surrogateopt Алгоритмsurrogateopt Обзор алгоритмаАлгоритм суррогатной оптимизации чередуется между двумя фазами.
Создать суррогат - Создать options.MinSurrogatePoints случайные точки в пределах границ. Оцените (дорогостоящую) целевую функцию в этих точках. Создайте суррогат целевой функции путем интерполяции радиальной базисной функции через эти точки.
Поиск минимума (Search for Minimum) - поиск минимума целевой функции путем выборки нескольких тысяч случайных точек в пределах границ. Оценка функции качества на основе суррогатного значения в этих точках и расстояний между ними и точками, где была оценена (дорогостоящая) целевая функция. Выберите наилучший балл в качестве кандидата, измеряемый функцией оценки заслуг. Оцените целевую функцию в точке наилучшего кандидата. Эта точка называется адаптивной. Обновите суррогат, используя это значение, и повторите поиск.
Во время фазы конструирования суррогата алгоритм создает точки выборки из квазирандомной последовательности. Построение интерполяционной радиальной базисной функции занимает не менее nvars + 1 точка выборки, где nvars - количество переменных проблемы. Значение по умолчанию options.MinSurrogatePoints является 2*nvars или 20, в зависимости от того, что больше.
Алгоритм останавливает фазу Поиск минимума (Search for Minimum), когда все точки поиска находятся слишком близко (меньше, чем опция MinSampleDistance) в точки, где целевая функция была предварительно оценена. См. раздел Поиск минимальных сведений. Этот переключатель из фазы Search for Minimum называется суррогатным сбросом.
В описании алгоритма суррогатной оптимизации используются следующие определения.
Current - точка, в которой целевая функция была оценена совсем недавно.
Действующий - точка с наименьшим значением целевой функции среди всех оцениваемых с момента последнего сброса суррогата.
Лучший - точка с наименьшим значением целевой функции среди всех оцененных на данный момент.
Начальный (Initial) - точки, если таковые имеются, которые передаются решателю в InitialPoints вариант.
Случайные точки (Random points) - точки в фазе конструирования суррогата, где решатель оценивает целевую функцию. Как правило, решатель берет эти точки из квазирандомной последовательности, масштабируется и сдвигается, чтобы оставаться в пределах границ. Квазирандомная последовательность подобна псевдослучайной последовательности, такой как rand возвращает, но располагается более равномерно. Смотрите https://en.wikipedia.org/wiki/Low-discrepancy_sequence. Однако, когда число переменных превышает 500, решатель берет точки из латинской последовательности гиперкубов. Смотрите https://en.wikipedia.org/wiki/Latin_hypercube_sampling.
Адаптивные точки (Adaptive points) - точки в фазе Поиск минимума (Search for Minimum), где решатель оценивает целевую функцию.
Функция заслуг - см. Определение функции заслуг.
Вычисляемые точки - все точки, в которых известно значение целевой функции. Эти точки включают начальные точки, суррогатные точки конструкции и минимальные точки поиска, в которых решатель оценивает целевую функцию.
Выборочные точки. Псевдослучайные точки, в которых решатель оценивает функцию качества во время фазы Поиск минимума (Search for Minimum). Эти точки не являются точками, в которых решатель оценивает целевую функцию, за исключением случаев, описанных в разделе Поиск минимальных подробностей.
Для построения суррогата алгоритм выбирает квазирандомные точки в пределах границ. При прохождении начального набора точек в InitialPoints алгоритм использует эти точки и новые квазирандомные точки (при необходимости), чтобы достичь в общей сложности options.MinSurrogatePoints.
Когда BatchUpdateInterval > 1, минимальное количество точек случайной выборки, используемых для создания суррогата, больше MinSurrogatePoints и BatchUpdateInterval.
Примечание
Если некоторые верхние и нижние границы равны, surrogateopt удаляет эти «фиксированные» переменные из задачи перед созданием суррогата. surrogateopt бесшовно управляет переменными. Так, например, если проходите начальные точки, передайте полный набор, включая любые фиксированные переменные.
На последующих фазах конструирования суррогата алгоритм использует options.MinSurrogatePoints квазирандомные точки. Алгоритм оценивает целевую функцию в этих точках.
