Используйте функции Пошагового (Stepwise), чтобы помочь найти подходящую модель. Целью пошагового поиска является минимизация НАЖАТЬ. Минимизация прогнозируемой суммы ошибок квадратов (PRESS) является хорошим методом для работы над регрессионной моделью, которая обеспечивает хорошую прогностическую способность в экспериментальном факторном пространстве. См. статистику PRESS.
Использование PRESS является ключевым показателем прогнозирующего качества модели. Прогнозируемая ошибка использует прогнозы, рассчитанные без использования наблюдаемого значения для этого наблюдения. ПРЕСС известен как Delete-1 статистика в продукте Toolbox™ статистики и машинного обучения. См. также Двухступенчатые модели для двигателей.
Можно выбрать автоматическое пошаговое управление во время настройки модели или ручное управление с помощью окна Пошаговое (Stepwise).
Используйте меню Пошаговая (Stepwise) в диалоговых окнах Настройка модели (Model Setup), чтобы выполнять пошагово автоматически при построении линейных моделей.
Откройте окно пошаговой регрессии с помощью![]() значка панели инструментов, когда вы находитесь на виде глобального уровня. Инструмент Stepwise предоставляет ряд методов выбора терминов модели, которые должны быть включены.
значка панели инструментов, когда вы находитесь на виде глобального уровня. Инструмент Stepwise предоставляет ряд методов выбора терминов модели, которые должны быть включены.
Можно настроить автоматические процедуры выбора минимИзировать ПРЕСС, Вперед и Назад без необходимости ввода пошагового показателя.
Эти опции можно задать в диалоговом окне Настройка модели (Model Setup) при первоначальной настройке плана тестирования или на глобальном уровне следующим образом.
Выберите «Модель» > «Настроить».
В диалоговом окне Настройка глобальной модели (Global Model Setup) имеется раскрывающееся меню Пошаговое (Stepwise) с опциями None, Minimize PRESS, Forward selection, и Backward selection.
Используйте пошаговые кнопки в нижней части окна (также доступные в меню Регрессия) следующим образом:
Чтобы автоматически включить или удалить термины для сведения к минимуму, нажмите кнопку Min. PRESS (на следующем рисунке - 1). Эта процедура обеспечивает модель с улучшенной прогностической способностью.
Включить все термины в модель (за исключением терминов, помеченных как Статус Never). Эта опция полезна в сочетании с Min. PRESS и обратным выбором. Например, сначала щелкните Включить все, затем Мин. НАЖАТЬ. Затем можно снова щелкнуть Включить все (Include All), а затем Назад (Backwards), чтобы сравнить, что дает наилучший результат.
Удалить все термины в модели (за исключением терминов, помеченных как Статус Always). Эта опция полезна в сочетании с выбором вперед (щелкните Удалить все, затем Вперед).
Перенос выбора добавляет все термины к модели, что приведет к статистически значимым терминам на ![]()
% уровень (см. шаг 4 для альфа). Добавление терминов повторяется до тех пор, пока все термины в модели не станут статистически значимыми.

При обратном выборе удаляются все термины из модели, которые не являются статистически значимыми на ![]() уровне%. Удаление терминов повторяется до тех пор, пока все термины в модели не станут статистически значимыми.
уровне%. Удаление терминов повторяется до тех пор, пока все термины в модели не станут статистически значимыми.
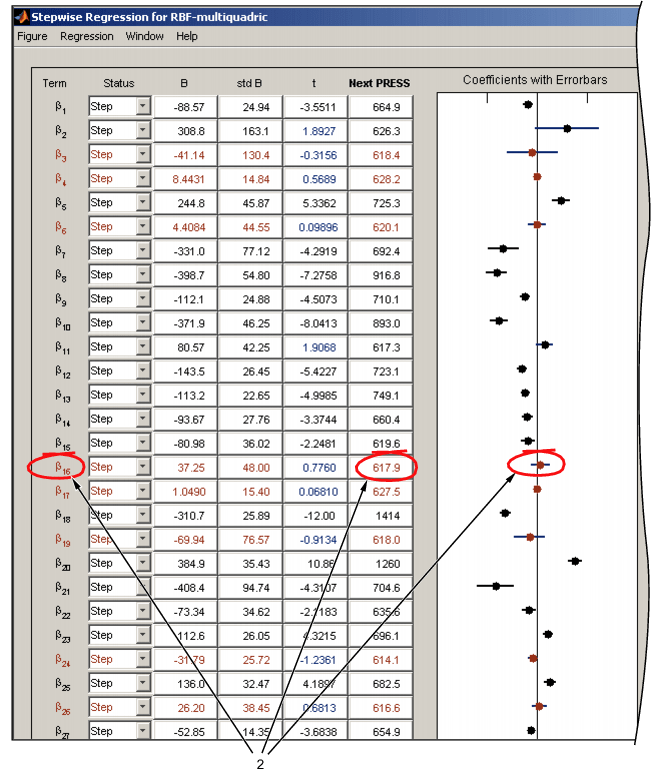
Термины также можно включить в модель вручную или удалить из нее, нажав кнопку Term (термин), Next PRESS (следующее нажатие) или строку ошибки коэффициента (2 на следующем рисунке).
