В этом примере показано, как проектировать и обучать агента DQN для среды с дискретным пространством действий с помощью Arminitation Learning Designer.
Откройте приложение Egyptioning Designer.
reinforcementLearningDesigner
Первоначально в приложение не загружаются агенты или среды.
При использовании конструктора обучения армированию можно импортировать среду из рабочего пространства MATLAB ® или создать предварительно определенную среду. Дополнительные сведения см. в разделах Создание сред MATLAB для конструктора обучения по армированию и Создание сред Simulink для конструктора обучения по армированию.
В этом примере используется предварительно определенная среда MATLAB с дискретными телегами. Чтобы импортировать эту среду, на вкладке «Обучение армированию» в разделе «Среды» выберите «Создать» > «Дискретная корзина-полюс».
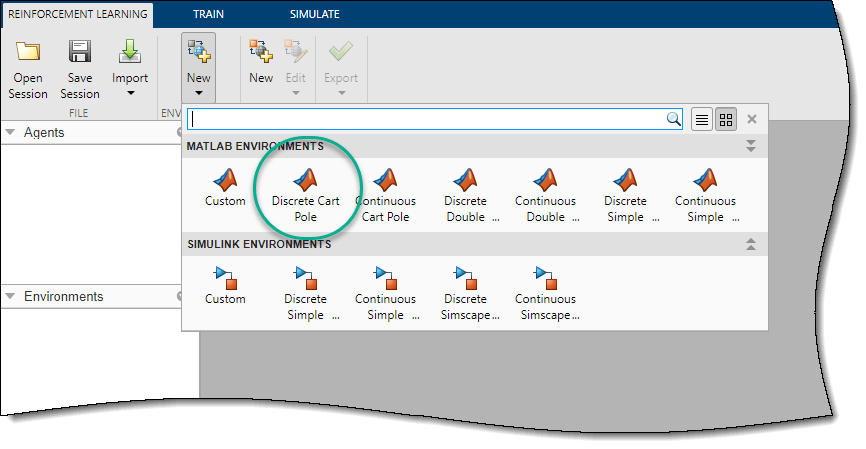
На панели Среды приложение добавляет импортированные Discrete CartPole окружающей среды. Чтобы переименовать среду, щелкните текст среды. В сессии также можно импортировать несколько сред.
Чтобы просмотреть размеры пространства наблюдения и действий, щелкните текст среды. Приложение показывает размеры на панели «Просмотр».
![The Preview pane shows the dimensions of the state and action spaces being [4 1] and [1 1], respectively](app_dqn_cartpole_03b.png)
Эта среда имеет непрерывное четырёхмерное пространство наблюдения (положения и скорости как тележки, так и полюса) и дискретное одномерное пространство действия, состоящее из двух возможных сил, -10N или 10N. Эта среда используется в примере Train DQN Agent to Balance Cart-Pole System. Дополнительные сведения о предопределенных средах системы управления см. в разделе Загрузка предопределенных сред системы управления.
Для создания агента на вкладке «Обучение усилению» в разделе «Агент» нажмите кнопку «Создать». В диалоговом окне Создание агента укажите имя агента, среду и алгоритм обучения. В этом примере следует сохранить конфигурацию агента по умолчанию, использующую импортированную среду и алгоритм DQN. Дополнительные сведения о создании агентов см. в разделе Создание агентов с помощью обучающего конструктора усиления.
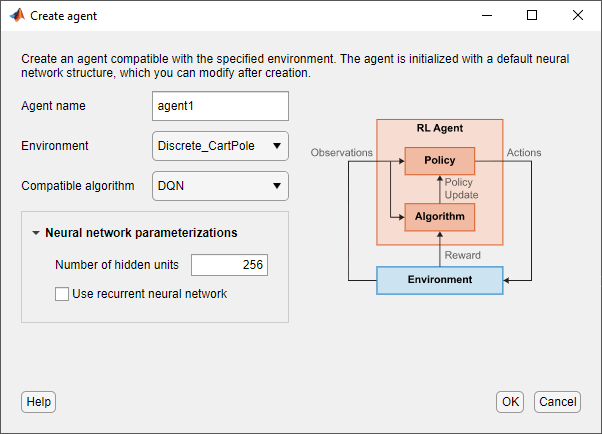
Нажмите кнопку ОК.
Приложение добавляет новый агент на панель Агенты и открывает соответствующий документ Agent_1.
