Алгоритм кластеризации данных на основе плотности
clusterDBSCAN кластеры точек данных, принадлежащих пространству P-мерных признаков, используя основанную на плотности пространственную кластеризацию приложений с алгоритмом шума (DBSCAN). Алгоритм кластеризации назначает точки, близкие друг к другу в пространстве элементов, одному кластеру. Например, радиолокационная система может возвращать множество обнаружений расширенной цели, которые находятся на близком расстоянии по дальности, углу и доплеровской частоте. clusterDBSCAN назначает эти обнаружения одному обнаружению.
Алгоритм DBSCAN предполагает, что кластеры являются плотными областями в пространстве данных, разделенными областями более низкой плотности, и что все плотные области имеют одинаковые плотности.
Чтобы измерить плотность в точке, алгоритм подсчитывает количество точек данных в окрестности точки. Окрестность - это P-мерный эллипс (гиперэллипс) в пространстве элементов. Радиусы эллипса определяются P-вектором start. λ может быть скаляром, в этом случае гиперэллипс становится гиперсферой. Расстояния между точками в пространстве элемента вычисляются с использованием евклидовой метрики расстояния. Окрестности называются, по-видимому, в-окрестности. Значение startопределяется значением Epsilon собственность. Epsilon может быть скалярным или P-вектором:
Вектор используется, когда различные размеры в пространстве элемента имеют разные единицы измерения.
Скаляр применяет одно и то же значение ко всем измерениям.
Кластеризация начинается с поиска всех основных точек. Если точка имеет достаточное количество точек в своей λ-окрестности, точка называется точкой ядра. Минимальное количество точек, необходимое для того, чтобы точка стала базовой точкой, задается параметром MinNumPoints собственность.
Остальными точками в δ-окрестности точки ядра могут быть сами точки ядра. Если нет, то это пограничные пункты. Все точки в λ-окрестности называются непосредственно плотностью, достижимой из точки ядра.
Если та, что находится в окрестности ядра, содержит другие точки ядра, то точки в тех, что находятся в окрестностях ядра, объединяются вместе, образуя объединение тех, что находятся в окрестностях. Этот процесс продолжается до тех пор, пока не будут добавлены основные точки.
Все точки в объединении («union») («union») («sourchorities») - это плотность, достижимая из первой точки ядра. Фактически, все точки в объединении доступны по плотности из всех основных точек в объединении.
Все точки в объединении δ-окрестностей также называются связанными плотностью, даже если граничные точки не обязательно доступны друг от друга. Кластер является максимальным набором точек, связанных плотностью, и может иметь произвольную форму.
Точки, которые не являются точками ядра или границами, являются точками шума. Они не принадлежат ни к одному кластеру.
clusterDBSCAN Объект может оценить, используя k-ближайший поиск соседа, или можно задать значения. Чтобы дать объекту оценку, установите EpsilonSource свойство для 'Auto'.
clusterDBSCAN объект может различать данные, содержащие неоднозначности. Диапазон и Доплер являются примерами возможно неоднозначных данных. Набор EnableDisambiguation свойство для true для устранения неоднозначности данных.
Для обнаружения кластеров:
Создать clusterDBSCAN и задайте его свойства.
Вызовите объект с аргументами, как если бы это была функция.
Дополнительные сведения о работе системных объектов см. в разделе Что такое системные объекты?.
clusterer = clusterDBSCANclusterDBSCAN объект, clusterer, объект со значениями свойств по умолчанию.
clusterer = clusterDBSCAN(Name,Value)clusterDBSCAN объект, clusterer, с каждым указанным свойством Name установить в указанное значение Value. Можно указать дополнительные аргументы пары имя-значение в любом порядке как (Name1,Value1,...,NameN,ValueN). Все неопределенные свойства принимают значения по умолчанию. Например,
clusterer = clusterDBSCAN('MinNumPoints',3,'Epsilon',2, ... 'EnableDisambiguation',true,'AmbiguousDimension',[1 2]);
EnableDisambiguation для свойства установлено значение true, а для свойства установлено значение AmbiguousDimension установить в значение [1,2].[ также возвращает альтернативный набор идентификаторов кластера, idx,clusterids] = clusterer(X)clusterids, для использования в phased.RangeEstimator и phased.DopplerEstimator объекты. clusterids присваивает уникальный идентификатор каждой точке шума.
