Классификация звуков в звуковом сигнале
sounds = classifySound(audioIn,fs,Name,Value)Name,Value аргументы пары.
sounds = classifySound(audioIn,fs,'SpecificityLevel','low') классифицирует звуки, используя низкую специфичность.[ также возвращает временные метки, связанные с каждым обнаруженным звуком.sounds,timestamps] = classifySound(___)
[ также возвращает таблицу, содержащую сведения о результатах.sounds,timestamps,resultsTable] = classifySound(___)
classifySound(___) без выходных аргументов создает облако слов идентифицированных звуков в звуковом сигнале.
Эта функция требует как Toolbox™ аудио, так и Deep Learning Toolbox™.
classifySoundЗагрузите и распакуйте поддержку Audio Toolbox™ для YAMNet.
Если поддержка Audio Toolbox для YAMNet не установлена, то первый вызов функции предоставляет ссылку на место загрузки. Чтобы загрузить модель, щелкните ссылку. Распакуйте файл в папку по пути MATLAB.
Либо выполните следующие команды для загрузки и распаковки модели YAMNet во временную папку.
downloadFolder = fullfile(tempdir,'YAMNetDownload'); loc = websave(downloadFolder,'https://ssd.mathworks.com/supportfiles/audio/yamnet.zip'); YAMNetLocation = tempdir; unzip(loc,YAMNetLocation) addpath(fullfile(YAMNetLocation,'yamnet'))
Создайте 1 секунду розового шума, предполагая частоту дискретизации 16 кГц.
fs = 16e3; x = pinknoise(fs);
Звонить classifySound с сигналом розового шума и частотой дискретизации.
identifiedSound = classifySound(x,fs)
identifiedSound = "Pink noise"
Считывание звукового сигнала. Звонить classifySound для возврата обнаруженных звуков и соответствующих временных отметок.
[audioIn,fs] = audioread('multipleSounds-16-16-mono-18secs.wav');
[sounds,timeStamps] = classifySound(audioIn,fs);Постройте график звукового сигнала и пометьте обнаруженные звуковые области.
t = (0:numel(audioIn)-1)/fs; plot(t,audioIn) xlabel('Time (s)') axis([t(1),t(end),-1,1]) textHeight = 1.1; for idx = 1:numel(sounds) patch([timeStamps(idx,1),timeStamps(idx,1),timeStamps(idx,2),timeStamps(idx,2)], ... [-1,1,1,-1], ... [0.3010 0.7450 0.9330], ... 'FaceAlpha',0.2); text(timeStamps(idx,1),textHeight+0.05*(-1)^idx,sounds(idx)) end

Выберите область и прослушивайте только выбранную область.
sampleStamps = floor(timeStamps*fs)+1; soundEvent =3; isolatedSoundEvent = audioIn(sampleStamps(soundEvent,1):sampleStamps(soundEvent,2)); sound(isolatedSoundEvent,fs); display('Detected Sound = ' + sounds(soundEvent))
"Detected Sound = Snoring"
Считывание звукового сигнала, содержащего несколько различных звуковых событий.
[audioIn,fs] = audioread('multipleSounds-16-16-mono-18secs.wav');Звонить classifySound с аудиосигналом и частотой дискретизации.
[sounds,~,soundTable] = classifySound(audioIn,fs);
sounds строковый массив содержит наиболее вероятное звуковое событие в каждой области.
sounds
sounds = 1×5 string
"Stream" "Machine gun" "Snoring" "Bark" "Meow"
soundTable содержит подробную информацию относительно звуков, обнаруженных в каждой области, включая оценочные средства и максимумы по анализируемому сигналу.
soundTable
soundTable=5×2 table
TimeStamps Results
________________ ___________
0 3.92 {4×3 table}
4.0425 6.0025 {3×3 table}
6.86 9.1875 {2×3 table}
10.658 12.373 {4×3 table}
12.985 16.66 {4×3 table}
Просмотр последней обнаруженной области.
soundTable.Results{end}ans=4×3 table
Sounds AverageScores MaxScores
________________________ _____________ _________
"Animal" 0.79514 0.99941
"Domestic animals, pets" 0.80243 0.99831
"Cat" 0.8048 0.99046
"Meow" 0.6342 0.90177
Звонить classifySound снова. На этот раз, набор IncludedSounds кому Animal чтобы функция сохраняла только области, в которых Animal обнаружен класс звука.