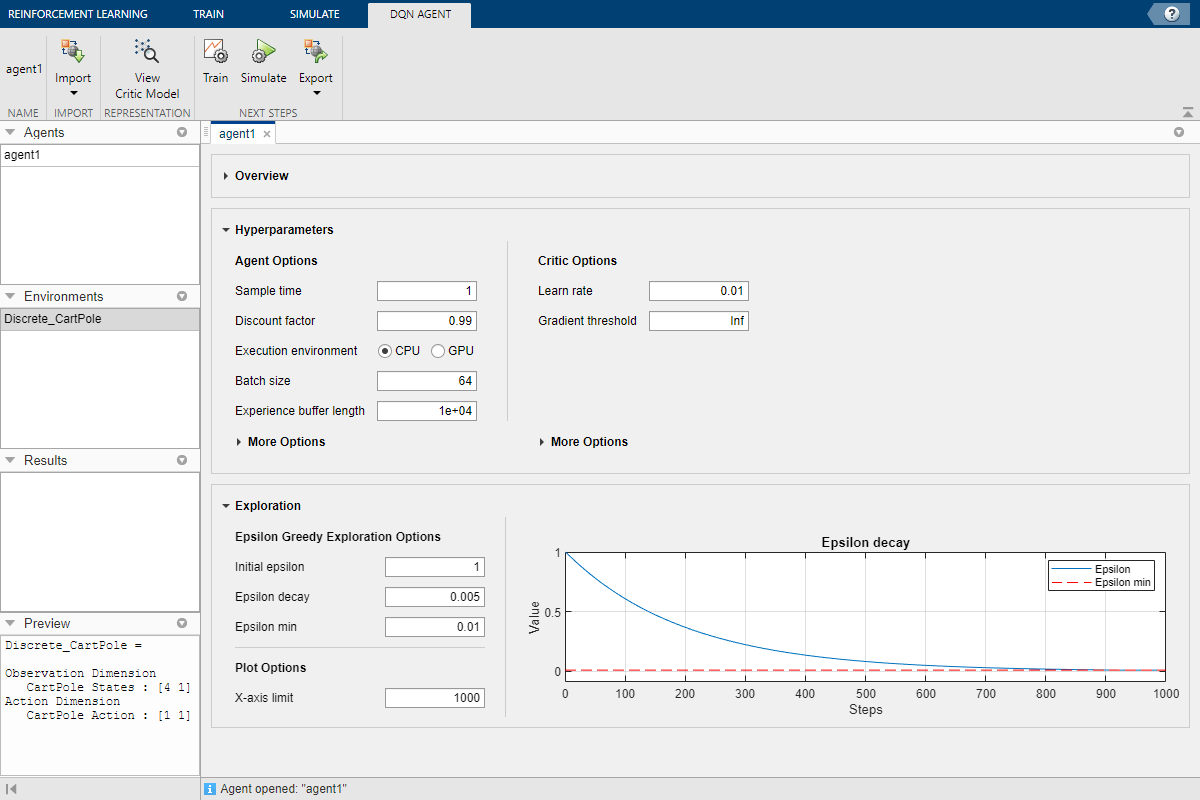
Для получения краткого обзора функций агента DQN и просмотра спецификаций наблюдения и действий для агента щелкните Обзор.
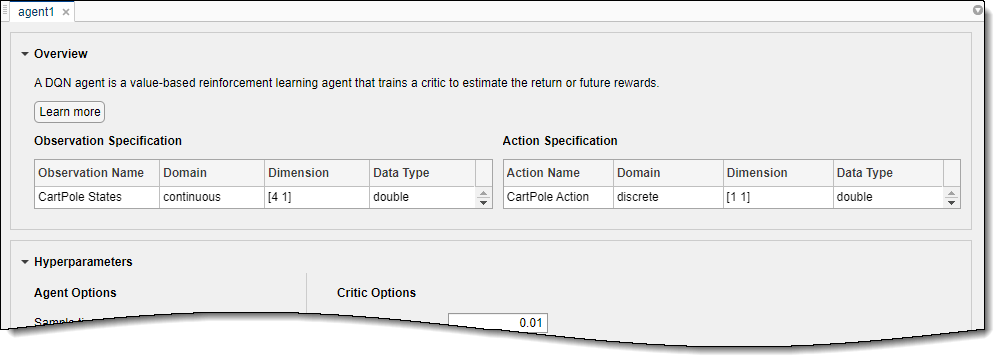
При создании агента DQN в Armigination Learning Designer агент использует структуру глубокой нейронной сети по умолчанию для своего критика. Чтобы просмотреть критическую сеть, на вкладке Агент DQN щелкните Показать критическую модель.