[___] = clusterer( автоматически оценивает эпсилон из матрицы входных данных, X,update)X, когда update имеет значение true. Оценка использует поиск k-NN для создания набора кривых поиска. Дополнительные сведения см. в разделе Оценка Epsilon. Оценка представляет собой среднее из L самых последних значений Эпсилона, где L указано в EpsilonHistoryLength
Чтобы включить этот синтаксис, установите EpsilonSource свойство для 'Auto', при необходимости установите MaxNumPoints , а также дополнительно установить EpsilonHistoryLength собственность.
Чтобы использовать функцию объекта, укажите object™ System в качестве первого входного аргумента. Например, для освобождения системных ресурсов объекта System с именем obj, используйте следующий синтаксис:
release(obj)
Создание обнаружений протяженных объектов с измерениями в диапазоне и доплеровском диапазоне. Предположим, что максимальный однозначный диапазон составляет 20 м, а однозначный доплеровский диапазон простирается от Гц до Гц. Данные для этого примера содержатся в dataClusterDBSCAN.mat файл. Первый столбец матрицы данных представляет диапазон, а второй столбец - доплеровский.
Входные данные содержат следующие расширенные цели и ложные аварийные сигналы:
однозначная цель, расположенная в
неоднозначная мишень в доплеровском диапазоне, находящаяся в 30)
неоднозначная цель по дальности, расположенная в
неоднозначная мишень по дальности и доплеровская, расположенная на
5 ложных тревог
Создать clusterDBSCAN object и укажите, что определение значения не выполняется с помощью параметра EnableDisambiguation кому false. Решить для индексов кластера.
load('dataClusterDBSCAN.mat'); cluster1 = clusterDBSCAN('MinNumPoints',3,'Epsilon',2, ... 'EnableDisambiguation',false); idx = cluster1(x);
Используйте clusterDBSCAN plot объектная функция для отображения кластеров.
plot(cluster1,x,idx)

График показывает, что существует восемь видимых кластеров и шесть точек шума. 'Dimension 1' метка соответствует диапазону и 'Dimension 2' метка соответствует доплеровской.
Далее создайте еще clusterDBSCAN объект и набор EnableDisambiguation кому true чтобы указать, что кластеризация выполняется по границам диапазона и доплеровской неоднозначности.
cluster2 = clusterDBSCAN('MinNumPoints',3,'Epsilon',2, ... 'EnableDisambiguation',true,'AmbiguousDimension',[1 2]);
Выполните кластеризацию с использованием пределов неоднозначности, а затем постройте график результатов кластеризации. Результаты кластеризации DBSCAN правильно показывают четыре кластера и пять точек шума. Например, точки на дальностях, близких к нулю, сгруппированы с точками около 20 м, потому что максимальный однозначный диапазон составляет 20 м.
amblims = [0 maxRange; minDoppler maxDoppler]; idx = cluster2(x,amblims); plot(cluster2,x,idx)

Кластер двумерных декартовых позиционных данных с использованием clusterDBSCAN. Чтобы проиллюстрировать, как выбор эпсилона влияет на кластеризацию, сравните результаты кластеризации с Epsilon установите в значение 1 и Epsilon установите значение 3.
Создание случайных данных положения цели в декартовых координатах xy.
x = [rand(20,2)+12; rand(20,2)+10; rand(20,2)+15];
plot(x(:,1),x(:,2),'.')
