Многоядерное программирование помогает вам создать параллельные системы для развертывания на многоядерном процессоре и многопроцессорных системах. Система многоядерного процессора является одним процессором с несколькими ядрами выполнения в одном чипе. В отличие от этого, многопроцессорная система имеет несколько процессоров на материнской плате или чипе. Многопроцессорная система может включать Программируемую пользователем вентильную матрицу (FPGA). FPGA является интегральной схемой, содержащей массив блоков программируемой логики и иерархию реконфигурируемых межсоединений. Процессорный узел входные данные процессов, чтобы произвести выходные параметры. Это может быть процессор в многожильной или многопроцессорной системе или FPGA.
Подход многоядерного программирования может помочь когда:
Вы хотите использовать в своих интересах многожильный и обработка FPGA, чтобы увеличить производительность встраиваемой системы.
Вы хотите достигнуть масштабируемости, таким образом, ваша развернутая система может использовать в своих интересах растущие числа ядер и вычислительной мощности FPGA в зависимости от времени.
Параллельные системы, что вы создаете многоядерное программирование использования, имеют несколько задач, выполняющихся параллельно. Это известно как параллельное выполнение. Когда процессор выполняет несколько параллельных задач, он известен как многозадачность. Центральный процессор имеет встроенное программное обеспечение, названное планировщиком, который справляется с задачами, которые выполняются параллельно. Центральный процессор реализует задачи с помощью потоков операционной системы. Ваши задачи могут выполниться независимо, но иметь некоторую передачу данных между ними, такую как передача данных между модулем сбора данных и контроллером для системы. Передача данных между задачами означает, что существует зависимость по данным.
Многоядерное программирование обычно используется в обработке сигналов и системах управления объекта. В обработке сигналов у вас может быть параллельная система, которая обрабатывает несколько кадров параллельно. В системах управления объекта контроллер и объект могут выполниться как две отдельных задачи. Используя многоядерное программирование помогает разделить вашу систему в несколько параллельных задач, которые запускаются одновременно, ускоряя полное время выполнения.
Чтобы смоделировать одновременно выполняющуюся систему, см. Инструкции по Разделению.
Концепция многоядерного программирования должна иметь несколько системных задач, выполняющихся параллельно. Типы параллелизма включают:
Параллелизм данных
Параллелизм задачи
Конвейеризация
Параллелизм данных включает обработку нескольких частей информационно-независимо параллельно. Процессор выполняет ту же операцию на каждой части данных. Вы достигаете параллелизма путем питания данных параллельно.
Рисунок показывает схему синхронизации для этого параллелизма. Вход разделен на четыре фрагмента, A, B, C, и D. Та же операция F() применяется к каждой из этих частей, и выходом является OA, ОБЬ, OC и OD соответственно. Все четыре задачи идентичны, и они запускаются параллельно.


Временем, потраченным на цикл процессора, известный как время цикла, является t = tF.
Общим временем вычислений является также tF, начиная со всех четырех задач, запущенных одновременно. В отсутствие параллелизма все четыре части данных обрабатываются одним процессорным узлом. Временем цикла является tF поскольку каждой задачей, но общее время вычислений является 4*tF, поскольку части обрабатываются по очереди.
Можно использовать параллелизм данных в сценариях, где возможно обработать каждую часть входных данных независимо. Например, веб-база данных с независимыми наборами данных для обработки или обработки кадров видео независимо является хорошими кандидатами на параллелизм данных.
В отличие от параллелизма данных, параллелизм задачи не разделяет входные данные. Вместо этого это достигает параллелизма путем разделения приложения на несколько задач. Параллелизм задачи включает распределительные задачи в рамках приложения через несколько процессорных узлов. Некоторые задачи могут иметь зависимость по данным от других, таким образом, все задачи не запускаются в точно то же время.
Рассмотрите систему, которая включает четыре функции. Функции, которые F2a () и F2b () параллельно, то есть, они могут запуститься одновременно. В параллелизме задачи можно разделить расчет на две задачи. Функциональный F2b () работает на отдельном процессорном узле после того, как это получает данные Out1 от Задачи 1, и это выводит назад к F3 () в Задаче 1.

Рисунок показывает схему синхронизации для этого параллелизма. Задача 2 не запускается, пока это не получает данные Out1 от Задачи 1. Следовательно, эти задачи не запускаются полностью параллельно. Время, потраченное на цикл процессора, известный как время цикла,
t = tF1 + макс. (tF2a, tF2b) + tF3.