Откроется анализатор сети глубокого обучения, отображающий критическую структуру.
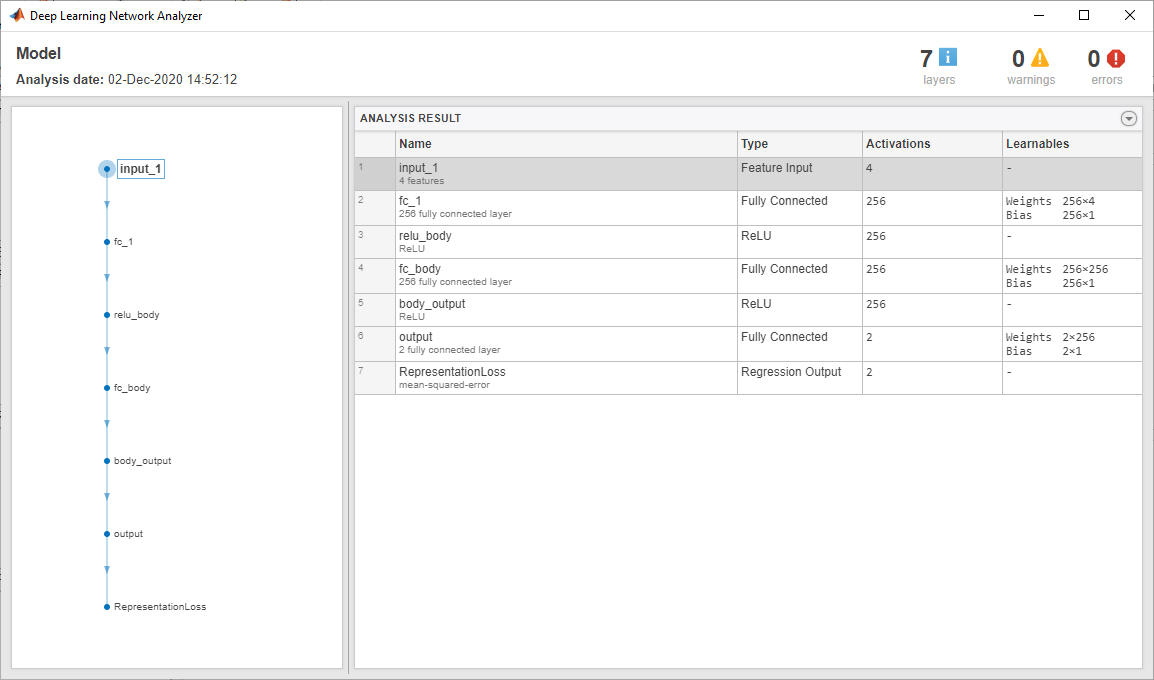
Закройте анализатор сети глубокого обучения.
Чтобы обучить агента, на вкладке Поезд сначала укажите параметры обучения агента. Сведения об указании параметров обучения см. в разделе Задание параметров моделирования в Проектировщике обучения армированию.
В этом примере укажите максимальное количество обучающих эпизодов, установив для параметра «Макс. эпизоды» значение 1000. Для других вариантов обучения используйте их значения по умолчанию. Критерием по умолчанию для остановки является среднее количество шагов на эпизод (за последний 5 эпизоды) больше, чем 500.

Чтобы начать обучение, щелкните Тренировать.
Во время обучения приложение открывает вкладку Сеанс обучения и отображает ход обучения в документе Результаты обучения.