Создать clusterDBSCAN объект с Epsilon свойство имеет значение 1 и MinNumPoints свойство имеет значение 3.
clusterer = clusterDBSCAN('Epsilon',1,'MinNumPoints',3);
Кластеризация данных при Epsilon равно 1.
idxEpsilon1 = clusterer(x);
Снова скопируйте данные, но с помощью Epsilon установите значение 3. Можно изменить значение Epsilon потому что это настраиваемое свойство.
clusterer.Epsilon = 3; idxEpsilon2 = clusterer(x);
Постройте график результатов кластеризации бок о бок. Сделать это, передав в осях ручки и заголовки в plot способ. На графике показано, что для Epsilon установлено значение 1, появляются три кластера. Когда Epsilon равно 3, два нижних кластера объединены в один.
hAx1 = subplot(1,2,1); plot(clusterer,x,idxEpsilon1, ... 'Parent',hAx1,'Title','Epsilon = 1') hAx2 = subplot(1,2,2); plot(clusterer,x,idxEpsilon2, ... 'Parent',hAx2,'Title','Epsilon = 3')

Этот раздел иллюстрирует основные принципы формирования кластеров. На рисунке показаны точки в двумерном пространстве элемента. Кластеры компактны и хорошо разделены. Появляется несколько точек шума.
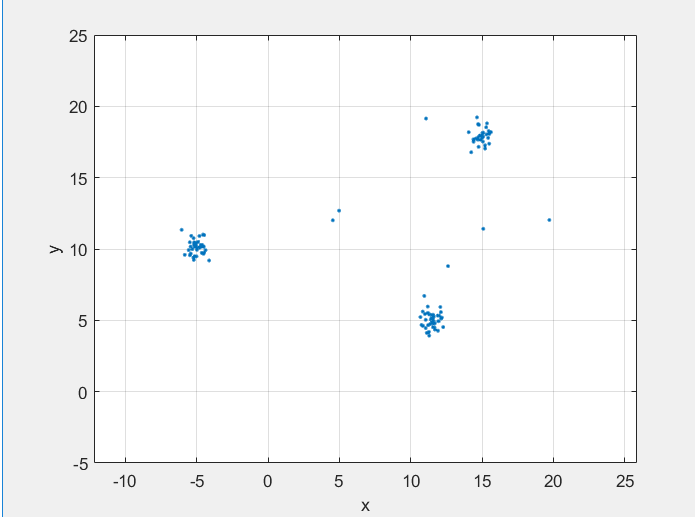
Кластеры начинаются с основных точек. Первым шагом в алгоритме является идентификация всех точек ядра.
