Накапливать векторные элементы
B = accumarray(ind,data)data в соответствии с группами, указанными в ind. Затем вычисляется сумма по каждой группе. Значения в ind определить как группу, к которой принадлежат данные, так и индекс в выходном массиве, B где хранится каждая групповая сумма.
Для возврата групповых сумм по порядку укажите ind как вектор. Затем для группы с индексом i, accumarray возвращает его сумму в B(i). Например, если ind = [1 1 2 2]' и data = [1 2 3 4]', то B = accumarray(ind,data) возвращает вектор столбца B = [3 7]'.
Чтобы вернуть групповые суммы в другой форме, укажите ind в виде матрицы. Для матрицы m-на-n ind, каждая строка представляет групповое назначение и n-мерный индекс на выходе B. Например, если ind содержит две строки формы [3 4], то сумма соответствующих элементов в data хранится в (3,4) элементе B.
Элементы B чей индекс не отображается в ind заполнены 0 по умолчанию.
B = accumarray(ind,data,sz)B дополнено до размера sz. Определить sz как вектор положительных целых чисел, совпадающих или превышающих размерные длины в ind. Дополнительные элементы на выходе заполнены 0. Определить sz как [] для включения индексов ind определите размер выходного сигнала.
На следующем рисунке показано поведение accumarray на векторе температурных данных, взятых за 12-месячный период. Чтобы найти максимальное значение температуры для каждого месяца, accumarray применяет max для каждой группы значений в temperature которые имеют идентичные индексы в month.
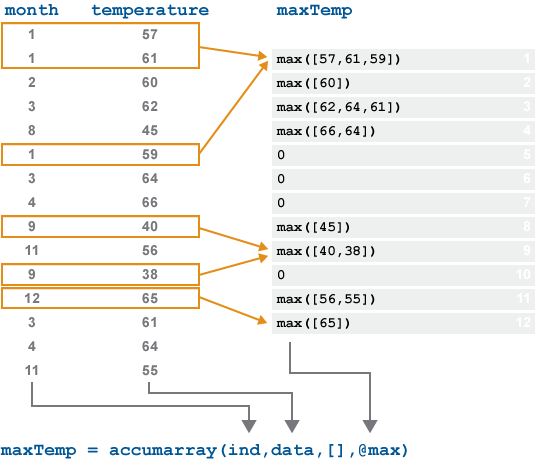
Нет значений в month указывает на 5, 6, 7 или 10 позиций выходного сигнала. Эти элементы являются 0 в выходных данных по умолчанию.
Поведение accumarray аналогичен функциям groupsummary и groupcounts для вычисления суммарной статистики по группам и подсчета количества элементов в группе соответственно. Дополнительные возможности группирования в MATLAB ® см. в разделе Данные предварительной обработки.
Поведение accumarray также аналогичен histcounts функция.
histcounts группирует непрерывные значения в диапазон 1-D с использованием ребер ячеек. accumarray группирует данные по n-мерным индексам.
histcounts может возвращать только количество ячеек и размещение ячеек. accumarray может применить любую функцию к данным.
Вы можете имитировать поведение histcounts использование accumarray с data = 1.
sparse функция также имеет поведение накопления, аналогичное поведению accumarray.
sparse группирует данные с использованием индексов 2-D, тогда как accumarray группирует данные по n-мерным индексам.
Для элементов с одинаковыми индексами, sparse применяет sum функция (для double значения) или any функция (для logical значения) и возвращает скалярный результат в выходной матрице. accumarray суммы по умолчанию, но может применить любую функцию к данным.