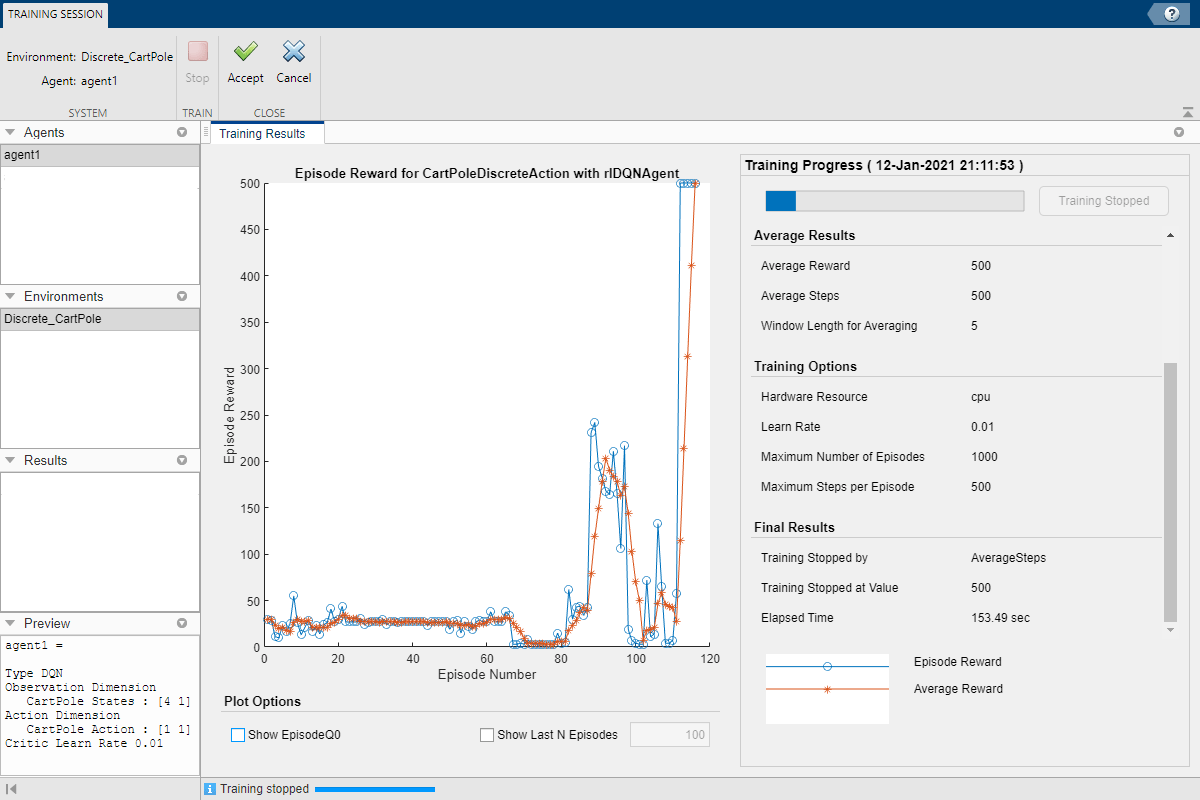
Здесь тренировка прекращается, когда среднее количество шагов за эпизод составляет 500.
Чтобы принять результаты обучения, на вкладке Учебная сессия щелкните Принять. На панели Агенты приложение добавляет обученного агента. agent1_Trained.
Чтобы смоделировать обучаемого агента, на вкладке Смоделировать (Simulate) сначала выберите agent1_Trained в раскрывающемся списке Агент настройте параметры моделирования. В этом примере используется количество эпизодов по умолчанию (10) и максимальная длина эпизода (500). Дополнительные сведения о задании параметров моделирования см. в разделе Определение параметров обучения в Проектировщике обучения по армированию.
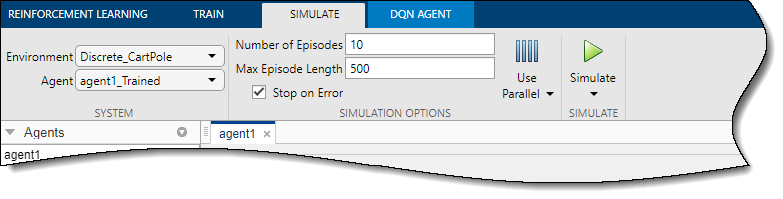
Чтобы смоделировать агента, щелкните Смоделировать (Simulate).
Приложение открывает вкладку Сеанс моделирования. После завершения моделирования в документе Результаты моделирования (Simulation Results) отображается вознаграждение за каждый эпизод, а также среднее и стандартное отклонение вознаграждения.
