Визуализируйте итоговую статистику с диаграммой
boxplot( создает диаграмму данных в x)x. Если x вектор, boxplot графики одно поле. Если x матрица, boxplot графики одно поле для каждого столбца x.
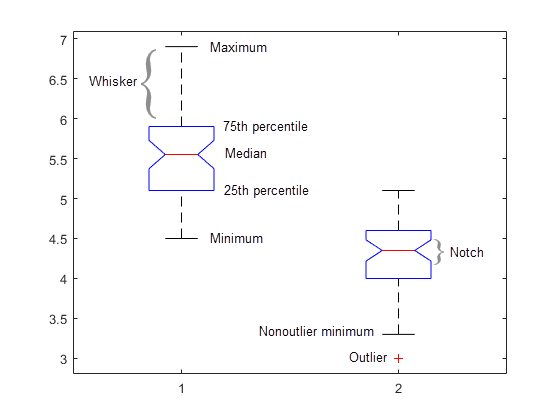
На каждом поле центральная метка указывает на медиану, и нижняя часть и верхние края поля указывают на 25-е и 75-е процентили, соответственно. Контактные усики расширяют к самым экстремальным точкам данных, не рассмотренным выбросами, и выбросы построены индивидуально с помощью '+' символ.
boxplot( создает диаграмму с помощью осей, заданных графическим объектом осей ax,___)ax, использование любого из предыдущих синтаксисов.
boxplot(___, создает диаграмму с дополнительными опциями, заданными одним или несколькими Name,Value)Name,Value парные аргументы. Например, можно задать стиль поля или порядок.
Загрузите выборочные данные.
load carsmallСоздайте диаграмму миль на галлон (MPG) измерения. Добавьте заголовок и подпишите оси.
boxplot(MPG) xlabel('All Vehicles') ylabel('Miles per Gallon (MPG)') title('Miles per Gallon for All Vehicles')

Коробчатая диаграмма показывает, что средние мили на галлон для всех транспортных средств в выборочных данных - приблизительно 24. Минимальное значение - приблизительно 9, и максимальное значение - приблизительно 44.
Загрузите выборочные данные.
load carsmallСоздайте диаграмму миль на галлон (MPG) измерения от выборочных данных, сгруппированных страной происхождения транспортных средств (Origin). Добавьте заголовок и подпишите оси.
boxplot(MPG,Origin) title('Miles per Gallon by Vehicle Origin') xlabel('Country of Origin') ylabel('Miles per Gallon (MPG)')

Каждое поле визуально представляет данные о MPG для автомобилей из заданной страны. "Поле" Италии появляется как одна строка, потому что выборочные данные содержат только одно наблюдение для этой группы.
Сгенерируйте два набора выборочных данных. Первая выборка, x1, содержит случайные числа, сгенерированные от нормального распределения с mu = 5 и sigma = 1. Вторая выборка, x2, содержит случайные числа, сгенерированные от нормального распределения с mu = 6 и sigma = 1.
rng default % For reproducibility x1 = normrnd(5,1,100,1); x2 = normrnd(6,1,100,1);
Создайте отмеченные диаграммы x1 и x2. Пометьте каждое поле его соответствующим mu значение.
figure boxplot([x1,x2],'Notch','on','Labels',{'mu = 5','mu = 6'}) title('Compare Random Data from Different Distributions')

Коробчатая диаграмма показывает, что различие между медианами этих двух групп - приблизительно 1. Поскольку метки в диаграмме не перекрываются, можно прийти к заключению с 95%-м доверием, что истинные медианы действительно отличаются.
Следующий рисунок показывает диаграмму для тех же данных с максимальной длиной контактного усика, заданной как 1.0 раза межквартильный размах. Точки данных вне контактных усиков отображены с помощью +.
figure boxplot([x1,x2],'Notch','on','Labels',{'mu = 5','mu = 6'},'Whisker',1) title('Compare Random Data from Different Distributions')

С контактными усиками меньшего размера, boxplot отображения больше точек данных как выбросы.
Создайте 100 25 матрица случайных чисел, сгенерированных от стандартного нормального распределения, чтобы использовать в качестве выборочных данных.
rng default % For reproducibility x = randn(100,25);
Создайте две диаграммы для данных в x на той же фигуре. Используйте форматирование значения по умолчанию для главного графика и компактное форматирование для нижнего графика.
figure subplot(2,1,1) boxplot(x) subplot(2,1,2) boxplot(x,'PlotStyle','compact')

