Нейроны в конкурентном слое распределяются для распознавания часто представленных входных векторов.
Архитектура конкурентной сети показана ниже.
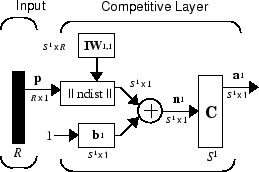
‖ dist ‖ поле на этом рисунке принимает входной вектор p и входную весовую матрицу IW1,1 и создает вектор, имеющий S1 элементы. Элементы являются отрицательными расстояниями между входным вектором и векторами iIW1,1 образованными из строк входной весовой матрицы.
Вычислите суммарный вход n1 конкурентного слоя, найдя отрицательное расстояние между входным вектором p и весовыми векторами и добавив смещения b. Если все смещения равны нулю, максимальный сетевой вход, который может иметь нейрон, равен 0. Это происходит, когда входной вектор p равен вектору веса нейрона.
Функция конкурентного переноса принимает чистый входной вектор для слоя и возвращает выходы нейронов 0 для всех нейронов, кроме победителя, нейрона, связанного с наиболее положительным элементом сетевого входа n1. Выход победителя - 1. Если все смещения равны 0, то нейрон, чей весовой вектор ближе всего к входному вектору, имеет наименьший отрицательный чистый вход и, следовательно, выигрывает конкуренцию за выход 1.
Причины использования смещений с конкурентными слоями представлены в правиле обучения смещению (learncon).
С помощью функции можно создать конкурентную нейронную сеть competlayer. Простой пример показывает, как это работает.
Предположим, что необходимо разделить следующие четыре двухэлементных вектора на два класса.
p = [.1 .8 .1 .9; .2 .9 .1 .8]
p =
0.1000 0.8000 0.1000 0.9000
0.2000 0.9000 0.1000 0.8000
Существует два вектора рядом с началом координат и два вектора рядом (1,1).
Сначала создайте двухнейронный конкурентный слой.:
net = competlayer(2);
Теперь у вас есть сеть, но вам нужно обучить ее выполнять классификационное задание.
При первом обучении сети ее веса инициализируются в центры входных диапазонов с помощью функции. midpoint. Вы можете проверить эти начальные значения, используя количество нейронов и входные данные:
wts = midpoint(2,p)
wts =
0.5000 0.5000
0.5000 0.5000
Эти веса действительно являются значениями в средней точке диапазона (от 0 до 1) входных данных.
Первоначальные смещения вычисляются с помощью initcon, что дает
biases = initcon(2)
biases =
5.4366
5.4366
Напомним, что каждый нейрон конкурирует, чтобы ответить на входной вектор р. Если все смещения равны 0, нейрон, чей весовой вектор ближе всего к p, получает самый высокий чистый вход и, следовательно, выигрывает конкуренцию, и выводит 1. Все остальные нейроны выводят 0. Вы хотите настроить нейрон выигрыша так, чтобы переместить его ближе к входу. Правило обучения для этого обсуждается в следующем разделе.
Веса нейрона-победителя (ряд матрицы входного веса) корректируются с помощью правила обучения Кохонена. Предполагая, что выигрывает i-й нейрон, элементы i-й строки матрицы входного веса корректируются, как показано ниже.
IiW1,1 (q − 1))
Правило Кохонена позволяет весам нейрона обучаться входному вектору, и из-за этого оно полезно в приложениях распознавания.
Таким образом, нейрон, весовой вектор которого был ближе всего к входному вектору, обновляется, чтобы быть еще ближе. В результате выигрышный нейрон с большей вероятностью выиграет соревнование в следующий раз, когда будет представлен аналогичный вектор, и с меньшей вероятностью выиграет, когда будет представлен очень другой входной вектор. По мере того, как появляется все больше и больше входов, каждый нейрон в слое, ближайшем к группе входных векторов, вскоре корректирует свой весовой вектор в сторону этих входных векторов. В конечном счете, если нейронов достаточно, каждый кластер аналогичных входных векторов будет иметь нейрон, который выводит 1, когда представлен вектор в кластере, при этом выводя 0 в любое другое время. Таким образом, конкурентная сеть учится классифицировать входные векторы, которые она видит.
Функция learnk используется для выполнения правила обучения Кохонена в этой панели инструментов.
Одним из ограничений конкурентных сетей является то, что некоторые нейроны не всегда могут быть распределены. Другими словами, некоторые векторы веса нейронов могут начинаться далеко от любых входных векторов и никогда не выигрывать конкуренцию, независимо от того, как долго продолжается тренировка. В результате их веса не получают учиться и они никогда не побеждают. Эти несчастные нейроны, называемые мертвыми нейронами, никогда не выполняют полезную функцию.
