В этом примере показано, как преобразовать алгоритм с плавающей запятой в фиксированную точку, а затем создать код C для алгоритма. В примере используются следующие передовые практики:
Отделите алгоритм от тестового файла.
Подготовьте свой алгоритм для создания контрольно-измерительных приборов и кода.
Управление типами данных и рост битов.
Отделите определения типов данных от алгоритмического кода, создав таблицу определений данных.
Полный список рекомендаций см. в разделе Рекомендации по преобразованию фиксированных точек вручную.
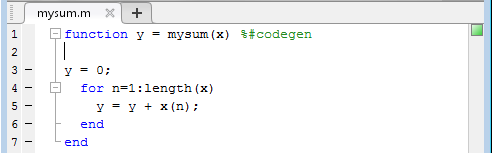
Напишите функцию MATLAB ® ,mysum, что суммирует элементы вектора.
function y = mysum(x) y = 0; for n = 1:length(x) y = y + x(n); end end
Поскольку требуется только преобразовать алгоритмическую часть в фиксированную точку, более эффективно структурировать код так, чтобы алгоритм, в котором выполняется обработка ядра, был отделен от тестового файла.
В тестовом файле создайте входные данные, вызовите алгоритм и постройте график результатов.
Напишите сценарий MATLAB, mysum_test, что проверяет поведение алгоритма с использованием двойных типов данных.
n = 10; rng default x = 2*rand(n,1)-1; % Algorithm y = mysum(x); % Verify results y_expected = sum(double(x)); err = double(y) - y_expected
rng default помещает настройки генератора случайных чисел, используемого функцией rand, в значение по умолчанию, так что он создает те же случайные числа, что и при перезапуске MATLAB.
Запустите тестовый сценарий.
mysum_test
err =
0Результаты, полученные с использованием mysum соответствуют полученным с помощью MATLAB sum функция.
Дополнительные сведения см. в разделе Создание тестового файла.
В алгоритме после подписи функции добавьте %#codegen директива компиляции, указывающая на то, что вы намереваетесь внедрить алгоритм и сгенерировать для него код C. Добавление этой директивы предписывает анализатору кода MATLAB помочь в диагностике и устранении нарушений, которые могут привести к ошибкам при создании кода и контрольно-измерительных приборов.
function y = mysum(x) %#codegen y = 0; for n = 1:length(x) y = y + x(n); end end
Для этого алгоритма индикатор анализатора кода в правом верхнем углу окна редактора остается зеленым, указывая, что он не обнаружил никаких проблем.
Дополнительные сведения см. в разделе Подготовка алгоритма для ускорения кода или создания кода.
Создайте код C для исходного алгоритма, чтобы убедиться, что алгоритм подходит для генерации кода и увидеть код C с плавающей запятой. Используйте codegen Функция (MATLAB Coder) (требует MATLAB Coder™) для создания библиотеки C.
Добавьте следующую строку в конец тестового сценария, чтобы создать код C для mysum.
codegen mysum -args {x} -config:lib -report
Запустите сценарий теста еще раз.
Кодер MATLAB генерирует код C для mysum и предоставляет ссылку на отчет о создании кода.
Щелкните ссылку, чтобы открыть отчет о создании кода и просмотреть созданный код C для mysum.
/* Function Definitions */
double mysum(const double x[10])
{
double y;
int n;
y = 0.0;
for (n = 0; n < 10; n++) {
y += x[n];
}
return y;
}Поскольку C не позволяет использовать индексы с плавающей запятой, счетчик цикла, n, автоматически объявляется как целочисленный тип. Преобразование не требуется n в фиксированную точку.
Вход x и выходные данные y объявлены как двойные.
Протестируйте свой алгоритм с помощью синглов для проверки несовпадений типов
Измените тестовый файл таким образом, чтобы тип данных x одинарный.
n = 10; rng default x = single(2*rand(n,1)-1); % Algorithm y = mysum(x); % Verify results y_expected = sum(double(x)); err = double(y) - y_expected codegen mysum -args {x} -config:lib -report
Запустите сценарий теста еще раз.
mysum_test
err = -4.4703e-08 ??? This assignment writes a 'single' value into a 'double' type. Code generation does not support changing types through assignment. Check preceding assignments or input type specifications for type mismatches.
