Оценить порог кластеризации окрестностей
epsilon = clusterDBSCAN.estimateEpsilon(X,MinNumPoints,MaxNumPoints)epsilon, используемый в пространственной кластеризации на основе плотности приложений с алгоритмом шума (DBSCAN ).epsilon вычисляется на основе входных данных X с использованием поиска k-ближайшего соседа (k-NN). MinNumPoints и MaxNumPoints задать диапазон k-значений, для которых вычисляется эпсилон. Диапазон простирается от MinNumPoints - от 1 до MaxNumPoints – 1. k - число соседей точки, которое на единицу меньше числа точек в окрестности.
clusterDBSCAN.estimateEpsilon( отображает рисунок, показывающий кривые поиска k-NN и предполагаемый эпсилон.X,MinNumPoints,MaxNumPoints)
Создайте смоделированные целевые данные и используйте clusterDBSCAN.estimateEpsilon для вычисления соответствующего порога эпсилона.
Создайте целевые данные в виде декартовых координат xy.
X = [randn(20,2) + [11.5,11.5]; randn(20,2) + [25,15]; ...
randn(20,2) + [8,20]; 10*rand(10,2) + [20,20]];Задайте диапазон значений для поиска k-NN.
minNumPoints = 15; maxNumPoints = 20;
Оцените пороговое значение кластеризации epsilon и отобразите его значение на графике.
clusterDBSCAN.estimateEpsilon(X,minNumPoints,maxNumPoints)

Используйте расчетное значение Epsilon, 3,62, в clusterDBSCAN кластер. Затем постройте графики кластеров.
clusterer = clusterDBSCAN('MinNumPoints',6,'Epsilon',3.62, ... 'EnableDisambiguation',false); [idx,cidx] = clusterer(X); plot(clusterer,X,idx)

Кластеризация DBSCAN требует значения для параметра размера окрестности start. clusterDBSCAN объект и clusterDBSCAN.estimateEpsilon функция использует поиск k-ближайшего соседа для оценки скалярного эпсилона. Пусть D - расстояние любой точки P до ближайшего соседа. Определите окрестность Dk (P) как окрестность, окружающую P, которая содержит ее k-ближайшие соседи. В окрестности Dk (P) есть k + 1 точек, включая саму точку P. Схема алгоритма оценки:
Для каждой точки найдите все точки в ее окрестности Dk (P)
Накопите расстояния во всех окрестностях Dk (P) для всех точек в один вектор.
Сортировка вектора по увеличению расстояния.
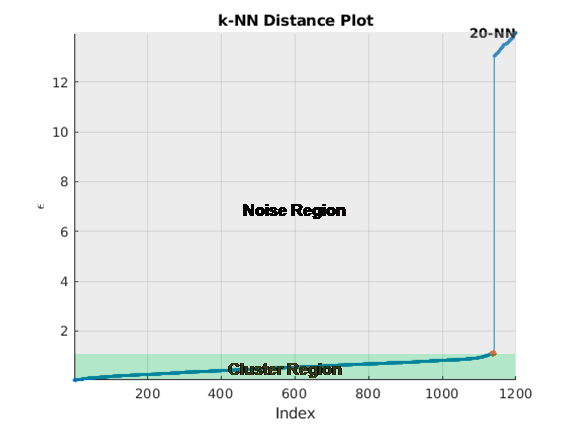
Постройте график отсортированного k-dist, который представляет собой отсортированное расстояние по номеру точки.
Найдите колено кривой. Значение расстояния в этой точке является оценкой эпсилона.
На рисунке показано расстояние, нанесенное на график относительно индекса точки для k = 20. Колено возникает приблизительно при 1,5 ° С. Все точки ниже этого порога принадлежат кластеру. Любые точки выше этого значения являются шумами.
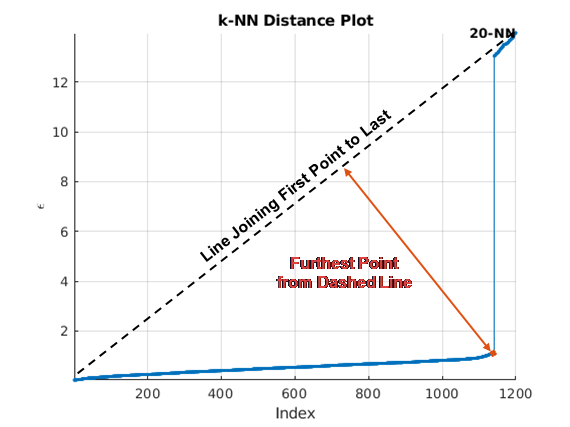
Существует несколько методов поиска колена кривой. clusterDBSCAN и clusterDBSCAN.estimateEpsilon сначала определите линию, соединяющую первую и последнюю точки кривой. Ордината точки на отсортированном k-dist графе, наиболее удаленном от прямой и перпендикулярном прямой, определяет эпсилон.
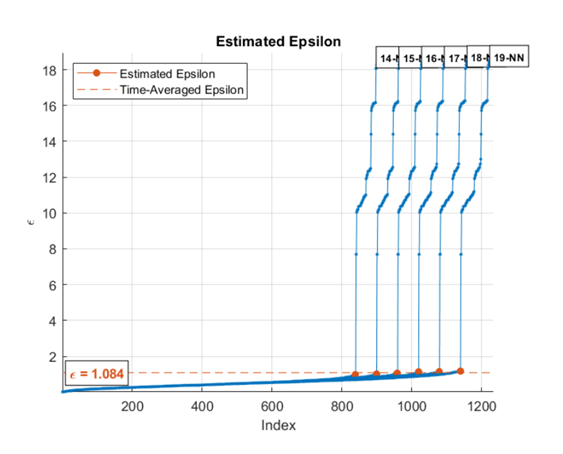
При задании диапазона значений k алгоритм усредняет оценочные значения эпсилона для всех кривых. Этот рисунок показывает, что эпсилон довольно нечувствителен к k для k в диапазоне от 14 до 19.
Чтобы создать один график расстояний k-NN, установите значение MinNumPoints свойство, равное MaxNumPoints собственность.