[sounds,timeStamps,soundTable] = classifySound(audioIn,fs, ... 'IncludedSounds','Animal');
Массив звуков возвращает только звуки, указанные как включенные звуки. sounds теперь массив содержит два экземпляра Animal которые соответствуют регионам, объявленным как Bark и Meow ранее.
sounds
sounds = 1×2 string
"Animal" "Animal"
Таблица звука включает только области, в которых были обнаружены указанные классы звука.
soundTable
soundTable=2×2 table
TimeStamps Results
________________ ___________
10.658 12.373 {4×3 table}
12.985 16.66 {4×3 table}
Просмотр последней обнаруженной области в soundTable. Таблица результатов по-прежнему включает статистику по всем обнаруженным звукам в регионе.
soundTable.Results{end}ans=4×3 table
Sounds AverageScores MaxScores
________________________ _____________ _________
"Animal" 0.79514 0.99941
"Domestic animals, pets" 0.80243 0.99831
"Cat" 0.8048 0.99046
"Meow" 0.6342 0.90177
Чтобы изучить, какие классы звука поддерживаются classifySound, использовать yamnetGraph.
Считывание звукового сигнала и вызов classifySound для проверки наиболее вероятных звуков, расположенных в хронологическом порядке обнаружения.
[audioIn,fs] = audioread("multipleSounds-16-16-mono-18secs.wav");
sounds = classifySound(audioIn,fs)sounds = 1×5 string
"Stream" "Machine gun" "Snoring" "Bark" "Meow"
Звонить classifySound снова и установить ExcludedSounds кому Meow чтобы исключить звук Meow по результатам. Сегмент, ранее классифицированный как Meow теперь классифицируется как Cat, который является его непосредственным предшественником в онтологии AudioSet.
sounds = classifySound(audioIn,fs,"ExcludedSounds","Meow")
sounds = 1×5 string
"Stream" "Machine gun" "Snoring" "Bark" "Cat"
Звонить classifySound снова и установить ExcludedSounds кому Cat. При исключении звука также исключаются все преемники. Это означает, что исключение звука Cat также исключает звук Meow. Сегмент, первоначально классифицированный как Meow теперь классифицируется как Domestic animals, pets, который является непосредственным предшественником Cat в онтологии AudioSet.
sounds = classifySound(audioIn,fs,"ExcludedSounds","Cat")
sounds = 1×5 string
"Stream" "Machine gun" "Snoring" "Bark" "Domestic animals, pets"
Звонить classifySound снова и установить ExcludedSounds кому Domestic animals, pets. Класс звука, Domestic animals, pets является предшественником обоих Bark и Meow, поэтому, исключив его, звуки, ранее идентифицированные как Bark и Meow теперь оба идентифицированы как предшественник Domestic animals, pets, что является Animal.
sounds = classifySound(audioIn,fs,"ExcludedSounds","Domestic animals, pets")
sounds = 1×5 string
"Stream" "Machine gun" "Snoring" "Animal" "Animal"
Звонить classifySound снова и установить ExcludedSounds кому Animal. Класс звука Animal не имеет предшественников.
sounds = classifySound(audioIn,fs,"ExcludedSounds","Animal")
sounds = 1×3 string
"Stream" "Machine gun" "Snoring"
Если вы хотите избежать обнаружения Meow и его предшественники, но продолжайте обнаруживать преемников при тех же предшественниках, используйте IncludedSounds вариант. Звонить yamnetGraph для получения списка всех поддерживаемых классов. Удалить Meow и его предшественники из массива всех классов, а затем вызвать classifySound снова.
[~,classes] = yamnetGraph; classesToInclude = setxor(classes,["Meow","Cat","Domestic animals, pets","Animal"]); sounds = classifySound(audioIn,fs,"IncludedSounds",classesToInclude)
sounds = 1×4 string
"Stream" "Machine gun" "Snoring" "Bark"
Считывайте звуковой сигнал и слушайте его.