Чтобы остановить это, используйте предубеждения, чтобы дать нейронам, которые только выигрывают конкуренцию, редко (если когда-либо) преимущество перед нейронами, которые выигрывают часто. Положительное смещение, добавленное к отрицательному расстоянию, делает отдаленный нейрон более вероятным для победы.
Для выполнения этой работы сохраняется среднее количество выходов нейронов. Это эквивалентно процентам раз, когда каждый выход равен 1. Это среднее используется для обновления отклонений с помощью функции обучения learncon так что смещения часто активных нейронов становятся меньше, а смещения редко активных нейронов становятся больше.
По мере увеличения смещений нечасто активных нейронов увеличивается входное пространство, на которое эти нейроны реагируют. По мере увеличения этого входного пространства нечасто активный нейрон реагирует и движется к большему количеству входных векторов. В конце концов, нейрон реагирует на то же количество векторов, что и другие нейроны.
Это имеет два хороших эффекта. Во-первых, если нейрон никогда не выигрывает конкуренцию, потому что его веса далеки от любого из входных векторов, его смещение в конечном итоге становится достаточно большим, чтобы он мог выиграть. Когда это происходит, он перемещается к некоторой группе входных векторов. Как только веса нейрона перейдут в группу входных векторов, и нейрон последовательно победит, его смещение уменьшится до 0. Таким образом решается проблема мертвых нейронов.
Второе преимущество смещений заключается в том, что они заставляют каждый нейрон классифицировать примерно одинаковый процент входных векторов. Таким образом, если область входного пространства связана с большим числом входных векторов, чем другая область, более плотно заполненная область привлечет больше нейронов и будет классифицирована на меньшие подсекции.
Показатели обучения для learncon обычно устанавливаются на порядок или больше, чем для learnk для проверки точности среднего значения.
Теперь тренируйте сеть на 500 эпох. Вы можете использовать либо train или adapt.
net.trainParam.epochs = 500; net = train(net,p);
Обратите внимание, что train для конкурентных сетей использует функцию обучения trainru. Это можно проверить, выполнив следующий код после создания сети.
net.trainFcn
ans = trainru
Для каждой эпохи все обучающие векторы (или последовательности) представлены один раз в другом случайном порядке с сетью и значениями веса и смещения, обновленными после каждого отдельного представления.
Затем введите исходные векторы в качестве входных данных в сеть, смоделируйте сеть и, наконец, преобразуйте ее выходные векторы в индексы классов.
a = sim(net,p); ac = vec2ind(a)
ac =
1 2 1 2
Вы видите, что сеть обучена классифицировать входные векторы на две группы: близкие к началу координат, класс 1, и близкие (1,1), класс 2.
Может быть интересно посмотреть на окончательный вес и предубеждения.
net.IW{1,1}ans =
0.1000 0.1500
0.8500 0.8500net.b{1}ans =
5.4367
5.4365 (При выполнении этой задачи могут быть получены различные ответы, поскольку для выбора порядка векторов, представленных сети для обучения, используется случайное начальное число.) Отметим, что первый вектор (сформированный из первой строки весовой матрицы) находится вблизи входных векторов, близких к началу координат, в то время как вектор, сформированный из второй строки весовой матрицы, близок к входным векторам, близким к (1,1). Таким образом, сеть была обучена - просто подвергая ее входам - их классификации.
Во время тренировки каждый нейрон в слое, ближайшем к группе входных векторов, настраивает свой весовой вектор в сторону этих входных векторов. В конце концов, если нейронов достаточно, каждый кластер подобных входных векторов имеет нейрон, который выводит 1, когда представлен вектор в кластере, при этом выводя 0 в любое другое время. Таким образом, конкурентная сеть учится классифицировать входные данные.
Конкурентные слои могут быть лучше поняты, когда их весовые векторы и входные векторы показаны графически. На диаграмме ниже показаны 48 двухэлементных входных векторов, представленных + маркеры.
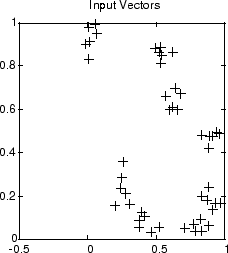
Входные векторы, приведенные выше, по-видимому, попадают в кластеры. Вы можете использовать конкурентную сеть из восьми нейронов для классификации векторов в такие кластеры.
Попробуйте конкурентоспособное обучение, чтобы увидеть динамичный пример конкурентного обучения.