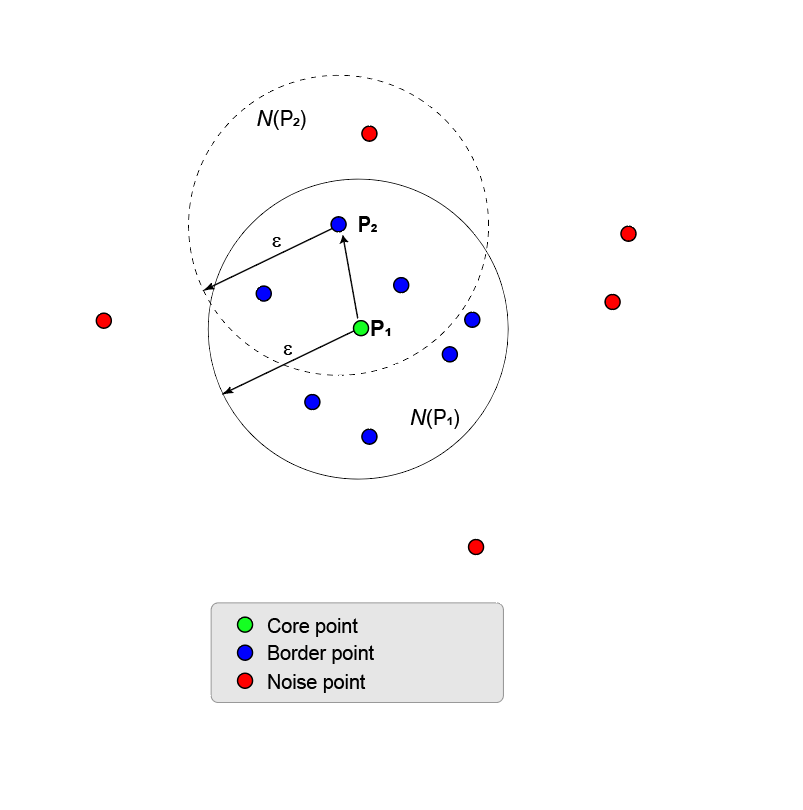
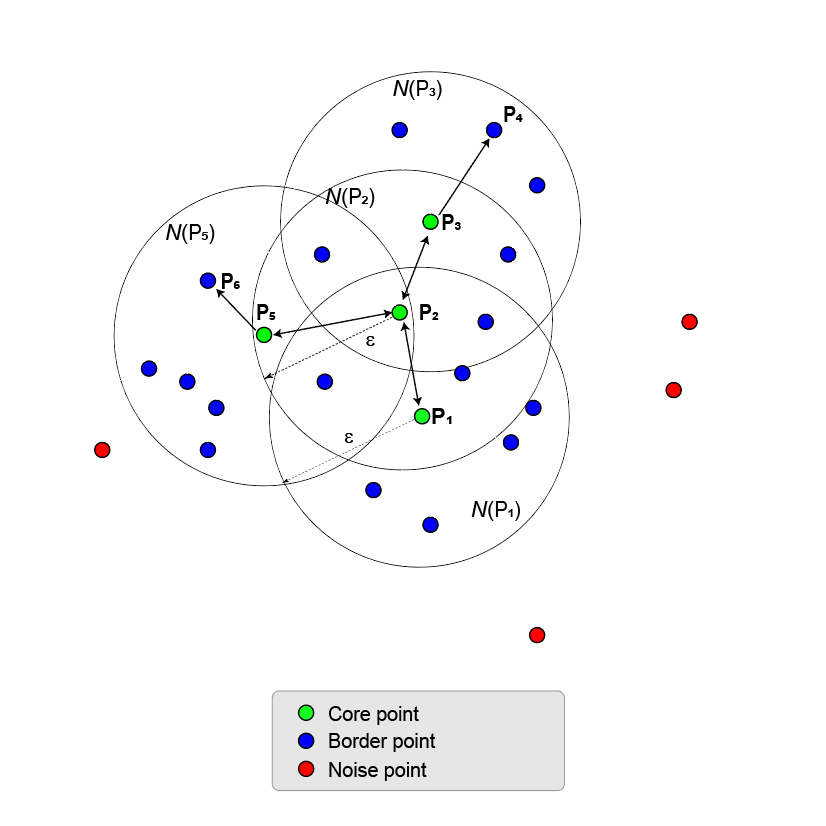
На приведенном здесь рисунке показана точка P1 и окрестность N( P1). Δ-окрестность имеет восемь точек (в том числе и она сама) в радиусе start. Использование MinNumPoints свойство для установки порогового значения 8 означает, что P1 является базовой точкой. Синие точки, лежащие в пределах N, называются пограничными точками. Эти граничные точки непосредственно доступны по плотности из центральной точки P1.
Никакие другие точки на рисунке не имеют достаточного количества соседних точек в их λ-окрестности, чтобы стать центральной точкой. P2 не является основной точкой, поскольку имеет только пять точек в пределах своего района. P2 непосредственно достигается плотность из P1. Обратное не соответствует действительности, поскольку P2 не является основной точкой. Односторонняя стрелка, соединяющая две точки, показывает эту асимметрию.
Пункты, которые выходят за пределы Nε (P1), являются шумовыми (красными) пунктами и не принадлежат группе.
Поскольку никакие другие точки не являются точками ядра, точки ядра и граничные точки являются максимальным набором точек, связанных плотностью, и поэтому образуют кластер.