Алгоритм конструирует суррогат как интерполяцию целевой функции с помощью интерполятора радиальной базисной функции (RBF). Интерполяция RBF имеет несколько удобных свойств, которые делают его пригодным для конструирования суррогата:
Интерполятор RBF определяется по той же формуле в любом количестве размеров и с любым количеством точек.
Интерполятор RBF принимает заданные значения в вычисленных точках.
Оценка интерполятора RBF занимает мало времени.
Добавление точки к существующей интерполяции занимает относительно мало времени.
Построение RBF интерполятора включает в себя решение N-by-N линейной системы уравнений, где N - количество суррогатных точек. Как показал Пауэлл [1], эта система имеет уникальное решение для многих RBF.
surrogateopt использует кубический RBF с линейным хвостом. Эта RBF минимизирует меру неровности. Смотрите Гутманн [4].
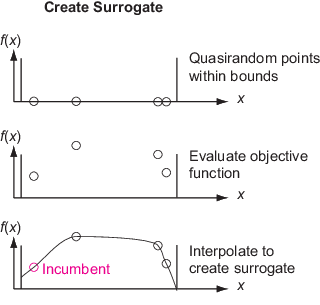
Алгоритм использует только начальные точки и случайные точки в первой фазе конструирования суррогата и использует только случайные точки в последующих фазах конструирования суррогата. В частности, алгоритм не использует в этом суррогате какие-либо адаптивные точки из фазы Поиск минимума.
Решатель ищет минимум целевой функции, следуя процедуре, связанной с локальным поиском. Решатель инициализирует масштаб для поиска со значением 0,2. Масштаб подобен радиусу области поиска или размеру сетки при поиске массива. Решатель начинается с текущей точки, которая является точкой с наименьшим значением целевой функции с момента последнего сброса суррогата. Решатель ищет минимум функции качества, которая относится как к суррогату, так и к расстоянию от существующих точек поиска, чтобы попытаться сбалансировать минимизацию суррогата и поиск пространства. См. раздел Определение функции качества.
Решатель добавляет сотни или тысячи псевдослучайных векторов с масштабированной длиной к текущей точке для получения точек выборки. Эти векторы имеют нормальные распределения, сдвинуты и масштабированы на границы в каждом измерении и умножены на масштаб. При необходимости решатель изменяет точки выборки так, чтобы они оставались в пределах границ. Решатель оценивает функцию качества в точках выборки, но не в любой точке в пределах options.MinSampleDistance предварительно вычисленной точки. Точка с наименьшим значением функции качества называется адаптивной точкой. Решатель оценивает значение целевой функции в адаптивной точке и обновляет суррогат этим значением. Если значение целевой функции в адаптивной точке в достаточной степени ниже действующего значения, то решатель считает поиск успешным и устанавливает адаптивную точку в качестве действующего. В противном случае решатель сочтет поиск неуспешным и не изменит его.
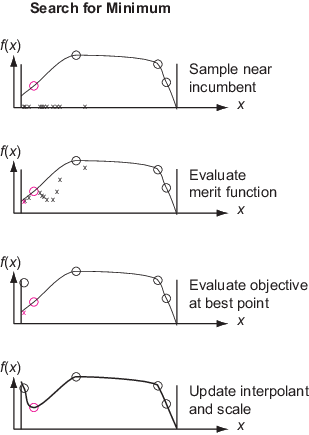
Решатель изменяет масштаб при выполнении первого из следующих условий:
С момента последнего изменения масштаба выполняются три успешных поиска. В этом случае масштаб удваивается до максимальной длины шкалы 0.8 умножает размер поля, заданного границами.
max(5,nvar) неудачные поиски происходят с момента последнего изменения масштаба, где nvar - количество переменных проблемы. В этом случае масштаб уменьшается вдвое до минимальной длины шкалы, равной 1e-5 умножает размер поля, заданного границами.
Таким образом, случайный поиск, в конечном счете, концентрируется вблизи текущей точки, которая имеет небольшое значение целевой функции. Затем решатель геометрически уменьшает масштаб до минимальной длины масштаба.
Решатель не оценивает функцию качества в точках внутри options.MinSampleDistance оцененной точки (см. Определения для суррогатной оптимизации). Решатель переключается с фазы Поиск минимума на фазу конструирования суррогата (другими словами, выполняет сброс суррогата), когда все точки выборки находятся в пределах MinSampleDistance оцененных баллов. Как правило, этот сброс происходит после того, как решатель уменьшает масштаб, так что все точки выборки плотно группируются вокруг действующего пользователя.