Ошибка создания кода, сообщение о несоответствии типов данных в строке y = y + x(n);.
Чтобы просмотреть ошибку, откройте отчет.
В отчете, на строке y = y + x(n), в докладе подчеркивается y в левой части назначения красным цветом, что указывает на наличие ошибки. Проблема в том, что y объявлен как двойной, но назначается одному. y + x(n) - сумма двойника и одиночки, которая является одиночкой. При наведении курсора на переменные и выражения в отчете можно просмотреть информацию об их типах. Здесь видно, что выражение, y + x(n) является одиночкой.

Чтобы исправить несоответствие типов, обновите алгоритм, чтобы использовать подстрочное назначение для суммы элементов. Изменение y = y + x(n) кому y(:) = y + x(n).
function y = mysum(x) %#codegen y = 0; for n = 1:length(x) y(:) = y + x(n); end end
Использование подстрочного назначения также предотвращает рост битов, который является поведением по умолчанию при добавлении чисел с фиксированной точкой. Дополнительные сведения см. в разделе Рост битов. Предотвращение роста битов важно, потому что вы хотите поддерживать фиксированные типы точек во всем коде. Дополнительные сведения см. в разделе Управление ростом битов.
Повторно создайте код C и откройте отчет о создании кода. В коде C результат теперь сдвоен для устранения несоответствия типов.
Используйте buildInstrumentedMex функция для управления алгоритмом регистрации минимальных и максимальных значений всех именованных и промежуточных переменных. Используйте showInstrumentationResults функция для предложения типов данных с фиксированной точкой на основе этих записанных значений. Позже эти предлагаемые типы фиксированных точек будут использоваться для проверки алгоритма.
Обновить сценарий теста:
После объявления n, добавить buildInstrumentedMex mySum —args {zeros(n,1)} -histogram.
Изменение x назад, чтобы удвоить. Заменить x = single(2*rand(n,1)-1); с x = 2*rand(n,1)-1;
Вместо вызова исходного алгоритма вызовите сгенерированную функцию MEX. Изменение y = mysum(x) кому y=mysum_mex(x).
После вызова функции MEX добавьте showInstrumentationResults mysum_mex -defaultDT numerictype(1,16) -proposeFL. -defaultDT numerictype(1,16) -proposeFL флаги указывают, что требуется предложить длины дробей для 16-битной длины слова.
Вот обновленный сценарий теста.
%% Build instrumented mex n = 10; buildInstrumentedMex mysum -args {zeros(n,1)} -histogram %% Test inputs rng default x = 2*rand(n,1)-1; % Algorithm y = mysum_mex(x); % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x} -config:lib -report
Запустите сценарий теста еще раз.
showInstrumentationResults функция предлагает типы данных и открывает отчет для просмотра результатов.
В отчете перейдите на вкладку Переменные. showInstrumentationResults предлагает длину фракции 13 для y и 15 для x.

В отчете можно выполнить следующие действия:
Просмотр минимального и максимального значений моделирования для входных данных x и выходные данные y.
Просмотр предлагаемых типов данных для x и y.
Просмотр информации для всех переменных, промежуточных результатов и выражений в коде.
Чтобы просмотреть эту информацию, наведите курсор на переменную или выражение в отчете.
Просмотр данных гистограммы для x и y помогает определить любые значения, находящиеся вне диапазона или ниже точности на основе текущего типа данных.
Чтобы просмотреть гистограмму для определенной переменной, щелкните значок ее гистограммы.![]()
Вместо того чтобы вручную изменять алгоритм для проверки поведения для каждого типа данных, отделите определения типов данных от алгоритма.
Изменить mysum так что он принимает входной параметр, T, которая представляет собой структуру, определяющую типы данных входных и выходных данных. Когда y сначала определяется, используйте cast функция, как синтаксис - cast(x,'like',y) - для литья x к требуемому типу данных.
function y = mysum(x,T) %#codegen y = cast(0,'like',T.y); for n = 1:length(x) y(:) = y + x(n); end end
Напишите функцию, mytypesопределяет различные типы данных, которые необходимо использовать для тестирования алгоритма. В таблице типов данных включите двойные, одиночные и масштабированные двойные типы данных, а также типы данных с фиксированной точкой, предложенные ранее. Перед преобразованием алгоритма в фиксированную точку рекомендуется:
Проверьте соединение между таблицей определения типа данных и алгоритмом с помощью двойных значений.