Доверительные интервалы для всех коэффициентов показаны справа от таблицы. Заметим, что интервал для постоянного члена не отображается, так как значение этого коэффициента часто значительно больше других коэффициентов.
Термины, которые в настоящее время не включены в модель, отображаются красным цветом. Значения заголовков столбцов см. в пошаговой таблице.
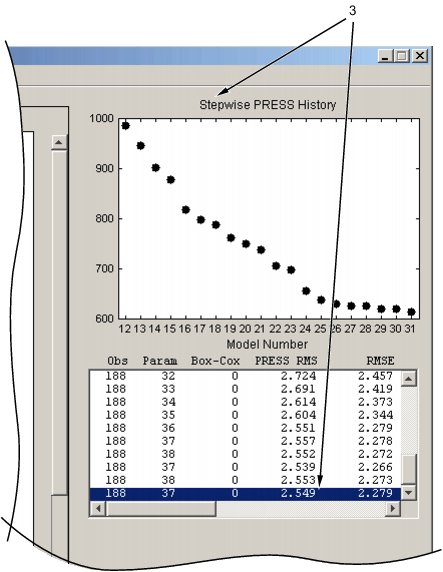
История ПРЕСС и сводная статистика показаны справа от пошагового рисунка. Вы можете возвратиться к предыдущей модели, щелкнув по пункту в поле списка, или пункт на Пошаговом сюжете Истории ПРЕССЫ (маркировал 3 в следующем числе).
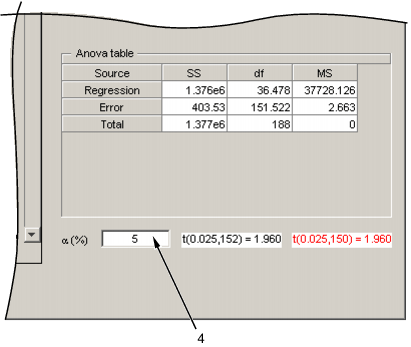
Критические значения для проверки того, статистически ли коэффициент отличается от нуля при ![]()
% уровень отображается в правой нижней части пошагового рисунка. Можно ввести значение![]() в поле редактирования (обозначенное 4 на следующем рисунке) слева от критических значений. Значение по умолчанию - 5%. Для текущей модели отображается таблица ANOVA.
в поле редактирования (обозначенное 4 на следующем рисунке) слева от критических значений. Значение по умолчанию - 5%. Для текущей модели отображается таблица ANOVA.
Любые изменения, внесенные в пошаговый рисунок, автоматически обновляют диагностические графики в браузере модели.
При закрытии окна Пошаговый (Stepwise) можно вернуться к начальной модели. При выходе из окна Stepwise появляется диалоговое окно Confirm Stepwise Exit. Do you want to update regression results? Можно нажать кнопку Да (Yes) (по умолчанию), Нет (No) (чтобы вернуться к начальной модели) или Отмена (Cancel) (чтобы вернуться в окно Пошаговое (Stepwise)).