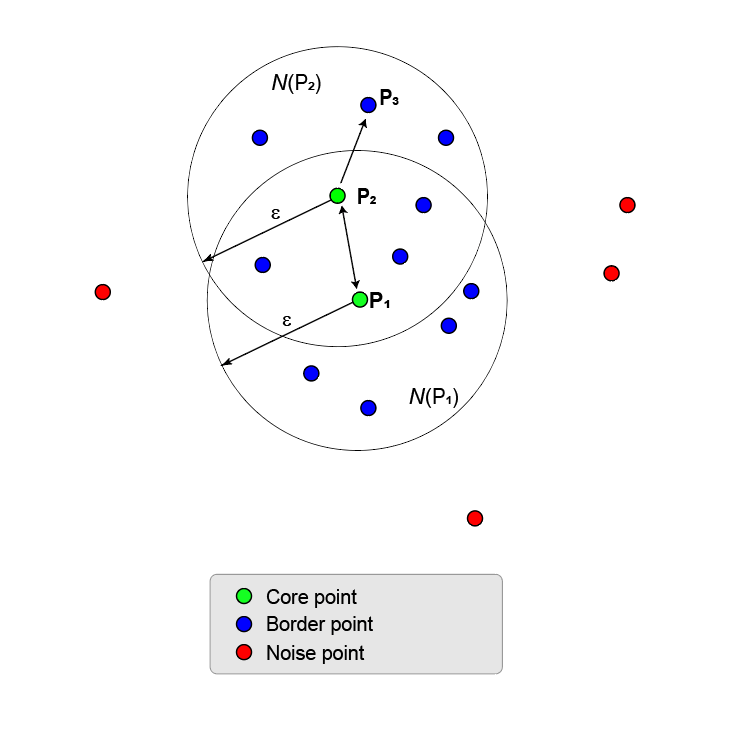
На следующем рисунке показан больший набор точек, содержащий две точки ядра, P1 и P2. P2 является пограничной точкой P1, но P2 также имеет достаточно точек в своем районе, чтобы стать основной точкой. Поскольку они оба являются основными точками, P1 непосредственно достигается плотность из P2, а P1 непосредственно из P2. Двусторонняя стрелка, соединяющая их, показывает эту симметрию.
P3 непосредственно достигается из P2, но не из P1 (как показано односторонней стрелкой). Однако P3 называется просто плотностью, достижимой из P1.
Поскольку никакие другие точки не являются точками ядра, две точки ядра и их граничные точки образуют максимальный набор точек, связанных плотностью, и образуют один кластер.
Этот процесс наращивания кластера может быть расширен от точки ядра к точке ядра до тех пор, пока не будет больше точек ядра для добавления. Точки ядра и граничные точки принадлежат одному кластеру. В общем, точка Pn - это плотность, достижимая из точки P1, когда существует цепь точек ядра, P1,P2, P3,..., Pn-1 такая, что каждая точка ядра Pi + 1 является непосредственно плотностью, достижимой из Pi, и Pn является непосредственно плотностью, достижимой из Pn-1.
