Слой Long short-term memory (LSTM)
Слой LSTM изучает долгосрочные зависимости между временными шагами в данных о последовательности и временных рядах.
Слой выполняет аддитивные взаимодействия, которые могут помочь улучшить поток градиента по длинным последовательностям во время обучения.
layer = lstmLayer(numHiddenUnits)NumHiddenUnits свойство.
layer = lstmLayer(numHiddenUnits,Name,Value)OutputMode, Активации, состояние, параметры и инициализация, изучают уровень и регуляризацию и Name свойства с помощью одного или нескольких аргументов пары "имя-значение". Можно задать несколько аргументов пары "имя-значение". Заключите каждое имя свойства в кавычки.
Создайте слой LSTM с именем 'lstm1' и 100 скрытых модулей.
layer = lstmLayer(100,'Name','lstm1')
layer =
LSTMLayer with properties:
Name: 'lstm1'
Hyperparameters
InputSize: 'auto'
NumHiddenUnits: 100
OutputMode: 'sequence'
StateActivationFunction: 'tanh'
GateActivationFunction: 'sigmoid'
Learnable Parameters
InputWeights: []
RecurrentWeights: []
Bias: []
State Parameters
HiddenState: []
CellState: []
Show all properties
Включайте слой LSTM в Layer массив.
inputSize = 12;
numHiddenUnits = 100;
numClasses = 9;
layers = [ ...
sequenceInputLayer(inputSize)
lstmLayer(numHiddenUnits)
fullyConnectedLayer(numClasses)
softmaxLayer
classificationLayer]layers =
5x1 Layer array with layers:
1 '' Sequence Input Sequence input with 12 dimensions
2 '' LSTM LSTM with 100 hidden units
3 '' Fully Connected 9 fully connected layer
4 '' Softmax softmax
5 '' Classification Output crossentropyex
Обучите сеть LSTM глубокого обучения для классификации последовательностей к метке.
Загрузите японский набор данных Гласных как описано в [1] и [2]. XTrain массив ячеек, содержащий 270 последовательностей различной длины с размерностью признаков 12. Y категориальный вектор меток 1,2..., 9. Записи в XTrain матрицы с 12 строками (одна строка для каждого признака) и различным количеством столбцов (один столбец для каждого временного шага).
[XTrain,YTrain] = japaneseVowelsTrainData;
Визуализируйте первые временные ряды в графике. Каждая линия соответствует функции.
figure
plot(XTrain{1}')
title("Training Observation 1")
numFeatures = size(XTrain{1},1);
legend("Feature " + string(1:numFeatures),'Location','northeastoutside')
Задайте архитектуру сети LSTM. Задайте входной размер как 12 (количество функций входных данных). Задайте слой LSTM, чтобы иметь 100 скрытых модулей и вывести последний элемент последовательности. Наконец, задайте девять классов включением полносвязного слоя размера 9, сопровождаемый softmax слоем и слоем классификации.
inputSize = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(inputSize) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer]
layers =
5x1 Layer array with layers:
1 '' Sequence Input Sequence input with 12 dimensions
2 '' LSTM LSTM with 100 hidden units
3 '' Fully Connected 9 fully connected layer
4 '' Softmax softmax
5 '' Classification Output crossentropyex
Задайте опции обучения. Задайте решатель как 'adam' и 'GradientThreshold' как 1. Установите мини-пакетный размер на 27 и определите максимальный номер эпох к 100.
Поскольку мини-пакеты малы с короткими последовательностями, центральный процессор лучше подходит для обучения. Установите 'ExecutionEnvironment' к 'cpu'. Чтобы обучаться на графическом процессоре, при наличии, устанавливает 'ExecutionEnvironment' к 'auto' (значение по умолчанию).
maxEpochs = 100; miniBatchSize = 27; options = trainingOptions('adam', ... 'ExecutionEnvironment','cpu', ... 'MaxEpochs',maxEpochs, ... 'MiniBatchSize',miniBatchSize, ... 'GradientThreshold',1, ... 'Verbose',false, ... 'Plots','training-progress');
Обучите сеть LSTM с заданными опциями обучения.
net = trainNetwork(XTrain,YTrain,layers,options);

Загрузите набор тестов и классифицируйте последовательности в динамики.