Ступенчатая таблица
| Термин | Метка для коэффициента |
|---|---|
Статус | Всегда. Ступенчатый не удаляет этот термин. Никогда. Пошаговый не добавляет этот термин. Шаг. Поэтапно рассматривает этот термин для добавления или удаления. |
B | Значение коэффициента. Если член отсутствует в модели, значение коэффициента при его добавлении к модели отображается красным цветом. |
stdB | Стандартная погрешность коэффициента. |
t | t, чтобы проверить, статистически ли коэффициент отличается от нуля. Значение t выделяется синим цветом, если оно меньше критического значения, указанного в |
Следующий ПРЕСС | Значение PRESS, если включение или исключение этого термина изменяется при следующей итерации. Желтая выделенная ячейка указывает следующий рекомендуемый термин для изменения. Включение или исключение выделенного термина (в зависимости от его текущего состояния) приведет к наибольшему снижению значения PRESS. Если желтая подсветка отсутствует, это означает, что значение PRESS уже минимизировано. При наличии желтой ячейки заголовок столбца также имеет желтый цвет, что предупреждает о возможности внесения изменений для получения меньшего значения PRESS. Заголовок столбца выделен, так как для поиска желтой ячейки может потребоваться прокрутка. |
В предыдущей таблице описываются значения заголовков столбцов в окне Пошаговая регрессия.
После настройки модели необходимо создать несколько альтернативных моделей, использовать функции Stepwise и изучить статистику диагностики для поиска подходящей модели. Для каждой функции ответа,
Начните с пошагового поиска.
Это можно сделать автоматически или с помощью окна Пошаговый (Stepwise).
Целью пошагового поиска является минимизация НАЖАТЬ. Обычно возникает не одна, а несколько моделей-кандидатов на каждый признак ответа, каждая с очень похожим R2 PRESS. Прогностическая способность модели с R2 PRESS 0,91 не может считаться превосходящей в каком-либо значимом инженерном смысле модель с R2 PRESS 0,909. Кроме того, характер процесса построения модели заключается в том, что «улучшение» R2 ПРЕСС, предложенное последними несколькими терминами, часто очень мало. Следовательно, может возникнуть несколько моделей-кандидатов. Каждую из моделей-кандидатов и связанную с ней диагностическую информацию можно сохранить отдельно для последующего просмотра. Для этого необходимо выбрать дочерние узлы для функции ответа.
Однако опыт показал, что модель с R2 PRESS менее 0,8, скажем, мало используется в качестве прогнозирующего инструмента для целей картирования двигателя. К этому критерию следует подходить с осторожностью. Низкие значения PRESS R2 могут быть результатом плохого выбора исходных факторов, а также наличия внешних или влиятельных точек в наборе данных. Вместо того, чтобы полагаться только на PRESS R2, более безопасная стратегия заключается в изучении диагностической информации модели для выявления характера любых фундаментальных проблем, а затем принятия соответствующих корректирующих действий.
После завершения пошагового процесса диагностические данные должны быть рассмотрены для каждой модели-кандидата.
Возможно, только этих данных достаточно для того, чтобы обеспечить возможность выбора одной модели. Это было бы так, если бы одна модель явно демонстрировала более идеальное поведение, чем другие. Помните, что интерпретация диагностических графиков субъективна.
На этом этапе также следует удалить внешние данные. Можно задать критерии для обнаружения внешних данных. Критерием по умолчанию является любой случай, когда абсолютное значение внешнего исследуемого остатка больше 3.
После удаления внешних данных продолжите процесс построения модели в попытке удалить дополнительные термины.
Термины высокого порядка могли быть сохранены в модели в попытке следовать за исходящими данными. Даже после удаления внешних данных нет гарантии, что диагностические данные позволят предположить, что была найдена подходящая модель-кандидат. В этих обстоятельствах
Преобразование функции ответа может оказаться полезным.
Полезный набор преобразований предоставляется семейством Box и Cox, см. Преобразование Box-Cox. Обратите внимание, что алгоритм Бокса-Кокса зависит от модели и как таковой всегда выполняется с использованием (Nxq) регрессионной матрицы. X.
После выбора преобразования следует повторить пошаговый поиск НАЖАТЬ и выбрать подходящее подмножество моделей-кандидатов.
После этого необходимо проанализировать соответствующие диагностические данные для каждой модели.
Может быть непонятно, почему первоначальный пошаговый поиск проводился в естественной метрике. Почему бы не перейти непосредственно к трансформации? Это кажется разумным, когда понятно, что алгоритм Бокса-Кокса часто, но не всегда, предполагает, что применяется сжимающее преобразование, такое как квадратный корень или логарифм. Для этого есть две основные причины:
Основная причина выбора характеристик ответа заключается в том, что они обладают естественной инженерной интерпретацией. Маловероятно, что поведение трансформированной версии функции ответа так же интуитивно легко понять.