Протестируйте алгоритм с одиночными кодами, чтобы найти несовпадения типов данных и другие проблемы.
Запустите алгоритм с помощью масштабированных двойников для проверки переполнений.
function T = mytypes(dt) switch dt case 'double' T.x = double([]); T.y = double([]); case 'single' T.x = single([]); T.y = single([]); case 'fixed' T.x = fi([],true,16,15); T.y = fi([],true,16,13); case 'scaled' T.x = fi([],true,16,15,... 'DataType','ScaledDouble'); T.y = fi([],true,16,13,... 'DataType','ScaledDouble'); end end
Дополнительные сведения см. в разделе Отдельные определения типов данных из алгоритма.
Обновление тестового сценария, mysum_test, для использования таблицы типов.
Для первого прогона проверьте соединение между таблицей и алгоритмом с помощью двойников. Перед объявлением n, добавить T = mytypes('double');
Обновить вызов до buildInstrumentedMex для использования типа T.x в таблице типов данных: buildInstrumentedMex mysum -args {zeros(n,1,'like',T.x),T} -histogram
Бросок x для использования типа T.x указано в таблице: x = cast(2*rand(n,1)-1,'like',T.x);
Вызов функции MEX при входе T: y = mysum_mex(x,T);
Звонить codegen прохождение T: codegen mysum -args {x,T} -config:lib -report
Вот обновленный сценарий теста.
%% Build instrumented mex T = mytypes('double'); n = 10; buildInstrumentedMex mysum ... -args {zeros(n,1,'like',T.x),T} -histogram %% Test inputs rng default x = cast(2*rand(n,1)-1,'like',T.x); % Algorithm y = mysum_mex(x,T); % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x,T} -config:lib -report
Запустите сценарий тестирования и щелкните ссылку, чтобы открыть отчет о создании кода.
Сгенерированный код C совпадает с кодом, сгенерированным для исходного алгоритма. Потому что переменная T используется для указания типов, и эти типы являются постоянными во время генерации кода; T не используется во время выполнения и не отображается в созданном коде.
Обновите сценарий тестирования для использования типов с фиксированной точкой, предложенных ранее, и просмотрите сгенерированный код C.
Обновите сценарий тестирования для использования типов с фиксированной точкой. Заменить T = mytypes('double'); с T = mytypes('fixed'); а затем сохраните сценарий.
Запустите сценарий тестирования и просмотрите сгенерированный код C.
Эта версия кода C не очень эффективна; он содержит много обработки переполнения. Следующим шагом является оптимизация типов данных во избежание переполнения.
Масштабированные двойники - это гибрид между числами с плавающей и фиксированной точками. Designer™ Fixed-Point сохраняет их как двойные с сохранением информации о масштабировании, знаке и длине слова. Поскольку вся арифметика выполняется с двойной точностью, можно увидеть любые возникающие переполнения.
Обновите тестовый сценарий, чтобы использовать масштабированные двойники. Заменить T = mytypes('fixed'); с T = mytypes('scaled');
Запустите сценарий теста еще раз.
Тест запускается с использованием масштабированных двойных значений и отображает отчет. Переполнения не обнаружены.
До сих пор вы запускаете сценарий теста с использованием случайных входных данных, что означает, что маловероятно, что тест выполнил полный рабочий диапазон алгоритма.
Найдите полный диапазон входных данных.
range(T.x)
-1.000000000000000 0.999969482421875
DataTypeMode: Fixed-point: binary point scaling
Signedness: Signed
WordLength: 16
FractionLength: 15Обновите сценарий для проверки отрицательного варианта края. Управляемый mysum_mex с исходным случайным вводом и с вводом, который проверяет весь диапазон и агрегирует результаты.