[XTest,YTest] = japaneseVowelsTestData;
Классифицируйте тестовые данные. Задайте тот же мини-пакетный размер, используемый в обучении.
YPred = classify(net,XTest,'MiniBatchSize',miniBatchSize);Вычислите точность классификации предсказаний.
acc = sum(YPred == YTest)./numel(YTest)
acc = 0.9486
Чтобы создать сеть LSTM для классификации последовательностей к метке, создайте массив слоя, содержащий входной слой последовательности, слой LSTM, полносвязный слой, softmax слой и классификацию выходной слой.
Установите размер входного слоя последовательности к количеству функций входных данных. Установите размер полносвязного слоя к количеству классов. Вы не должны задавать длину последовательности.
Для слоя LSTM задайте количество скрытых модулей и режима вывода 'last'.
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Для примера, показывающего, как обучить сеть LSTM для классификации последовательностей к метке и классифицировать новые данные, смотрите, что Классификация Последовательностей Использует Глубокое обучение.
Чтобы создать сеть LSTM для классификации от последовательности к последовательности, используйте ту же архитектуру что касается классификации последовательностей к метке, но установите режим вывода слоя LSTM к 'sequence'.
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','sequence') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Чтобы создать сеть LSTM для sequence-one регрессии, создайте массив слоя, содержащий входной слой последовательности, слой LSTM, полносвязный слой и регрессию выходной слой.
Установите размер входного слоя последовательности к количеству функций входных данных. Установите размер полносвязного слоя к количеству ответов. Вы не должны задавать длину последовательности.
Для слоя LSTM задайте количество скрытых модулей и режима вывода 'last'.
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numResponses) regressionLayer];
Чтобы создать сеть LSTM для регрессии от последовательности к последовательности, используйте ту же архитектуру что касается sequence-one регрессии, но установите режим вывода слоя LSTM к 'sequence'.
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','sequence') fullyConnectedLayer(numResponses) regressionLayer];
Для примера, показывающего, как обучить сеть LSTM для регрессии от последовательности к последовательности и предсказать на новых данных, смотрите, что Регрессия От последовательности к последовательности Использует Глубокое обучение.
Можно сделать сети LSTM глубже путем вставки дополнительных слоев LSTM с режимом вывода 'sequence' перед слоем LSTM. Чтобы предотвратить сверхподбор кривой, можно вставить слои уволенного после слоев LSTM.
Для сетей классификации последовательностей к метке режимом вывода последнего слоя LSTM должен быть 'last'.
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,'OutputMode','sequence') dropoutLayer(0.2) lstmLayer(numHiddenUnits2,'OutputMode','last') dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Для сетей классификации от последовательности к последовательности режимом вывода последнего слоя LSTM должен быть 'sequence'.
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,'OutputMode','sequence') dropoutLayer(0.2) lstmLayer(numHiddenUnits2,'OutputMode','sequence') dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Слой LSTM изучает долгосрочные зависимости между временными шагами в данных о последовательности и временных рядах.
Состояние слоя состоит из скрытого состояния (также известный как состояние вывода) и состояния ячейки. Скрытое состояние на временном шаге t содержит выход слоя LSTM для этого временного шага. Состояние ячейки содержит информацию, усвоенную из предыдущих временных шагов. На каждом временном шаге слой добавляет информацию в или удаляет информацию из состояния ячейки. Слой управляет этими обновлениями с помощью логических элементов.
Следующие компоненты управляют ячейкой и скрытое состояние состояния слоя.
| Компонент | Цель |
|---|---|
| Введите логический элемент (i) | Управляйте уровнем обновления состояния ячейки |
| Забудьте логический элемент (f) | Уровень управления сброса состояния ячейки (забывает) |
| Кандидат ячейки (g) | Добавьте информацию в состояние ячейки |
| Выведите логический элемент (o) | Управляйте уровнем состояния ячейки, добавленного к скрытому состоянию |
Эта схема иллюстрирует поток данных на временном шаге t. Подсветки схемы, как логические элементы забывают, обновляются и выводят ячейку и скрытые состояния.
