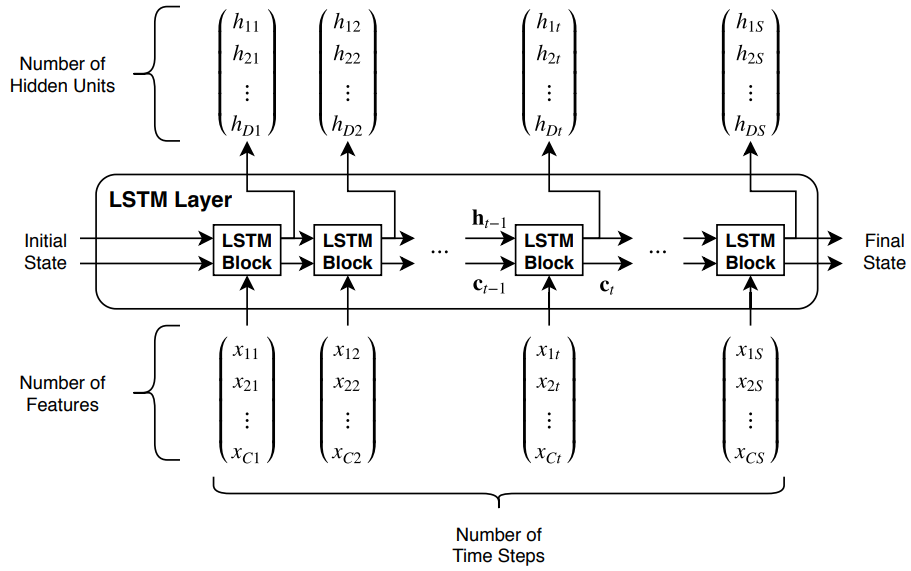
Первый блок LSTM использует начальное состояние сети и первый временной шаг последовательности, чтобы вычислить первый выход и обновленное состояние ячейки. На временном шаге t блок использует текущее состояние сети и следующий временной шаг последовательности, который вычислит выход и обновленное состояние ячейки .
Состояние слоя состоит из скрытого состояния (также известный как состояние вывода) и состояния ячейки. Скрытое состояние на временном шаге t содержит выход слоя LSTM для этого временного шага. Состояние ячейки содержит информацию, усвоенную из предыдущих временных шагов. На каждом временном шаге слой добавляет информацию в или удаляет информацию из состояния ячейки. Слой управляет этими обновлениями с помощью логических элементов.
Следующие компоненты управляют ячейкой и скрытое состояние состояния слоя.
| Компонент | Цель |
|---|---|
| Введите логический элемент (i) | Управляйте уровнем обновления состояния ячейки |
| Забудьте логический элемент (f) | Уровень управления сброса состояния ячейки (забывает) |
| Кандидат ячейки (g) | Добавьте информацию в состояние ячейки |
| Выведите логический элемент (o) | Управляйте уровнем состояния ячейки, добавленного к скрытому состоянию |
Эта схема иллюстрирует поток данных на временном шаге t. Подсветки схемы, как логические элементы забывают, обновляются и выводят ячейку и скрытые состояния.
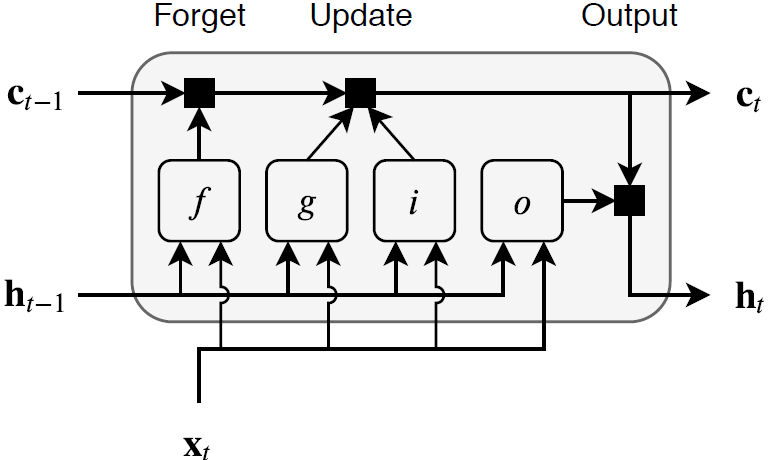
learnable веса слоя LSTM являются входными весами W (InputWeights), текущие веса R (RecurrentWeights), и смещение b (Bias). Матрицы W, R и b являются конкатенациями входных весов, текущих весов и смещения каждого компонента, соответственно. Эти матрицы конкатенированы можно следующим образом:
где i, f, g и o обозначают входной логический элемент, забывают логический элемент, кандидата ячейки, и выводят логический элемент, соответственно.
Состоянием ячейки на временном шаге t дают
где обозначает продукт Адамара (поэлементное умножение векторов).
Скрытым состоянием на временном шаге t дают
где обозначает функцию активации состояния. lstmLayer функция, по умолчанию, использует гиперболическую функцию тангенса (tanh), чтобы вычислить функцию активации состояния.
Следующие формулы описывают компоненты на временном шаге t.
| Компонент | Формула |
|---|---|
| Введите логический элемент | |
| Забудьте логический элемент | |
| Кандидат ячейки | |
| Выведите логический элемент |
В этих вычислениях, обозначает функцию активации логического элемента. lstmLayer функция, по умолчанию, использует сигмоидальную функцию, данную вычислить функцию активации логического элемента.
[1] Hochreiter, S. и Дж. Шмидхубер. "Долгая краткосрочная память". Нейронный расчет. Издание 9, Номер 8, 1997, pp.1735-1780.
activations | bilstmLayer | classifyAndUpdateState | flattenLayer | gruLayer | lstmLayer | predictAndUpdateState | resetState | sequenceFoldingLayer | sequenceInputLayer | sequenceUnfoldingLayer | wordEmbeddingLayer
