Многоядерное программирование помогает создавать параллельные системы для развертывания на многоядерных процессорных и многопроцессорных системах. Многоядерная процессорная система - это один процессор с несколькими исполнительными ядрами в одной микросхеме. Напротив, многопроцессорная система имеет несколько процессоров на системной плате или микросхеме. Многопроцессорная система может включать в себя программируемый на местах вентильный массив (FPGA). FPGA - это интегральная схема, содержащая массив программируемых логических блоков и иерархию реконфигурируемых межсоединений. Узел обработки обрабатывает входные данные для получения выходных данных. Это может быть процессор в многоядерной или многопроцессорной системе, или FPGA.
Многоядерный подход к программированию может помочь в следующих случаях:
Вы хотите воспользоваться преимуществами многоядерной обработки и обработки FPGA для повышения производительности встраиваемой системы.
Вы хотите достичь масштабируемости, чтобы развернутая система могла со временем использовать все большее количество ядер и вычислительную мощность FPGA.
Параллельные системы, создаваемые с помощью многоядерного программирования, выполняют несколько задач параллельно. Это называется параллельным выполнением. Когда процессор выполняет несколько параллельных задач, это называется многозадачностью. ЦП имеет микропрограммное обеспечение, называемое планировщиком, который обрабатывает задачи, выполняемые параллельно. ЦП реализует задачи с использованием потоков операционной системы. Задачи могут выполняться независимо, но иметь некоторый перенос данных между ними, например, перенос данных между модулем сбора данных и контроллером системы. Перенос данных между задачами означает наличие зависимости данных.
Многоядерное программирование обычно используется в системах обработки сигналов и управления установкой. При обработке сигналов можно использовать параллельную систему, которая параллельно обрабатывает несколько кадров. В системах управления заводом контроллер и завод могут выполнять как две отдельные задачи. Использование многоядерного программирования помогает разбить систему на несколько параллельных задач, которые выполняются одновременно, ускоряя общее время выполнения.
Сведения о моделировании одновременно выполняемой системы см. в разделе Рекомендации по секционированию.
Концепция многоядерного программирования заключается в параллельном выполнении нескольких системных задач. Типы параллелизма включают в себя:
Параллелизм данных
Параллелизм задач
Конвейерная обработка
Параллелизм данных включает в себя обработку нескольких частей данных независимо друг от друга параллельно. Процессор выполняет одну и ту же операцию над каждой частью данных. Параллельность достигается путем параллельной подачи данных.
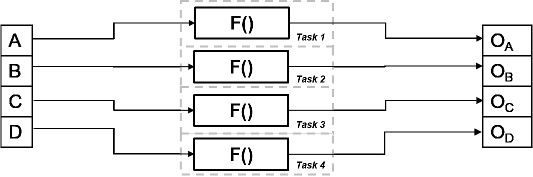
На рисунке показана временная диаграмма для этого параллелизма. Вход разделен на четыре части, A, B, C и D. Та же самая операция F() применяется к каждой из этих частей, и выходом являются OA, OB, OC и OD соответственно. Все четыре задачи идентичны, и они выполняются параллельно.
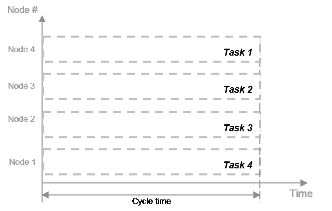
Время, затраченное на цикл процессора, известное как время цикла, равно t = tF.
Общее время обработки также tF, поскольку все четыре задачи выполняются одновременно. В отсутствие параллелизма все четыре части данных обрабатываются одним узлом обработки. Время цикла равно tF для каждой задачи, но общее время обработки составляет 4*tF, так как куски обрабатываются последовательно.
Параллелизм данных можно использовать в сценариях, где можно обрабатывать каждый фрагмент входных данных независимо. Например, веб-база данных с независимыми наборами данных для обработки или обработки кадров видео независимо является хорошим кандидатом для параллелизма данных.