%% Build instrumented mex T = mytypes('scaled'); n = 10; buildInstrumentedMex mysum ... -args {zeros(n,1,'like',T.x),T} -histogram %% Test inputs rng default x = cast(2*rand(n,1)-1,'like',T.x); y = mysum_mex(x,T); % Run once with this set of inputs y_expected = sum(double(x)); err = double(y) - y_expected % Run again with this set of inputs. The logs will aggregate. x = -ones(n,1,'like',T.x); y = mysum_mex(x,T); y_expected = sum(double(x)); err = double(y) - y_expected % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x,T} -config:lib -report
Запустите сценарий теста еще раз.
Тестовые запуски и y переполняет диапазон типа данных с фиксированной точкой. showInstrumentationResults предлагает новую длину фракции 11 для y.

Обновление тестового сценария для использования масштабированных двойников с новым предлагаемым типом для y. В myTypes.m, для 'scaled' дело, T.y = fi([],true,16,11,'DataType','ScaledDouble')
Повторно запустите тестовый сценарий.
Переливов сейчас нет.
Обновите таблицу типов данных, чтобы использовать предлагаемый тип с фиксированной точкой и создать код.
В myTypes.m, для 'fixed' дело, T.y = fi([],true,16,11)
Обновление тестового сценария, mysum_test, для использования T = mytypes('fixed');
Запустите сценарий тестирования и щелкните ссылку Просмотр отчета, чтобы просмотреть сгенерированный код C.
short mysum(const short x[10])
{
short y;
int n;
int i;
int i1;
int i2;
int i3;
y = 0;
for (n = 0; n < 10; n++) {
i = y << 4;
i1 = x[n];
if ((i & 1048576) != 0) {
i2 = i | -1048576;
} else {
i2 = i & 1048575;
}
if ((i1 & 1048576) != 0) {
i3 = i1 | -1048576;
} else {
i3 = i1 & 1048575;
}
i = i2 + i3;
if ((i & 1048576) != 0) {
i |= -1048576;
} else {
i &= 1048575;
}
i = (i + 8) >> 4;
if (i > 32767) {
i = 32767;
} else {
if (i < -32768) {
i = -32768;
}
}
y = (short)i;
}
return y;
}По умолчанию fi арифметика использует насыщение при переполнении и ближайшее округление, что приводит к неэффективному коду.
Чтобы сделать созданный код более эффективным, используйте математику с фиксированной точкой (fimath), которые более подходят для генерации кода C: наложение при переполнении и округление пола.
В myTypes.m, добавить 'fixed2' случай:
case 'fixed2'
F = fimath('RoundingMethod', 'Floor', ...
'OverflowAction', 'Wrap', ...
'ProductMode', 'FullPrecision', ...
'SumMode', 'KeepLSB', ...
'SumWordLength', 32, ...
'CastBeforeSum', true);
T.x = fi([],true,16,15,F);
T.y = fi([],true,16,11,F);
Совет
Вместо ввода вручную fimath можно использовать опцию «Вставить fimath» редактора MATLAB. Дополнительные сведения см. в разделе Построение конструкторов объектов fimath в графическом интерфейсе пользователя.
Обновить тестовый сценарий для использования 'fixed2', запустите сценарий и просмотрите созданный код C.
short mysum(const short x[10])
{
short y;
int n;
y = 0;
for (n = 0; n < 10; n++) {
y = (short)(((y << 4) + x[n]) >> 4);
}
return y;
}Созданный код более эффективен, но y смещается для выравнивания с x и теряет 4 бита точности.
Чтобы исправить эту потерю точности, обновите длину слова y до 32 бит и сохранить 15 бит точности для выравнивания с x.
В myTypes.m, добавить 'fixed32' случай:
case 'fixed32'
F = fimath('RoundingMethod', 'Floor', ...
'OverflowAction', 'Wrap', ...
'ProductMode', 'FullPrecision', ...
'SumMode', 'KeepLSB', ...
'SumWordLength', 32, ...
'CastBeforeSum', true);
T.x = fi([],true,16,15,F);
T.y = fi([],true,32,15,F);
Обновить тестовый сценарий для использования 'fixed32' и запустите сценарий, чтобы снова создать код.
Теперь созданный код очень эффективен.
int mysum(const short x[10])
{
int y;
int n;
y = 0;
for (n = 0; n < 10; n++) {
y += x[n];
}
return y;
}Дополнительные сведения см. в разделе Оптимизация алгоритма.