Когда BatchUpdateInterval параметр больше, чем 1, решатель генерирует BatchUpdateInterval адаптивные точки перед обновлением суррогатной модели или изменением действующего лица. Обновление включает все адаптивные точки. Фактически алгоритм не использует никакой новой информации, пока не генерирует BatchUpdateInterval адаптивные точки, а затем алгоритм использует всю информацию для обновления суррогата.
Функция заслуг fmerit (x) представляет собой взвешенную комбинацию двух терминов:
Масштабированный суррогат. Определите smin как минимальное суррогатное значение среди точек выборки, smax как максимальное и s (x) как суррогатное значение в точке x. Тогда масштабированный суррогатный S (x) будет
− smin.
s (x) неотрицателен и равен нулю в точках x, которые имеют минимальное суррогатное значение среди точек выборки.
Масштабированное расстояние. Определите xj, j = 1,..., k как k вычисляемых точек. Определите dij как расстояние от точки образца i до расчетной точки k. Установите dmin = min (dij) и dmax = max (dij), где минимально и максимально принимают все i и j. Масштабированное расстояние D (x) равно
dmax − dmin,
где d (x) - минимальное расстояние между точкой x и вычисляемой точкой. D (x) неотрицателен и равен нулю в точках x, которые максимально далеки от оцененных точек. Таким образом, минимизация D (x) приводит алгоритм к точкам, которые далеки от оцененных точек.
Функция качества представляет собой выпуклую комбинацию масштабированного суррогата и масштабированного расстояния. Для веса w с 0 < w < 1 функция качества
w) D (x).
Большое значение w придает важность суррогатным значениям, заставляя поиск минимизировать суррогат. Небольшое значение w придает важность точкам, которые далеки от оцененных точек, что приводит к поиску новых регионов. Во время фазы «Поиск минимума» вес w проходит через эти четыре значения, как предложено Реджисом и Шумейкером [2]: 0,3, 0,5, 0,8 и 0,95.
surrogateopt Алгоритмsurrogateopt ОбзорЕсли некоторые или все переменные являются целыми, как указано в intcon аргумент, surrogateopt изменяет некоторые аспекты алгоритма Serial surrogateopt. Это описание в основном касается изменений, а не всего алгоритма.
При необходимости surrogateopt перемещает указанные границы для intcon точки, чтобы они были целыми числами. Также, surrogateopt гарантирует, что предоставленная начальная точка является целочисленной возможной и осуществимой по отношению к границам. Затем алгоритм генерирует квазирандомные точки, как в ненегерном алгоритме, округляя целочисленные точки до целых значений. Алгоритм генерирует суррогат точно так же, как в ненегерном алгоритме.
Поиск минимума продолжается с использованием той же самой функции качества и последовательности весов, что и ранее. Разница в том, что surrogateopt использует три различных метода выборки случайных точек для определения минимального значения функции качества. surrogateopt выбирает пробоотборник в цикле, связанном с весами, согласно следующей таблице.
Цикл пробоотборника
| Вес | 0.3 | 0.5 | 0.8 | 0.95 |
| Образец | Случайный | Случайный | OrthoMADS | GPS |
Масштаб (Scale) - каждый пробоотборник производит выборку точек в пределах масштабированной области вокруг сотрудника. Целочисленные точки имеют масштаб, начинающийся в ½ раза больше ширины границ, и корректируется точно так же, как не целочисленные точки, за исключением того, что ширина увеличивается до 1, если она когда-либо опускается ниже 1. Масштаб непрерывных точек развивается точно так же, как в ненулевом алгоритме.
Случайный (Random) - пробоотборник генерирует целые точки равномерно случайным образом в пределах шкалы, центрированной у действующего лица. Пробоотборник генерирует непрерывные точки согласно гауссову со средним нулем от действующего. Ширина выборок целых точек умножается на масштаб, как и стандартное отклонение непрерывных точек.