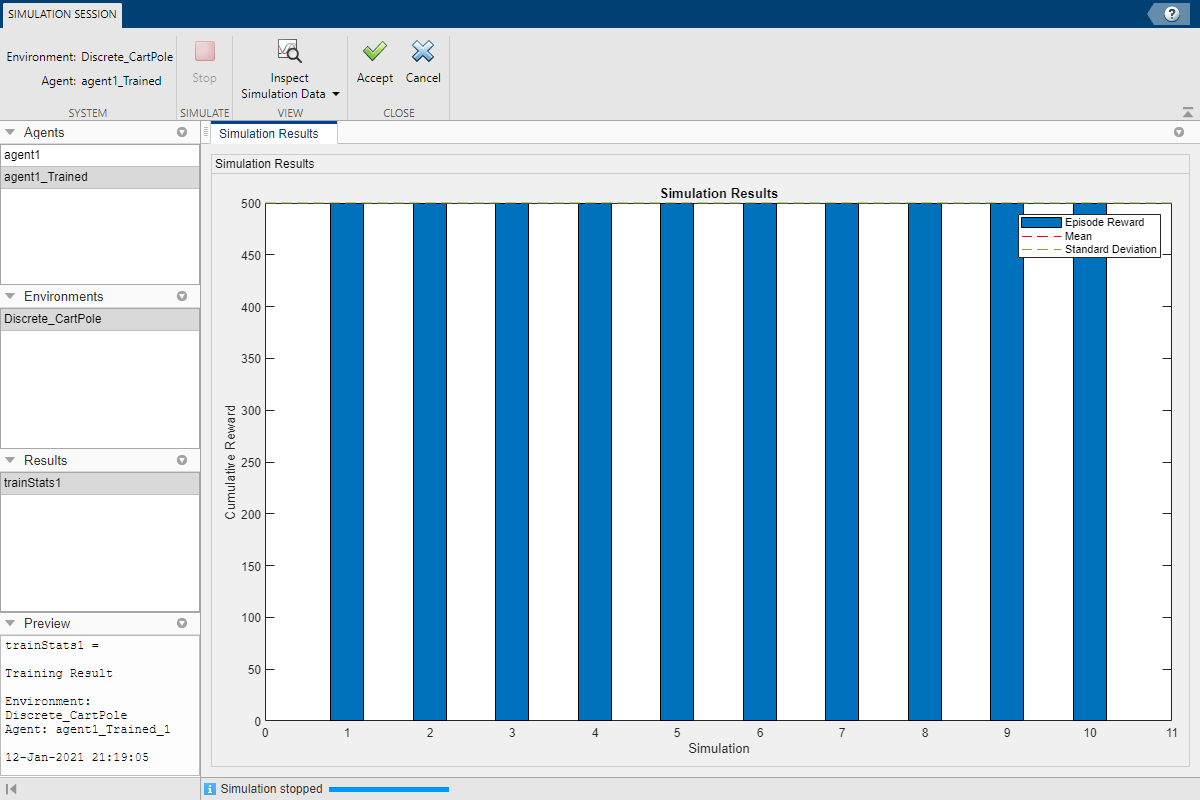
Для анализа результатов моделирования щелкните Проверить данные моделирования (Inspect Simulation Data).
В инспекторе данных моделирования можно просмотреть сохраненные сигналы для каждого эпизода моделирования. На следующем рисунке показаны первое и третье состояния системы телега-полюс (положение тележки и угол полюса) для шестого эпизода моделирования. Агент успешно балансирует полюс с углом, близким к нулю.
Дополнительные сведения см. в разделе Инспектор данных моделирования (Simulation Data Inspector, Simulink).
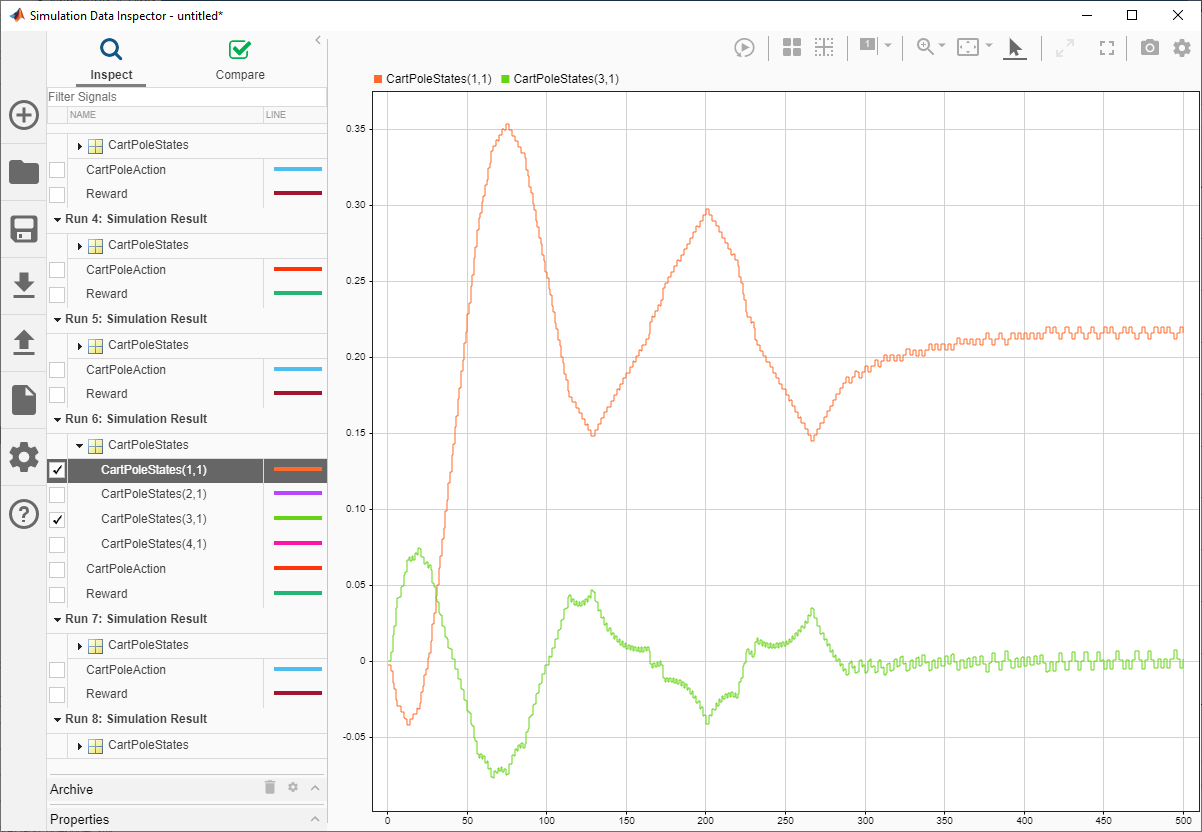
Закройте инспектор данных моделирования.
Чтобы принять результаты моделирования, на вкладке Сеанс моделирования (Simulation Session) щелкните Принять (Accept).
На панели Результаты приложение добавляет структуру результатов моделирования. experience1.
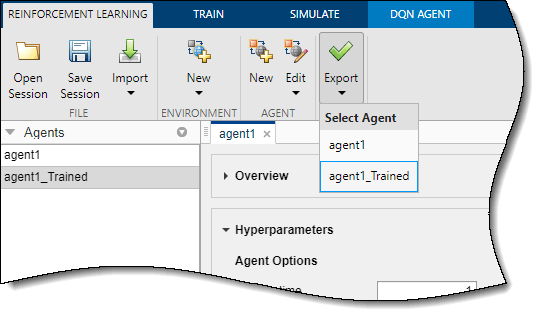
Чтобы экспортировать обученного агента в рабочую область MATLAB для дополнительного моделирования, на вкладке «Обучение армированию» в разделе «Экспорт» выберите агента.