В отличие от параллелизма данных, параллелизм задач не разделяет входные данные. Вместо этого параллелизм достигается путем разделения приложения на несколько задач. Параллелизм задач включает в себя распределение задач внутри приложения по нескольким узлам обработки. Некоторые задачи могут зависеть от других, поэтому все задачи выполняются не одновременно.
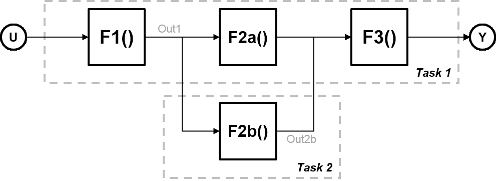
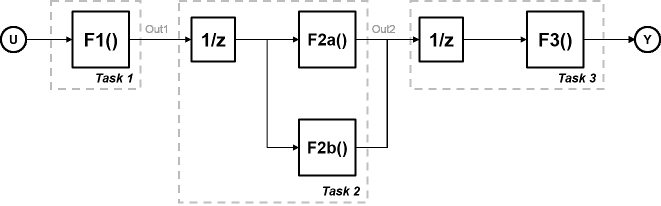
Рассмотрим систему, которая включает четыре функции. Функции F2a () и F2b () параллельны, то есть могут выполняться одновременно. При параллелизме задач можно разделить вычисления на две задачи. Функция F2b () запускается на отдельном узле обработки после того, как она получает данные, Out1 из задачи 1, и выводит обратно в F3 () в задаче 1.
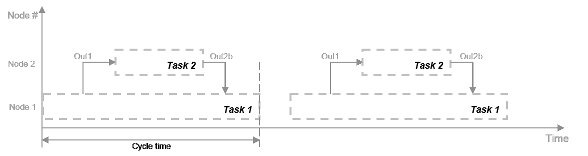
На рисунке показана временная диаграмма для этого параллелизма. Задача 2 не запускается, пока не получит данные, Out1 из задачи 1. Следовательно, эти задачи не выполняются полностью параллельно. Время, затраченное на цикл процессора, известное как время цикла, равно
t = tF1 + max (tF2a, tF2b) + tF3.
Параллелизм задач можно использовать в таких сценариях, как завод, где завод и контроллер работают параллельно.
Используйте выполнение конвейера модели, или конвейерирование, для решения проблемы параллелизма задач, когда потоки не выполняются полностью параллельно. Этот подход включает в себя изменение модели системы для введения задержек между задачами, в которых существует зависимость от данных.
На этом рисунке система разделена на три задачи для выполнения на трех различных узлах обработки с задержками между функциями. На каждом временном шаге каждая задача принимает значение из предыдущего временного шага посредством задержки.
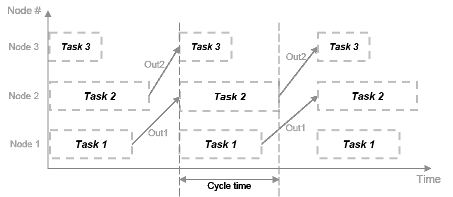
Каждая задача может начать обработку одновременно, как показано на этой временной диаграмме. Эти задачи действительно параллельны и больше не зависят друг от друга в одном цикле процессора. Время цикла не имеет добавлений, но является максимальным временем обработки всех задач.
t = max (Task1, Task2, Task3) = max (tF1, tF2a, tF2b, tF3).
Конвейерная обработка может использоваться везде, где можно искусственно вводить задержки в системе, выполняемой одновременно. Полученные в результате введения накладные расходы не должны превышать времени, сэкономленного за счет конвейерной обработки.
Методы секционирования помогают определить области системы для параллельного выполнения. Секционирование позволяет создавать задачи независимо от специфики целевой системы, на которой развернуто приложение.