OrthoMADS - выборщик выбирает ортогональную систему координат равномерно случайным образом. Затем алгоритм создает точки выборки вокруг действующего лица, добавляя и вычитая текущий масштаб, умноженный на каждый единичный вектор в системе координат. Алгоритм округляет целочисленные точки. При этом создаются 2N выборки (если только некоторые целочисленные точки не округляются до действующего), где N - число проблемных измерений. OrthoMADS также использует две точки больше, чем 2N фиксированные направления, одна в [+ 1, + 1,..., + 1], а другая в [-1, -1,..., -1], в общей сложности 2N + 2 точек. Затем пробоотборник многократно вдвое сокращает 2N + 2 шага, создавая более тонкий и тонкий набор точек вокруг действующего, при этом округляя целочисленные точки. Этот процесс завершается, когда либо имеется достаточное количество проб, либо округление не приводит к появлению новых проб.
GPS - пробоотборник подобен OrthoMADS, за исключением того, что вместо выбора случайного набора направлений GPS использует не повернутую систему координат.
После выборки сотен или тысяч значений функции качества, surrogateopt обычно выбирает минимальную точку и оценивает целевую функцию. Однако при двух обстоятельствах surrogateopt выполняет другой поиск под названием Поиск в дереве (Tree Search) перед оценкой цели:
После последнего поиска в дереве, получившего название Case A, было выполнено 2N шагов.
surrogateopt собирается выполнить суррогатный сброс, называемый случаем B.
Поиск дерева выполняется следующим образом, аналогично процедуре в intlinprog, как описано в разделе Ветвь и Граница. Алгоритм создает дерево, найдя целочисленное значение и создав новую задачу, которая имеет ограничение на это значение либо на одну выше, либо на одну ниже, и решая подпроблему с помощью этого нового ограничения. После решения подпроблемы алгоритм выбирает другое целое число, ограничиваемое либо выше, либо ниже единицей.
Случай A: используйте масштабированный радиус выборки в качестве общих границ и выполните до 1000 шагов поиска.
Случай B: Используйте исходные границы проблемы в качестве общих границ и выполните до 5000 шагов поиска.
В этом случае решение подпроблемы означает запуск fmincon
'sqp' алгоритм на непрерывных переменных, начиная от действующего с заданными целочисленными значениями, поэтому ищите локальный минимум функции качества.
Поиск в дереве может занять много времени. Так surrogateopt имеет внутренний предел времени, чтобы избежать чрезмерного времени на этом этапе, ограничивая как число этапов варианта А, так и варианта В.
В конце поиска дерева алгоритм берет лучшее из точки, найденной при поиске дерева, и точки, найденной при предыдущем поиске, для минимума, измеренного функцией качества. Алгоритм оценивает целевую функцию в этот момент. Остальная часть целочисленного алгоритма в точности совпадает с непрерывным алгоритмом.
Когда задача имеет линейные ограничения, алгоритм изменяет свою процедуру поиска таким образом, что все точки остаются выполнимыми по отношению к этим ограничениям и по отношению к границам на каждой итерации. На этапах построения и поиска алгоритм создает только линейно возможные точки с помощью процедуры, аналогичной patternsearch
'GSSPositiveBasis2N' алгоритм опроса.
Когда проблема имеет целочисленные ограничения и линейные ограничения, алгоритм сначала создает линейно возможные точки. Затем алгоритм пытается удовлетворить целочисленные ограничения процессом округления линейно возможных точек до целых чисел с помощью эвристики, которая пытается сохранить точки линейно выполнимыми. Когда этот процесс не удается получить достаточно возможных точек для построения суррогата, алгоритм вызывает intlinprog чтобы попытаться найти больше точек, которые возможны в отношении границ, линейных ограничений и целочисленных ограничений.
surrogateopt Алгоритм с нелинейными ограничениямиЕсли проблема имеет нелинейные ограничения, surrogateopt модифицирует ранее описанный алгоритм несколькими способами.
Первоначально и после каждого суррогатного сброса алгоритм создает суррогаты целевой и нелинейной функций ограничения. Впоследствии алгоритм отличается в зависимости от того, нашла ли фаза конструирования суррогата какие-либо возможные точки; нахождение осуществимой точки эквивалентно той, которая существует при построении суррогата.
