Агломерационное иерархическое кластерное дерево
Z = linkage(X,method)method, который описывает, как измерить расстояние между кластерами. Для получения дополнительной информации смотрите Рычажные устройства.
Случайным образом сгенерируйте выборочные данные с 20 000 наблюдений.
rng('default') % For reproducibility X = rand(20000,3);
Создайте иерархическое кластерное дерево с помощью ward метод рычажного устройства. В этом случае, 'SaveMemory' опция clusterdata функция установлена в 'on' по умолчанию. В общем случае задайте оптимальное значение для 'SaveMemory' на основе размерностей X и доступная память.
Z = linkage(X,'ward');Кластеризируйте данные максимум в четырех групп и постройте результат.
c = cluster(Z,'Maxclust',4);
scatter3(X(:,1),X(:,2),X(:,3),10,c)
cluster идентифицирует четыре группы в данных.
Найдите максимум трех кластеров в fisheriris набор данных и сравнивает кластерные присвоения цветов к их известной классификации.
Загрузите выборочные данные.
load fisheririsСоздайте иерархическое кластерное дерево с помощью 'average' метод и 'chebychev' метрика.
Z = linkage(meas,'average','chebychev');
Найдите максимум трех кластеров в данных.
T = cluster(Z,'maxclust',3);Создайте график древовидной схемы Z. Чтобы видеть эти три кластера, используйте 'ColorThreshold' с сокращением на полпути между третьими последними и предпредпоследними рычажными устройствами.
cutoff = median([Z(end-2,3) Z(end-1,3)]);
dendrogram(Z,'ColorThreshold',cutoff)
Отобразите последние две строки Z чтобы видеть, как эти три кластера объединены в один. linkage комбинирует 293-й (синий) кластер с 297-м (красным) кластером, чтобы сформировать 298-й кластер с рычажным устройством 1.7583. linkage затем комбинирует 296-й (зеленый) кластер с 298-м кластером.
lastTwo = Z(end-1:end,:)
lastTwo = 2×3
293.0000 297.0000 1.7583
296.0000 298.0000 3.4445
Смотрите, как кластерные присвоения соответствуют трем разновидностям. Например, один из кластеров содержит 50 цветы вторых разновидностей и 40 цветы третьих разновидностей.
crosstab(T,species)
ans = 3×3
0 0 10
0 50 40
50 0 0
Загрузите examgrades набор данных.
load examgradesСоздайте иерархическое дерево с помощью linkage. Используйте 'single' метод и метрика Минковскего с экспонентой 3.
Z = linkage(grades,'single',{'minkowski',3});
Наблюдайте 25-й шаг кластеризации.
Z(25,:)
ans = 1×3
86.0000 137.0000 4.5307
linkage комбинирует 86-е наблюдение и 137-й кластер, чтобы сформировать кластер индекса , где 120 общее количество наблюдений в grades и 25 номер строки в Z. Кратчайшим расстоянием между 86-м наблюдением и любой из точек в 137-м кластере является 4.5307.
Создайте агломерационное иерархическое кластерное дерево с помощью матрицы несходства.
Возьмите матрицу несходства X и преобразуйте его в векторную форму что linkage принимает при помощи squareform.
X = [0 1 2 3; 1 0 4 5; 2 4 0 6; 3 5 6 0]; y = squareform(X);
Создайте кластерное дерево с помощью linkage с 'complete' метод вычисления расстояния между кластерами. Первые два столбца Z покажите как linkage кластеры объединений. Третий столбец Z дает расстояние между кластерами.
Z = linkage(y,'complete')Z = 3×3
1 2 1
3 5 4
4 6 6
Создайте график древовидной схемы Z. Ось X соответствует вершинам дерева, и ось Y соответствует расстояниям рычажного устройства между кластерами.
dendrogram(Z)

Вычисление linkage(y) может быть медленным когда y векторное представление матрицы расстояния. Для 'centroid'медиана, и 'ward' методы, linkage проверки, ли y Евклидово расстояние. Избегайте этой длительной проверки путем передачи в X вместо y.
'centroid' и 'median' методы могут произвести кластерное дерево, которое не является монотонным. Этот результат происходит, когда расстояние от объединения двух кластеров, r и s, к третьему кластеру меньше расстояния между r и s. В этом случае, в древовидной схеме, чертившей с ориентацией по умолчанию, путь от листа до корневого узла делает некоторые нисходящие шаги. Чтобы избежать этого результата, используйте другой метод. Этот рисунок показывает немонотонное кластерное дерево.
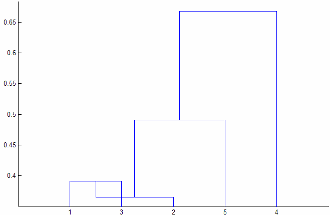
В этом случае к кластеру 1 и кластеру 3 соединяют в новый кластер, и расстояние между этим новым кластером и кластером 2 меньше расстояния между кластером 1 и кластером 3. Результатом является немонотонное дерево.
Можно обеспечить выход Z к другим функциям включая dendrogram отобразить дерево, cluster присваивать точки кластерам, inconsistent вычислить противоречивые меры и cophenet вычислить cophenetic коэффициент корреляции.
cluster | clusterdata | cophenet | dendrogram | inconsistent | kmeans | pdist | silhouette | squareform