Можно использовать параллелизм задачи в сценариях, таких как фабрика где объект и контроллер, запущенный параллельно.
Используйте конвейерное выполнение модели или конвейеризацию, чтобы работать вокруг проблемы параллелизма задачи, куда потоки не запускаются полностью параллельно. Этот подход включает изменение вашей системной модели, чтобы ввести задержки между задачами, где существует зависимость по данным.
В этом рисунке система разделена на три задачи работать на трех различных процессорных узлах с задержками, введенными между функциями. На каждом временном шаге каждая задача берет в значении от предыдущего временного шага посредством задержки.
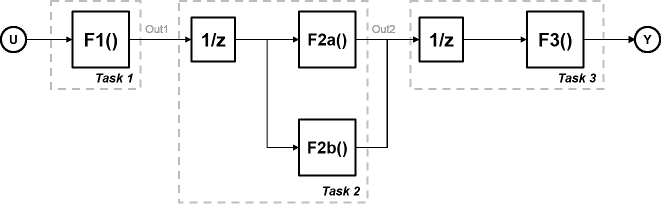
Каждая задача может начать обрабатывать одновременно, когда эта схема синхронизации показывает. Эти задачи действительно параллельны, и они последовательно больше не зависят друг от друга в одном цикле процессора. Время цикла не имеет никаких сложений, но является максимальным временем вычислений всех задач.
t = макс. (Task1, Task2, Task3) = макс. (tF1, tF2a, tF2b, tF3).

Можно использовать конвейеризацию везде, где можно ввести задержки искусственно одновременно выполняющейся системы. Получившиеся издержки из-за этого введения не должны превышать время, сохраненное путем конвейеризации.
Разделение методов помогает вам определять области своей системы для параллельного выполнения. Разделение позволяет вам создавать задачи независимо от специфических особенностей целевой системы, на которой развертывается приложение.
Рассмотрите эту систему. F1–F6 являются функциями системы, которая может быть выполнена независимо. Стрелка между двумя функциями указывает на зависимость по данным. Например, выполнение F5 имеет зависимость по данным от F3.
Выполнение этих функций присвоено различным узлам процессора в целевой системе. Серые стрелки указывают на присвоение функций, которые будут развернуты на центральном процессоре или FPGA. Планировщик центрального процессора определяет когда отдельные запущенные задачи. Центральный процессор и FPGA связываются через общую коммуникационную шину.
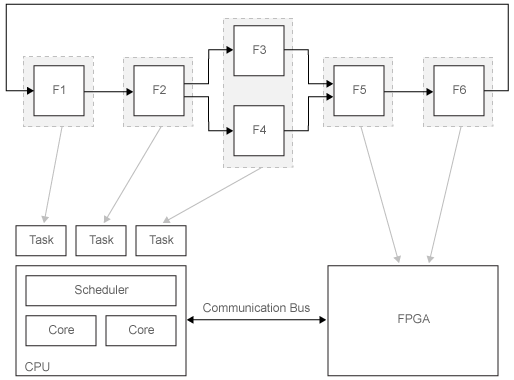
Рисунок показывает одну возможную настройку для разделения. В общем случае вы тестируете различные настройки и итеративно улучшаетесь, пока вы не получаете оптимальное распределение задач для вашего приложения.
Вручную кодирование вашего приложения на многоядерный процессор или FPGA ставит проблемы вне проблем, вызванных ручным кодированием. В параллельном выполнении необходимо отследить:
Планирование задач, которые выполняются на встроенном многоядерном процессоре системы обработки
Передачи данных к и от различных процессорных узлов
Simulink справляется с реализацией задач и передачей данных между задачами. Это также генерирует код, который развертывается для приложения. Для получения дополнительной информации смотрите Многоядерное программирование с Simulink.
В дополнение к этим проблемам существуют проблемы, когда это необходимо, чтобы развернуть ваше приложение в различные архитектуры и, когда это необходимо, улучшать производительность развертываемого приложения.
Аппаратная конфигурация, которая запускает развертываемое приложение, известна как архитектуру. Это может содержать многоядерные процессоры, многопроцессорные системы, FPGAs или комбинацию их. Развертывание того же приложения к различным архитектурам может потребовать усилия из-за:
Различный номер и типы узлов процессора на архитектуре
Коммуникация и стандарты передачи данных для архитектуры
Стандарты для определенных событий, синхронизации и защиты данных в каждой архитектуре
Чтобы развернуть приложение вручную, необходимо повторно присвоить задачи различным процессорным узлам для каждой архитектуры. Вы можете также должны быть повторно реализовать свое приложение, если каждая архитектура использует различные стандарты.
Simulink помогает преодолеть эти проблемы путем продукта мобильности через архитектуры. Для получения дополнительной информации смотрите, Как Simulink Помогает Вам Преодолеть проблемы в Многоядерном программировании.
Можно улучшать производительность развертываемого приложения путем балансировки загрузки различных процессорных узлов в многожильной среде обработки. Необходимо выполнить итерации и улучшить распределение задач во время разделения, как упомянуто в Системном Разделении для Параллелизма. Этот процесс включает движущиеся задачи между различными процессорными узлами и проверением получившейся производительности. Поскольку это - итеративный процесс, это занимает время, чтобы найти самое эффективное распределение.
Simulink помогает вам преодолеть эти проблемы профилирование использования. Для получения дополнительной информации смотрите, Как Simulink Помогает Вам Преодолеть проблемы в Многоядерном программировании.
Некоторые задачи системы зависят от выхода других задач. Зависимость по данным между задачами определяет их заказ обработки. Два или больше раздела, содержащие зависимости по данным в цикле, создают цикл зависимости по данным, также известный как алгебраический цикл.
Simulink идентифицирует циклы в вашей системе перед развертыванием. Для получения дополнительной информации смотрите, Как Simulink Помогает Вам Преодолеть проблемы в Многоядерном программировании.