Должность неосуществима - этот случай, называемый фазой 1, включает поиск возможной точки. В фазе Поиск минимума (Search for Minimum) перед тем, как встретить выполнимую точку, surrogateopt изменяет определение функции оценки заслуг. Алгоритм подсчитывает количество ограничений, которые нарушаются в каждой точке, и рассматривает только те точки с наименьшим числом нарушенных ограничений. Среди этих точек алгоритм выбирает точку, которая минимизирует максимальное нарушение ограничения, в качестве лучшей (наименьшая функция качества) точки. Этот лучший момент - действующий. Впоследствии, пока алгоритм не встретит осуществимую точку, он использует эту модификацию функции качества. Когда surrogateopt оценивает точку и находит, что она осуществима, осуществимая точка становится действующей, и алгоритм находится в фазе 2.
Этот случай, называемый фазой 2, выполняется так же, как и стандартный алгоритм. Алгоритм игнорирует неосуществимые точки с целью вычисления функции качества.
Алгоритм работает согласно алгоритму смешанного целочисленного суррогатеопта со следующими изменениями. После каждого 2*nvars точки, в которых алгоритм оценивает целевую и нелинейную функции ограничения, surrogateopt вызывает fmincon функция для минимизации суррогата с учетом суррогатных нелинейных ограничений и границ, где границы масштабируются текущим масштабным коэффициентом. (Если лицо, занимающее эту должность, неосуществимо, fmincon игнорирует цель и пытается найти точку, удовлетворяющую ограничениям.) Если задача имеет целочисленные и нелинейные ограничения, то surrogateopt вызывает функцию поиска в дереве вместо fmincon.
Если проблема является проблемой выполнимости, что означает, что она не имеет объективной функции, то surrogateopt выполняет сброс суррогата сразу после того, как он находит осуществимую точку.
surrogateopt АлгоритмПараллель surrogateopt алгоритм отличается от последовательного следующим образом:
Параллельный алгоритм поддерживает очередь точек, по которым вычисляется целевая функция. Эта очередь на 30% больше числа параллельных работников, округленных. Очередь больше, чем число работников, чтобы минимизировать вероятность простоя работника, поскольку нет точки для оценки.
Планировщик берет точки из очереди в режиме FIFO и назначает их работникам по мере их простоя асинхронно.
Когда алгоритм переключается между фазами (Поиск минимума и Построение суррогата), существующие оцениваемые точки остаются в обслуживании, и любые другие точки в очереди удаляются (отбрасываются из очереди). Таким образом, как правило, число случайных точек, которые алгоритм создает для фазы конструирования суррогата, не более options.MinSurrogatePoints + PoolSize, где PoolSize - количество параллельных работников. Аналогично, после суррогатного сброса алгоритм все еще имеет PoolSize - 1 адаптивные точки, которые оценивают его работники.
Примечание
В настоящее время параллельная суррогатная оптимизация не обязательно дает воспроизводимые результаты из-за невосстановимости параллельной синхронизации, что может привести к различным путям выполнения.
surrogateopt АлгоритмПри параллельном выполнении задачи со смешанным целым числом surrogateopt выполняет процедуру поиска дерева на хосте, а не на параллельных рабочих. Используя новейший суррогат, surrogateopt ищет меньшее значение суррогата после того, как каждый работник возвращается с адаптивной точкой.
Если целевая функция не является дорогостоящей (занимает много времени), то эта процедура поиска в дереве может быть узким местом на хосте. Напротив, если целевая функция является дорогостоящей, то процедура поиска дерева занимает небольшую часть общего вычислительного времени и не является узким местом.
[1] Пауэлл, М. Дж. Д. Теория приближения радиальной базисной функции в 1990 году. In Light, W. A. (редактор), Advances in Numerical Analysis, Volume 2: Wavelets, Subdivision Algorithms и Radial Basis Functions. Clarendon Press, 1992, стр. 105-210.
[2] Режис, R. G. и C. A. Сапожник. Метод стохастической радиальной базовой функции для глобальной оптимизации дорогостоящих функций. INFORMS J. Computing 19, 2007, стр. 497-509.
[3] Ван, Я. и К. А. Шумейкер. Общая структура стохастического алгоритма для минимизации дорогостоящих целевых функций черного ящика на основе суррогатных моделей и анализа чувствительности. arXiv:1410.6271v1 (2014). Доступно по адресу https://arxiv.org/pdf/1410.6271.
[4] Гутманн, Х.-М. Метод радиальной базовой функции для глобальной оптимизации. Журнал глобальной оптимизации 19, март 2001, стр. 201-227.