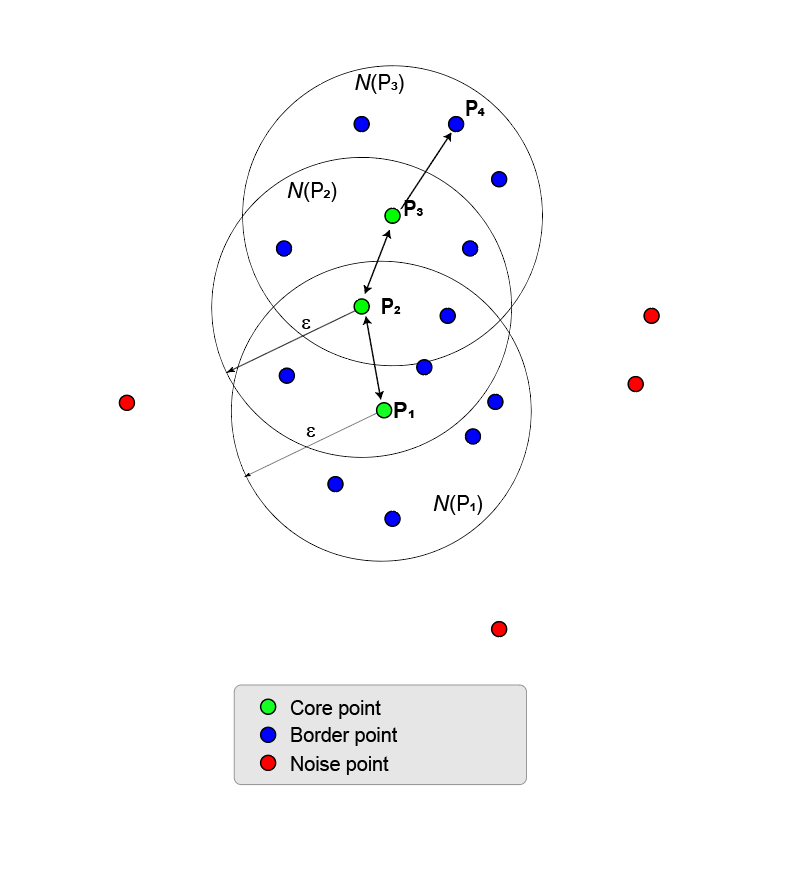
На следующем рисунке показаны некоторые свойства связности плотности.
Кластер может иметь несколько разветвленных цепей, например (P1, P2, P3, P4) и (P1, P2, P5, P6).
Две точки, P6 и P4, соединены по плотности, когда есть третья точка P2 так что P6 и P4 доступны по плотности из P2.
Две точки, связанные с плотностью, необязательно достижимы друг от друга.
Максимальный набор связанных точек плотности определяет кластер. Не имеет значения, какая точка ядра является начальной точкой ядра.
Все точки в кластере доступны по плотности из всех точек ядра.
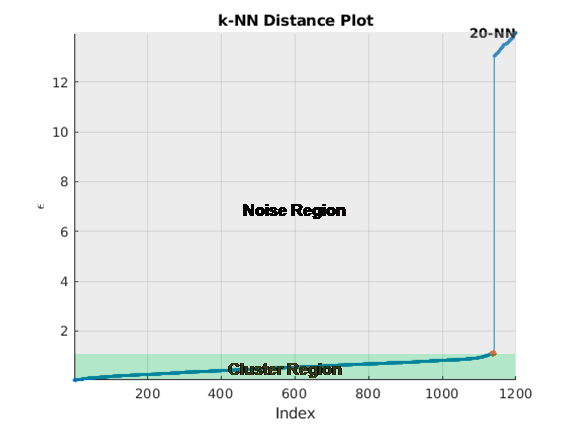
Кластеризация DBSCAN требует значения для параметра размера окрестности start. clusterDBSCAN объект и clusterDBSCAN.estimateEpsilon функция использует поиск k-ближайшего соседа для оценки скалярного эпсилона. Пусть D - расстояние любой точки P до ближайшего соседа. Определите окрестность Dk (P) как окрестность, окружающую P, которая содержит ее k-ближайшие соседи. В окрестности Dk (P) есть k + 1 точек, включая саму точку P. Схема алгоритма оценки:
Для каждой точки найдите все точки в ее окрестности Dk (P)
Накопите расстояния во всех окрестностях Dk (P) для всех точек в один вектор.
Сортировка вектора по увеличению расстояния.
Постройте график отсортированного k-dist, который представляет собой отсортированное расстояние по номеру точки.
Найдите колено кривой. Значение расстояния в этой точке является оценкой эпсилона.
На рисунке показано расстояние, нанесенное на график относительно индекса точки для k = 20. Колено возникает приблизительно при 1,5 ° С. Все точки ниже этого порога принадлежат кластеру. Любые точки выше этого значения являются шумами.