Чтобы сохранить сеанс приложения, на вкладке Обучение усилению щелкните Сохранить сеанс. В будущем, чтобы возобновить работу там, где вы остановились, можно открыть сеанс в Arminitation Learning Designer.
Для моделирования агента в командной строке MATLAB сначала загрузите среду cart-pole.
env = rlPredefinedEnv("CartPole-Discrete");В среде cart-pole имеется визуализатор среды, который позволяет видеть поведение системы во время моделирования и обучения.
Постройте график среды и выполните моделирование с использованием обученного агента, ранее экспортированного из приложения.
plot(env) xpr2 = sim(env,agent1_Trained);
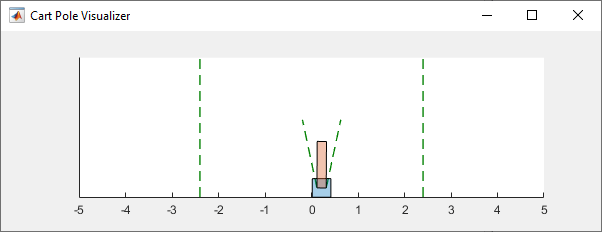
Во время моделирования визуализатор показывает движение тележки и столба. Обученный агент способен быстро стабилизировать систему.
Наконец, просмотрите кумулятивное вознаграждение за моделирование.
sum(xpr2.Reward)
env = 500
Как и ожидалось, вознаграждение составляет до 500.
analyzeNetwork | Дизайнер обучения по усилению