Внешние данные могут сильно влиять на тип выбранного преобразования. Применение преобразования, позволяющего модели хорошо соответствовать плохим данным, не кажется разумной стратегией. С помощью «плохих» данных предполагается, что данные действительно ненормальны, и была обнаружена причина, по которой данные выходят наружу; например, «Анализатор выбросов продувался, пока принимались результаты».
Наконец, если невозможно найти подходящую модель-кандидат после завершения пошагового поиска с преобразованной метрикой, то существует серьезная проблема либо с данными, либо с текущим уровнем технических знаний системы. В этих обстоятельствах следует применять увеличение модели или альтернативную экспериментальную или модельную стратегию.
После выполнения этих шагов рекомендуется проверить модель на соответствие другим данным (если таковые имеются). См. раздел Окно оценки модели.
См. также следующие страницы рекомендаций со ссылками на информацию о каждом из шагов, связанных с созданием одно- и двухэтапных моделей и последующим поиском наилучшего соответствия:
Рекомендуемый общий пошаговый процесс лучше всего рассматривать графически, как показано на следующей блок-схеме.
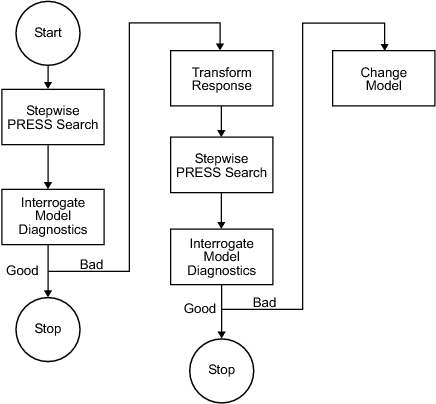
Отметим, что процесс, изображенный на предыдущей диаграмме, должен быть выполнен для каждого члена набора признаков ответа, связанных с данным ответом, и затем повторен для остальных ответов.
При n пробегах в наборе данных уравнение модели подгоняется к n-1 пробегам и прогнозированию, взятому из этой модели для оставшейся. Разность между записанным значением данных и значением, заданным моделью (при значении пропущенного прогона), называется остаточным предсказанием. НАЖАТЬ - сумма квадратов остатков предсказания. Квадратный корень из PRESS/n - PRESS RMSE (среднеквадратическая ошибка прогнозирования).
Следует отметить, что прогнозируемый остаток отличается от обычного остатка, который представляет собой разность между записанным значением и значением модели при установке во весь набор данных.
Статистика PRESS дает хорошее указание на прогностическую силу вашей модели, поэтому желательно минимизировать PRESS. Полезно сравнить PRESS RMSE с RMSE, поскольку это может указывать на проблемы с переоборудованием. RMSE минимизируется, когда модель приближается к каждой точке данных; «Поиск» данных, следовательно, улучшит RMSE. Однако отслеживание данных иногда может привести к сильным колебаниям в модели между точками данных; это поведение может дать хорошие значения RMSE, но не является репрезентативным для данных и не даст надежных значений прогноза, если у вас еще нет данных. Статистика PRESS RMSE защищает от этого, проверяя, насколько хорошо текущая модель будет предсказывать каждую из точек в наборе данных (в свою очередь), если они не были включены в регрессию. Для получения небольшого значения PRESS RMSE обычно указывает, что модель не слишком чувствительна к какой-либо отдельной точке данных.
Дополнительные сведения см. в разделе Рекомендации по выбору терминов и определений статистики наилучшего соответствия модели, ступенчатой регрессии и набора инструментов.
Обратите внимание, что вычисление PRESS для двухэтапной модели применяет тот же принцип (подбор модели для n-1 прогонов и взятие прогноза из этой модели для оставшейся), но в этом случае предсказанные значения сначала находят для характеристик отклика вместо точек данных. Оценивают прогнозируемое значение, исключая каждый тест по очереди, для каждого признака отклика. Затем прогнозируемые характеристики отклика используются для восстановления локальной кривой для теста, и эта кривая используется для получения двухэтапных прогнозов. Это применяется следующим образом:
Для расчета двух ступеней НАЖАТЬ:
Для каждого теста S выполните следующие шаги:
Для каждого из признаков ответа рассчитайте, какими будут предсказания признака ответа для S (с исключенными из расчета признаками ответа для S).
Это дает кривую локального прогнозирования C, основанную на всех тестах, кроме S.
Для каждой точки данных в тесте вычислите разницу между наблюдаемым значением и значением, предсказанным С.
Повторите для всех тестов.
Суммирование квадрата всех найденных разностей и деление на общее количество точек данных.