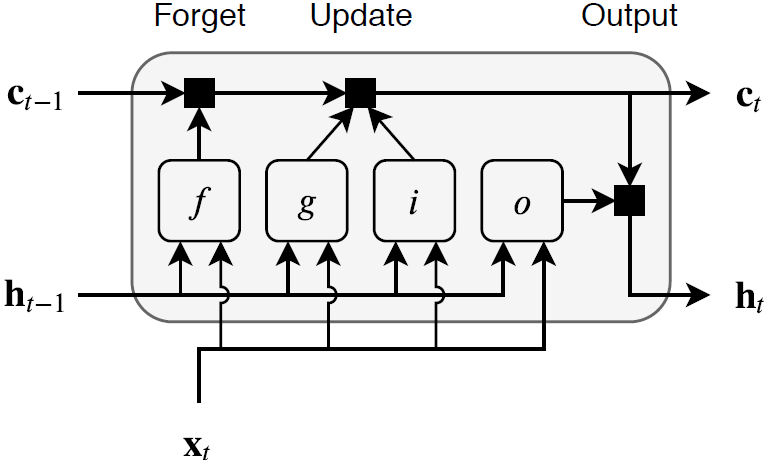
learnable веса слоя LSTM являются входными весами W (InputWeights), текущие веса R (RecurrentWeights), и смещение b (Bias). Матрицы W, R и b являются конкатенациями входных весов, текущих весов и смещения каждого компонента, соответственно. Эти матрицы конкатенированы можно следующим образом:
где i, f, g и o обозначают входной логический элемент, забывают логический элемент, кандидата ячейки, и выводят логический элемент, соответственно.
Состоянием ячейки на временном шаге t дают
где обозначает продукт Адамара (поэлементное умножение векторов).
Скрытым состоянием на временном шаге t дают
где обозначает функцию активации состояния. lstmLayer функция, по умолчанию, использует гиперболическую функцию тангенса (tanh), чтобы вычислить функцию активации состояния.
Следующие формулы описывают компоненты на временном шаге t.
| Компонент | Формула |
|---|---|
| Введите логический элемент | |
| Забудьте логический элемент | |
| Кандидат ячейки | |
| Выведите логический элемент |
В этих вычислениях, обозначает функцию активации логического элемента. lstmLayer функция, по умолчанию, использует сигмоидальную функцию, данную вычислить функцию активации логического элемента.
[1] М. Кудо, J. Тояма, и М. Шимбо. "Многомерная Классификация Кривых Используя Прохождение через области". Буквы Распознавания образов. Издание 20, № 11-13, страницы 1103-1111.
[2] Репозиторий Машинного обучения UCI: японский Набор данных Гласных. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
[3] Hochreiter, S, и Дж. Шмидхубер, 1997. Долгая краткосрочная память. Нейронный расчет, 9 (8), pp.1735–1780.
[4] Glorot, Ксавьер и Иосуа Бенхио. "Изучая трудность учебных глубоких нейронных сетей feedforward". В Продолжениях тринадцатой международной конференции по вопросам искусственного интеллекта и статистики, стр 249-256. 2010.
[5] Он, Kaiming, Сянюй Чжан, Шаоцин Жэнь и Цзянь Сунь. "Копаясь глубоко в выпрямителях: Превосходная производительность человеческого уровня на imagenet классификации". В Продолжениях международной конференции IEEE по вопросам компьютерного зрения, стр 1026-1034. 2015.
[6] Saxe, Эндрю М., Джеймс Л. Макклеллэнд и Сурья Гэнгули. "Точные решения нелинейной динамики изучения в глубоких линейных нейронных сетях". arXiv предварительно распечатывают arXiv:1312.6120 (2013).
Deep Network Designer | bilstmLayer | classifyAndUpdateState | flattenLayer | gruLayer | predictAndUpdateState | resetState | sequenceFoldingLayer | sequenceInputLayer | sequenceUnfoldingLayer