[audioIn,fs] = audioread('multipleSounds-16-16-mono-18secs.wav');
sound(audioIn,fs)Звонить classifySound без выходных аргументов для создания облака слов обнаруженных звуков.
classifySound(audioIn,fs);

Изменение параметров по умолчанию classifySound для изучения влияния на облако слов.
threshold =0.1; minimumSoundSeparation =
0.92; minimumSoundDuration =
1.02; classifySound(audioIn,fs, ... 'Threshold',threshold, ... 'MinimumSoundSeparation',minimumSoundSeparation, ... 'MinimumSoundDuration',minimumSoundDuration);

classifySound функция использует YAMNet для классификации аудиосегментов в классы звука, описанные в онтологии AudioSet. classifySound функция предварительно обрабатывает звук так, чтобы он был в формате, требуемом для YAMNet, и выполняет постобработку прогнозов YAMNet общими задачами, которые делают результаты более интерпретируемыми.
Пропускают каждый из 521 доверительных сигналов через подвижный средний фильтр с длиной окна 7.
Пропускают каждый из сигналов через движущийся медианный фильтр с длиной окна 3.
Преобразование доверительных сигналов в двоичные маски с использованием указанного Threshold.
Отбрасывать любой звук короче, чем MinimumSoundDuration.
Объединить области, которые ближе, чем MinimumSoundSeparation.
Консолидация выявленных звуковых областей, перекрывающихся на 50% или более, в отдельные области. Время начала региона - наименьшее время начала всех звуков в группе. Время окончания области - наибольшее время окончания всех звуков в группе. Функция возвращает временные метки, классы звуков и среднее и максимальное доверие классов звука в пределах области в resultsTable.
Уровень специфичности классификации звука можно задать с помощью SpecificityLevel вариант. Например, предположим, что есть четыре класса звука в звуковой группе со следующими соответствующими средними баллами по звуковой области:
Water –– 0.82817
Stream –– 0.81266
Trickle, dribble –– 0.23102
Pour –– 0.20732
Классы звука, Water, Stream, Trickle, dribble, и Pour расположены в онтологии AudioSet, как показано графиком:
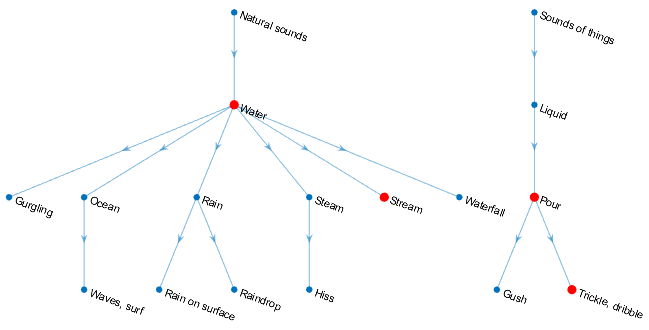
Функции возвращают класс звука для группы звука в sounds выходной аргумент в зависимости от SpecificityLevel:
"high" (по умолчанию) - В этом режиме Stream является предпочтительным для Water, и Trickle, dribble является предпочтительным для Pour. Stream имеет более высокий средний балл по региону, поэтому функция возвращается Stream в sounds выходные данные для региона.
"low" - В этом режиме возвращается самая общая онтологическая категория для класса звука с самой высокой средней уверенностью по региону. Для Trickle, dribble и Pour, наиболее общей категорией является Sounds of things. Для Stream и Water, наиболее общей категорией является Natural sounds. Поскольку Water имеет самую высокую среднюю достоверность по звуковой области, функция возвращается Natural sounds.
"none" - В этом режиме функция возвращает класс звука с наивысшим средним показателем достоверности, который в данном примере Water.
[1] Gemmeke, Джорт Ф., и др. 2017 IEEE Международная конференция по акустике, обработке речи и сигналов (ICASSP), IEEE, 2017, стр. 776-80. DOI.org (Crossref), doi:10.1109/ICASSP.2017.7952261.
[2] Херши, Шон и др. Международная конференция IEEE 2017 по акустике, обработке речи и сигналов (ICASSP), IEEE, 2017, стр. 131-35. DOI.org (Crossref), doi:10.1109/ICASSP.2017.7952132.
Аудиомаркировщик | vggish | vggishFeatures | yamnet | yamnetGraph
