В программном обеспечении Ampilation Learning Toolbox™ предусмотрено несколько предварительно определенных сред системы управления, для которых уже определены действия, наблюдения, вознаграждения и динамика. Эти среды можно использовать для:
Изучите концепции обучения усилению.
Познакомьтесь с функциями ПО для обучения по усилению.
Протестируйте собственные агенты обучения усилению.
Следующие предварительно определенные среды системы управления MATLAB ® можно загрузить с помощью rlPredefinedEnv функция.
| Окружающая среда | Задача агента |
|---|---|
| Тележка-столб | Уравновешивание полюса на движущейся тележке путем приложения усилий к тележке с использованием дискретного или непрерывного пространства действия. |
| Двойной интегратор | Управление динамической системой второго порядка с помощью дискретного или непрерывного пространства действия. |
| Простой маятник с наблюдением изображения | Качаться вверх и уравновешивать простой маятник с помощью дискретного или непрерывного пространства действия. |
Также можно загрузить предварительно определенные среды сеток MATLAB. Дополнительные сведения см. в разделе Загрузка предопределенных сред Grid World.
Целью агента в предварительно определенных средах полюсов тележки является уравновешивание полюса на движущейся тележке путем приложения горизонтальных сил к тележке. Полюс считается успешно сбалансированным, если выполняются оба следующих условия:
Угол полюса остается в пределах заданного порога вертикального положения, где вертикальное положение равно нулю радиан.
Величина положения тележки остается ниже заданного порога.
Существует два варианта среды cart-pole, которые отличаются пространством действия агента.
Дискретный - агент может приложить силу Fmax или -Fmax к корзине, где Fmax - MaxForce свойство среды.
Continuous - агент может применять любую силу в пределах диапазона [-Fmax, Fmax].
Для создания среды cart-pole используйте rlPredefinedEnv функция.
Пространство дискретного действия
env = rlPredefinedEnv('CartPole-Discrete');Пространство непрерывного действия
env = rlPredefinedEnv('CartPole-Continuous');Можно визуализировать среду полюса тележки с помощью plot функция. На графике корзина отображается в виде синего квадрата, а полюс - в виде красного прямоугольника.
plot(env)
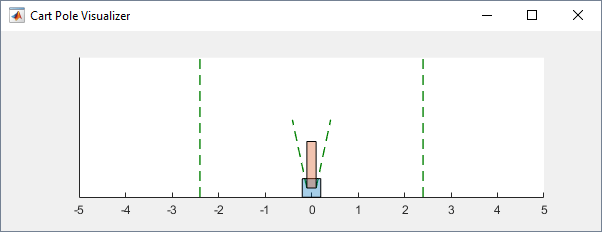
Для визуализации среды во время обучения звоните plot перед тренировкой и держать фигуру визуализации открытой.
Примеры обучения агентов в средах тележек см. в следующих разделах:
| Собственность | Описание | Дефолт |
|---|---|---|
Gravity | Ускорение от силы тяжести в метрах в секунду | 9.8 |
MassCart | Масса тележки в килограммах | 1 |
MassPole | Масса полюса в килограммах | 0.1 |
Length | Половина длины полюса в метрах | 0.5 |
MaxForce | Максимальная величина горизонтальной силы в ньютонах | 10 |
Ts | Время выборки в секундах | 0.02 |
ThetaThresholdRadians | Порог угла полюса в радианах | 0.2094 |
XThreshold | Порог положения корзины в метрах | 2.4 |
RewardForNotFalling | Вознаграждение за каждый временной шаг полюс сбалансирован | 1 |
PenaltyForFalling | Вознаграждение штраф за неспособность сбалансировать столб | Дискретный - Непрерывный - |
State | Состояние среды, указанное как вектор столбца со следующими переменными состояния:
| [0 0 0 0]' |
В средах типа «телега-полюс» агент взаимодействует с окружающей средой с помощью одного сигнала действия - горизонтальной силы, приложенной к телеге. Среда содержит объект спецификации для этого сигнала действия. Для среды с:
Дискретное пространство действия, спецификация является rlFiniteSetSpec объект.
Непрерывное пространство действий, спецификация является rlNumericSpec объект.
Дополнительные сведения о получении спецификаций действий из среды см. в разделе getActionInfo.
В системе тележек агент может наблюдать все переменные состояния окружающей среды в env.State. Для каждой переменной состояния среда содержит rlNumericSpec спецификация наблюдения. Все состояния непрерывны и неограниченны.
Дополнительные сведения о получении спецификаций наблюдения из среды см. в разделе getObservationInfo.
Сигнал вознаграждения для этой среды состоит из двух компонентов.
Положительное вознаграждение за каждый временной шаг, что полюс сбалансирован, то есть тележка и полюс оба остаются в пределах своих заданных пороговых диапазонов. Это вознаграждение накапливается на протяжении всего учебного эпизода. Чтобы контролировать размер этого вознаграждения, используйте RewardForNotFalling свойство среды.
Единовременный отрицательный штраф, если столб или тележка выходят за пределы своего порогового диапазона. В этот момент тренировочный эпизод останавливается. Чтобы контролировать размер этого штрафа, используйте PenaltyForFalling свойство среды.
Целью агента в предварительно определенных средах двойного интегратора является управление положением массы в системе второго порядка посредством применения ввода силы. В частности, система второго порядка представляет собой двойной интегратор с коэффициентом усиления.
Обучающие эпизоды для этих сред заканчиваются, когда происходит одно из следующих событий:
Масса перемещается от начала координат за заданный порог.
Норма вектора состояния меньше заданного порога.
Существуют два варианта среды двойного интегратора, которые отличаются пространством действия агента.
Дискретный - агент может приложить силу Fmax или -Fmax к корзине, где Fmax - MaxForce свойство среды.