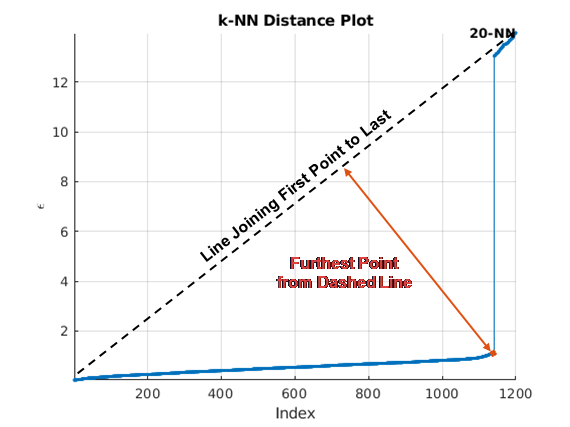
Существует несколько методов поиска колена кривой. clusterDBSCAN и clusterDBSCAN.estimateEpsilon сначала определите линию, соединяющую первую и последнюю точки кривой. Ордината точки на отсортированном k-dist графе, наиболее удаленном от прямой и перпендикулярном прямой, определяет эпсилон.
При задании диапазона значений k алгоритм усредняет оценочные значения эпсилона для всех кривых. Этот рисунок показывает, что эпсилон довольно нечувствителен к k для k в диапазоне от 14 до 19.
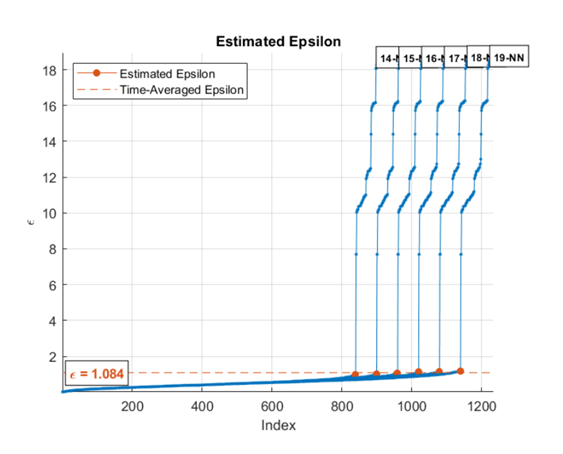
Чтобы создать один график расстояний k-NN, установите значение MinNumPoints свойство, равное MaxNumPoints собственность.
[1] Эстер М., Кригель Х.-П., Сандер Дж. и Сюй Х. «Алгоритм на основе плотности для обнаружения кластеров в больших пространственных базах данных с шумом». Proc. 2nd Int. Conf. on Knowledge Discovery and Data Mining, Portland, OR, AAAI Press, 1996, pp. 226-231.
[2] Эрих Шуберт, Йорг Сандер, Мартин Эстер, Ханс-Петер Кригель и Сяовэй Сюй. 2017. «DBSCAN: повторный доступ, повторный доступ: почему и как следует (по-прежнему) использовать DBSCAN». ACM Trans. Database Syst. 42, 3, статья 19 (июль 2017), 21 стр.
[3] Доминик Келлнер, Йенс Клаппштейн и Клаус Дитмайер, «Сетевой DBSCAN для кластеризации расширенных объектов в радиолокационных данных», симпозиум IEEE Intelligent Vehicles 2012.
[4] Томас Вагнер, Рейнхард Фегер и Андреас Штельцер, «Алгоритм быстрой кластеризации на основе сетки для измерений дальности/доплеровского/DoA», Труды 13-й Европейской конференции радаров.
[5] Михаэль Анкерст, Маркус М. Бреуниг, Ханс-Петер Кригель, Йорг Сандер, "ОПТИКА: Заказ точек для идентификации структуры кластеризации", Proc. ACM SIGMOD "99 Int. Conf. on Management of Data, Philadelphia PA, 1999.