Рассмотрим эту систему. F1-F6 - это функции системы, которые могут выполняться независимо. Стрелка между двумя функциями указывает на зависимость данных. Например, выполнение F5 зависит от F3.
Выполнение этих функций назначается различным узлам процессора в целевой системе. Серые стрелки указывают назначение функций, которые должны быть развернуты на CPU или FPGA. Планировщик ЦП определяет, когда выполняются отдельные задачи. CPU и FPGA взаимодействуют по общей шине связи.
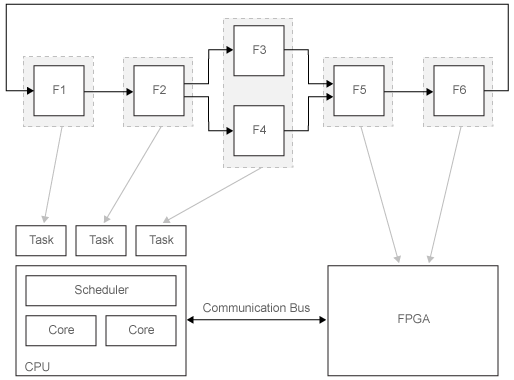
На рисунке показана одна возможная конфигурация для секционирования. Как правило, вы тестируете различные конфигурации и итеративно улучшаете их до тех пор, пока не получите оптимальное распределение задач для вашего приложения.
Ручное кодирование приложения на многоядерном процессоре или FPGA создает проблемы, выходящие за рамки проблем, вызванных ручным кодированием. При параллельном выполнении необходимо отслеживать:
Планирование задач, выполняемых на многоядерном процессоре встроенной системы обработки
Перенос данных в различные узлы обработки и из них
Simulink управляет реализацией задач и передачей данных между задачами. Он также генерирует код, развернутый для приложения. Дополнительные сведения см. в разделе Многоядерное программирование с использованием Simulink.
В дополнение к этим проблемам возникают проблемы при развертывании приложения на различных архитектурах и при необходимости повышения производительности развернутого приложения.
Конфигурация оборудования, в которой выполняется развернутое приложение, называется архитектурой. Он может содержать многоядерные процессоры, многопроцессорные системы, FPGA или их комбинацию. Развертывание одного и того же приложения на различных архитектурах может потребовать усилий из-за:
Различное количество и типы узлов процессора в архитектуре
Стандарты связи и передачи данных для архитектуры
Стандарты для определенных событий, синхронизации и защиты данных в каждой архитектуре
Чтобы развернуть приложение вручную, необходимо переназначить задачи различным узлам обработки для каждой архитектуры. Также может потребоваться повторное внедрение приложения, если в каждой архитектуре используются различные стандарты.
Simulink помогает решить эти проблемы, предлагая переносимость между архитектурами. Дополнительные сведения см. в разделе Как Simulink помогает преодолеть проблемы в многоядерном программировании.
Производительность развернутого приложения можно повысить путем выравнивания нагрузки различных узлов обработки в среде многоядерной обработки. Необходимо выполнить итерацию и улучшить распределение задач во время секционирования, как упомянуто в разделе Системное секционирование для параллелизма. Этот процесс включает перемещение задач между различными узлами обработки и тестирование результирующей производительности. Поскольку это итеративный процесс, требуется время, чтобы найти наиболее эффективное распределение.
Simulink помогает преодолеть эти проблемы с помощью профилирования. Дополнительные сведения см. в разделе Как Simulink помогает преодолеть проблемы в многоядерном программировании.
Некоторые задачи системы зависят от вывода других задач. Зависимость данных между задачами определяет порядок их обработки. Два или более разделов, содержащих зависимости данных в цикле, создают цикл зависимости данных, также известный как алгебраический цикл.
Simulink идентифицирует циклы в системе перед развертыванием. Дополнительные сведения см. в разделе Как Simulink помогает преодолеть проблемы в многоядерном программировании.