Continuous - агент может применять любую силу в пределах диапазона [-Fmax, Fmax].
Чтобы создать среду двойного интегратора, используйте rlPredefinedEnv функция.
Пространство дискретного действия
env = rlPredefinedEnv('DoubleIntegrator-Discrete');Пространство непрерывного действия
env = rlPredefinedEnv('DoubleIntegrator-Continuous');Вы можете визуализировать среду двойного интегратора с помощью plot функция. На графике формообразующий элемент отображается красным прямоугольником.
plot(env)
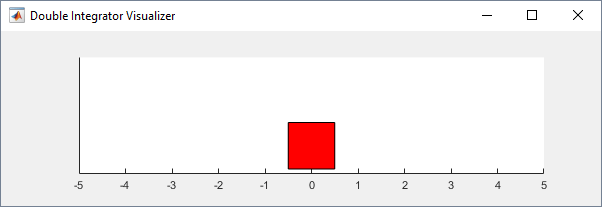
Для визуализации среды во время обучения звоните plot перед тренировкой и держать фигуру визуализации открытой.
Примеры обучения агентов в средах с двойной интеграцией см. в следующих разделах:
| Собственность | Описание | Дефолт |
|---|---|---|
Gain | Выигрыш для двойного интегратора | 1 |
Ts | Время выборки в секундах | 0.1 |
MaxDistance | Порог величины расстояния в метрах | 5 |
GoalThreshold | Порог государственной нормы | 0.01 |
Q | Весовая матрица для компонента наблюдения сигнала вознаграждения | [10 0; 0 1] |
R | Весовая матрица для компонента действия сигнала вознаграждения | 0.01 |
MaxForce | Максимальная входная сила в ньютонах | Дискретные: Непрерывный: |
State | Состояние среды, указанное как вектор столбца со следующими переменными состояния:
| [0 0]' |
В средах двойного интегратора агент взаимодействует с окружающей средой с помощью одного сигнала действия, силы, приложенной к массе. Среда содержит объект спецификации для этого сигнала действия. Для среды с:
Дискретное пространство действия, спецификация является rlFiniteSetSpec объект.
Непрерывное пространство действий, спецификация является rlNumericSpec объект.
Дополнительные сведения о получении спецификаций действий из среды см. в разделе getActionInfo.
В системе двойного интегратора агент может наблюдать обе переменные состояния среды в env.State. Для каждой переменной состояния среда содержит rlNumericSpec спецификация наблюдения. Оба государства непрерывны и неограниченны.
Дополнительные сведения о получении спецификаций наблюдения из среды см. в разделе getObservationInfo.
Сигнал вознаграждения для этой среды представляет собой дискретный временной эквивалент следующего непрерывного временного вознаграждения, который аналогичен функции стоимости контроллера LQR.
dt
Здесь:
Q и R - свойства среды.
x - вектор состояния среды.
u - входная сила.
Эта награда является эпизодической наградой, то есть совокупной наградой по всему обучающему эпизоду.
Эта среда представляет собой простой бесфрикционный маятник, который первоначально висит в нижнем положении. Цель тренировки состоит в том, чтобы сделать маятник стоящим вертикально, не падая при минимальном усилии управления.
Существуют два простых варианта маятниковой среды, которые отличаются пространством действия агента.
Дискретный - Агент может прикладывать крутящий момент -2, -1, 0, 1, или 2 к маятнику.
Непрерывно - Агент может применять любой крутящий момент в пределах диапазона [-2,2].
Для создания простой маятниковой среды используйте rlPredefinedEnv функция.
Пространство дискретного действия
env = rlPredefinedEnv('SimplePendulumWithImage-Discrete');Пространство непрерывного действия
env = rlPredefinedEnv('SimplePendulumWithImage-Continuous');Примеры обучения агента в этой среде см. в следующих разделах:
| Собственность | Описание | Дефолт |
|---|---|---|
Mass | Маятниковая масса | 1 |
RodLength | Длина маятника | 1 |
RodInertia | Маятниковый момент инерции | 0 |
Gravity | Ускорение от силы тяжести в метрах в секунду | 9.81 |
DampingRatio | Демпфирование маятникового движения | 0 |
MaximumTorque | Максимальный входной крутящий момент в ньютонах | 2 |
Ts | Время выборки в секундах | 0.05 |
State | Состояние среды, указанное как вектор столбца со следующими переменными состояния:
| [0 0 ]' |
Q | Весовая матрица для компонента наблюдения сигнала вознаграждения | [1 0;0 0.1] |
R | Весовая матрица для компонента действия сигнала вознаграждения | 1e-3 |
В простых маятниковых средах агент взаимодействует с окружающей средой, используя один сигнал действия, крутящий момент, приложенный к основанию маятника. Среда содержит объект спецификации для этого сигнала действия. Для среды с:
Дискретное пространство действия, спецификация является rlFiniteSetSpec объект.
Непрерывное пространство действий, спецификация является rlNumericSpec объект.
Дополнительные сведения о получении спецификаций действий из среды см. в разделе getActionInfo.
В простой маятниковой среде агент принимает следующие сигналы наблюдения:
изображение положения маятника в градациях серого 50 на 50
Производная угла маятника
Для каждого сигнала наблюдения среда содержит rlNumericSpec спецификация наблюдения. Все наблюдения непрерывны и неограниченны.
Дополнительные сведения о получении спецификаций наблюдения из среды см. в разделе getObservationInfo.
Сигнал вознаграждения для этой среды
θt2+0.1∗θ˙t2+0.001∗ut−12)
Здесь:
startt - угол перемещения маятника из вертикального положения.
- производная угла маятника.
ut-1 - контрольное усилие от предыдущего временного шага.
