

Разработка аудиоприложений с глубоким обучением обычно включает создание и доступ к наборам данных, предварительную обработку и исследование данных, разработку прогнозных моделей, и развертывание и совместное использование приложений. MATLAB® обеспечивает тулбоксы, чтобы поддержать каждый этап разработки.

В то время как Audio Toolbox™ поддерживает каждый этап рабочего процесса глубокого обучения, его основные вклады к доступу и Создают Данные и Предварительно обрабатывают и Исследуют Данные.
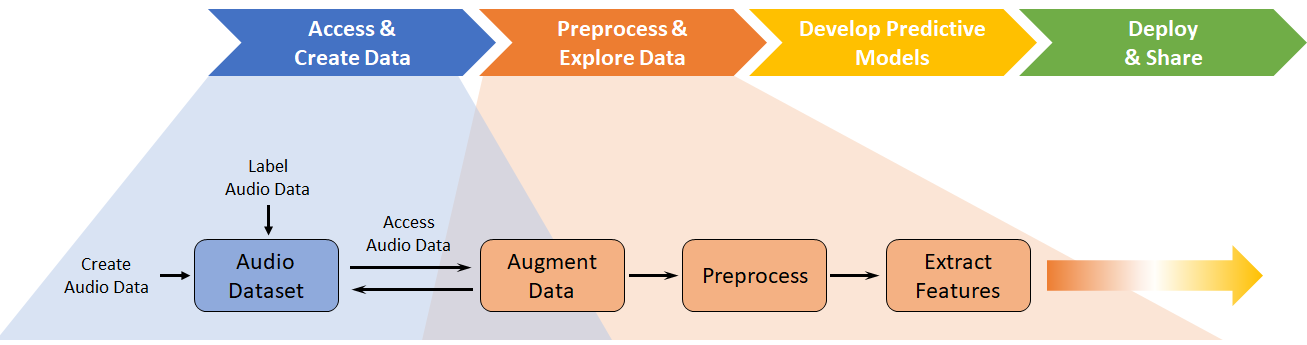
Нейронные сети для глубокого обучения выполняют лучше всего, когда у вас есть доступ к большим обучающим наборам данных. Однако разнообразие аудио, речи, и акустических сигналов, и отсутствия больших наборов хорошо-маркированных-данных, делает получающие доступ большие наборы обучающих данных трудными. При использовании методов глубокого обучения на звуковых файлах вы, возможно, должны разработать новые наборы данных или подробно остановиться на существующих единицах. Audio Toolbox предоставляет приложение Audio Labeler, чтобы помочь вам увеличить или создать новые наборы маркированных данных.
Если у вас есть набор исходных данных, можно увеличить его путем применения методов увеличения, таких как перемена подачи, смещение во времени, регулятор громкости и шумовое сложение. Тип увеличения, которое вы хотите применить, зависит от соответствующих характеристик для вашего аудио, речи или акустического приложения. Например, передайте перемену (или возмущение речевого тракта), и время, простираясь типичные методы увеличения для автоматического распознавания речи (ASR). Для далекого поля ASR увеличение обучающих данных при помощи искусственной реверберации распространено. Audio Toolbox обеспечивает audioDataAugmenter помочь вам применить увеличения детерминировано или вероятностно.
Обучающие данные, используемые в рабочих процессах глубокого обучения, являются обычно слишком большими, чтобы уместиться в памяти. Доступ к данным эффективно и выполнение общих задач глубокого обучения (таких как разделение набора данных в обучаются, валидация и наборы тестов) могут быстро стать неуправляемыми. Audio Toolbox обеспечивает audioDatastore помочь вам управлять и загрузить большие наборы данных.
Предварительная обработка аудиоданных включает задачи как передискретизация звуковых файлов к сопоставимой частоте дискретизации, удаление областей тишины и обрезки аудио к сопоставимой длительности. Можно выполнить эти задачи при помощи MATLAB, Signal Processing Toolbox™ и DSP System Toolbox™. Audio Toolbox обеспечивает дополнительные аудио специфичные инструменты, чтобы помочь вам выполнить предварительную обработку, такой как detectSpeech и voiceActivityDetector.
Аудио является очень размерным и содержит избыточную и часто ненужную информацию. Исторически, mel-частота cepstral коэффициенты (mfcc) и низкоуровневыми функциями, такими как уровень пересечения нулем и спектральные дескрипторы формы, были доминирующие функции, выведенные из звуковых сигналов для использования в системах машинного обучения. Системы машинного обучения, обученные на этих функциях, в вычислительном отношении эффективны и обычно требуют меньшего количества обучающих данных. Audio Toolbox обеспечивает audioFeatureExtractor так, чтобы можно было эффективно извлечь функции аудио.
Усовершенствования в архитектурах глубокого обучения, увеличенном доступе к вычислительной мощности, и большой и наборы хорошо-маркированных-данных уменьшили уверенность в спроектированных рукой функциях. Современные результаты часто достигаются с помощью mel спектрограммы (melSpectrogram), линейные спектрограммы или необработанные аудио формы волны. Audio Toolbox обеспечивает audioFeatureExtractor так, чтобы можно было извлечь несколько слуховых спектрограмм, таких как mel спектрограмма, gammatone спектрограмма или спектрограмма Коры, и соединить их с низкоуровневыми дескрипторами. Используя audioFeatureExtractor позволяет вам систематически определить функции аудио для своей модели глубокого обучения. В качестве альтернативы можно использовать melSpectrogram функционируйте, чтобы быстро извлечь только mel спектрограмму. Audio Toolbox также обеспечивает модифицированное дискретное косинусное преобразование (mdct), который возвращает компактное спектральное представление без любой потери информации.
Выбирание признаков, решение, какие увеличения и предварительно обрабатывающий, чтобы применяться, и проектирующий модель глубокого обучения все зависят от природы обучающих данных и задачи, которую вы хотите решить. Audio Toolbox обеспечивает примеры, которые иллюстрируют рабочие процессы глубокого обучения, адаптированные к различным наборам данных и аудиоприложениям. Таблица приводит аудио примеры глубокого обучения сетевым типом (сверточная нейронная сеть, полностью соединенная нейронная сеть или рекуррентная нейронная сеть) и проблемная категория (классификация, регрессия или от последовательности к последовательности).
CNN или FC | LSTM или BiLSTM | ||||||||||||||||||||||
Классификация |
|
| |||||||||||||||||||||
Регрессия или от последовательности к последовательности |
|
|
[1] Purwins, H., Б. Ли, Т. Виртэнен, Дж. Шюлтер, С. И. Чанг и Т. Сэйнэт. "Глубокое обучение для Обработки Звукового сигнала". Журнал Выбранных Тем Обработки сигналов. Издание 13, Выпуск 2, 2019, стр 206–219.
Audio Labeler | audioDataAugmenter | audioDatastore | audioFeatureExtractor