Каждый график представляет те же данные, но компактное форматирование может улучшить удобочитаемость для графиков со многими полями.
Создайте диаграммы для векторов данных различной длины при помощи сгруппированной переменной.
Случайным образом сгенерируйте три вектор-столбца различной длины: одна из длины 5, одна из длины 10, и одна из длины 15. Объедините данные в вектор отдельного столбца из длины 30.
rng('default') % For reproducibility x1 = rand(5,1); x2 = rand(10,1); x3 = rand(15,1); x = [x1; x2; x3];
Создайте сгруппированную переменную, которая присваивает то же значение строкам, которые соответствуют тому же вектору в x. Например, первые пять строк g имейте то же значение, First, потому что первые пять строк x все прибывают из того же вектора, x1.
g1 = repmat({'First'},5,1);
g2 = repmat({'Second'},10,1);
g3 = repmat({'Third'},15,1);
g = [g1; g2; g3];Создайте диаграммы.
boxplot(x,g)

Диаграмма обеспечивает визуализацию итоговой статистики для выборочных данных и содержит следующие функции:
Нижняя часть и верхняя часть каждого поля являются 25-ми и 75-ми процентилями выборки, соответственно. Расстояние между нижней частью и верхней частью каждого поля является межквартильным размахом.
Красная линия посреди каждого поля является демонстрационной медианой. Если медиана не сосредоточена в поле, график показывает демонстрационную скошенность.
Контактные усики являются расширением линий выше и ниже каждого поля. Контактные усики идут от конца межквартильного размаха к самому далекому наблюдению в длине контактного усика (смежное значение).
Наблюдения вне длины контактного усика отмечены как выбросы. По умолчанию выброс является значением, которое является больше чем 1,5 раза межквартильным размахом далеко от нижней части или верхней части поля. Однако можно настроить это значение при помощи дополнительных входных параметров. Выброс появляется как красный + знак.
Метки отображают изменчивость медианы между выборками. Ширина метки вычисляется так, чтобы поля, метки которых не перекрываются, имели различные медианы на 5%-м уровне значения. Уровень значения основан на предположении нормального распределения, но сравнения медиан довольно устойчивы для других распределений. Сравнение медиан диаграммы похоже на визуальный тест гипотезы, аналогичный тесту t, используемому для средних значений.
boxplot создает визуальное представление данных, но не возвращает числовые значения. Чтобы вычислить соответствующую итоговую статистику для выборочных данных, используйте следующие функции:
min — Найдите минимальное значение в выборочных данных.
max — Найдите максимальное значение в выборочных данных.
median — Найдите среднее значение в выборочных данных.
quantile — Найдите значения квантиля в выборочных данных. Например, чтобы вычислить 25-е и 75-е процентили x, задайте quantile(x,[0.25 0.75]). Для получения дополнительной информации о том, как процентили вычисляются, видят Алгоритмы.
iqr — Найдите межквартильный размах в выборочных данных.
grpstats — Вычислите итоговую статистику для выборочных данных, организованных группой.
Вы видите значения данных и названия группы с помощью Data Cursor в окне рисунка. Курсор показывает исходные значения любых точек, затронутых datalim параметр. Можно пометить группу, для которой выброс принадлежит с помощью gname функция.
Чтобы изменить графические свойства компонента диаграммы, использовать findobj с Tag свойство найти указатель компонента. Tag значения для компонентов диаграммы зависят от установок параметров и перечислены в следующей таблице.
| Установки параметров | Пометьте значения |
|---|---|
| Все настройки |
|
Когда 'PlotStyle' 'traditional' |
|
Когда 'PlotStyle' 'compact' |
|
Когда 'Notch' 'marker' |
|
Можно также создать BoxChart объект при помощи boxchart функция. Несмотря на то, что boxchart не включает всю функциональность boxplot, это имеет некоторые преимущества. В отличие от этого, boxplot, boxchart функция:
Допускает категориальные линейки вдоль оси группы
Предоставляет возможность легенды
Работы хорошо с hold on команда
Имеет улучшенное визуальное проектирование, которое помогает вам видеть метки более легко
Чтобы управлять внешним видом и поведением объекта, измените BoxChart Properties.
[1] Макгилл, R., Дж. В. Туки и В. А. Ларсен. “Изменения Коробчатых диаграмм”. Американский Статистик. Издание 32, № 1, 1978, стр 12–16.
[2] Веллемен, P.F., и Hoaglin округа Колумбия. Приложения, основы и вычисление исследовательского анализа данных. Пасифик-Гроув, CA: нажатие Даксбери, 1981.
[3] Нельсон, L. S. “Оценивая Перекрывающиеся Доверительные интервалы”. Журнал Качественной Технологии. Издание 21, 1989, стр 140–141.
[4] Лэнгфорд, E. “Квартили в элементарной статистике”, журнал образования статистики. Издание 14, № 3, 2006.
anova1 | grpstats | kruskalwallis | max | median | min | multcompare | quantile
