Подгонка модели регрессии гауссова процесса (GPR)
gprMdl = fitrgp(Tbl,ResponseVarName)Tbl, где ResponseVarName - имя переменной ответа в Tbl.
gprMdl = fitrgp(___,Name,Value)Name,Value аргументы пары.
Например, можно указать метод аппроксимации, метод прогнозирования, функцию ковариации или метод выбора активного набора. Можно также обучить модель с перекрестной проверкой.
gprMdl является RegressionGP объект. Методы и свойства этого класса см. в разделе RegressionGP страница класса.
Если вы обучаете перекрестно проверенную модель, то gprMdl является RegressionPartitionedModel объект. Для дальнейшего анализа объекта с перекрестной проверкой используйте методы RegressionPartitionedModel класс. Для получения информации о методах этого класса см. RegressionPartitionedModel страница класса.
В этом примере используются данные abalone [1], [2] из репозитория машинного обучения UCI [3]. Загрузите данные и сохраните их в текущей папке с именем abalone.data.
Сохраните данные в таблице. Просмотрите первые семь строк.
tbl = readtable('abalone.data','Filetype','text',... 'ReadVariableNames',false); tbl.Properties.VariableNames = {'Sex','Length','Diameter','Height',... 'WWeight','SWeight','VWeight','ShWeight','NoShellRings'}; tbl(1:7,:)
ans =
Sex Length Diameter Height WWeight SWeight VWeight ShWeight NoShellRings
___ ______ ________ ______ _______ _______ _______ ________ ____________
'M' 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15
'M' 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7
'F' 0.53 0.42 0.135 0.677 0.2565 0.1415 0.21 9
'M' 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10
'I' 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7
'I' 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 8
'F' 0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 20В наборе данных 4177 наблюдений. Цель - предсказать возраст абалона из восьми физических измерений. Последняя переменная, число оболочечных колец показывает возраст абалона. Первый предиктор - категориальная переменная. Последней переменной в таблице является переменная ответа.
Подгонка модели GPR с использованием метода подмножества регрессоров для оценки параметров и полностью независимого условного метода для прогнозирования. Стандартизируйте предикторы.
gprMdl = fitrgp(tbl,'NoShellRings','KernelFunction','ardsquaredexponential',... 'FitMethod','sr','PredictMethod','fic','Standardize',1)
grMdl =
RegressionGP
PredictorNames: {1x8 cell}
ResponseName: 'Var9'
ResponseTransform: 'none'
NumObservations: 4177
KernelFunction: 'ARDSquaredExponential'
KernelInformation: [1x1 struct]
BasisFunction: 'Constant'
Beta: 10.9148
Sigma: 2.0243
PredictorLocation: [10x1 double]
PredictorScale: [10x1 double]
Alpha: [1000x1 double]
ActiveSetVectors: [1000x10 double]
PredictMethod: 'FIC'
ActiveSetSize: 1000
FitMethod: 'SR'
ActiveSetMethod: 'Random'
IsActiveSetVector: [4177x1 logical]
LogLikelihood: -9.0013e+03
ActiveSetHistory: [1x1 struct]
BCDInformation: []
Спрогнозировать ответы с использованием обученной модели.
ypred = resubPredict(gprMdl);
Постройте график истинного ответа и прогнозируемых ответов.
figure(); plot(tbl.NoShellRings,'r.'); hold on plot(ypred,'b'); xlabel('x'); ylabel('y'); legend({'data','predictions'},'Location','Best'); axis([0 4300 0 30]); hold off;
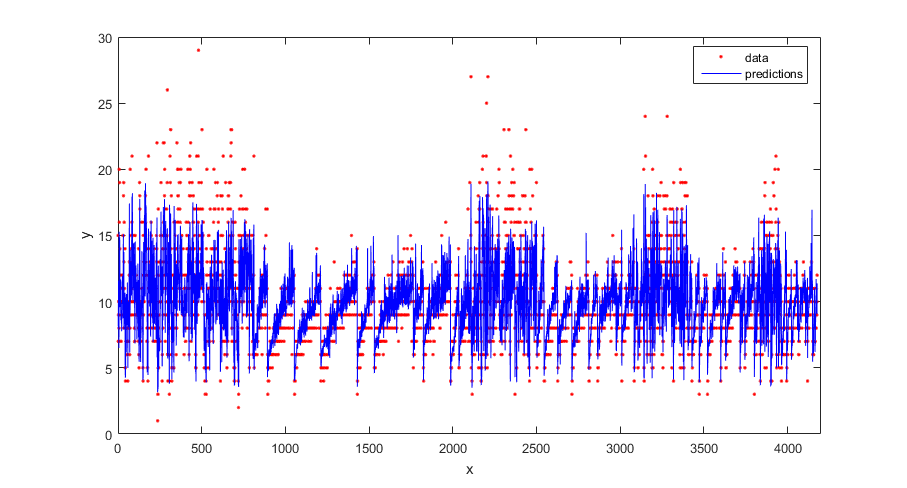
Вычислите регрессионную потерю на обучающих данных (потерю повторного замещения) для обученной модели.
L = resubLoss(gprMdl)
L =
4.0064Создать образец данных.
rng(0,'twister'); % For reproducibility n = 1000; x = linspace(-10,10,n)'; y = 1 + x*5e-2 + sin(x)./x + 0.2*randn(n,1);
Подгонка модели GPR с использованием линейной базисной функции и метода точного подбора для оценки параметров. Также используйте метод точного прогнозирования.
gprMdl = fitrgp(x,y,'Basis','linear',... 'FitMethod','exact','PredictMethod','exact');
Предсказать ответ, соответствующий строкам x (прогнозы повторного замещения) с использованием обученной модели.
ypred = resubPredict(gprMdl);
Постройте график истинной реакции с предсказанными значениями.
plot(x,y,'b.'); hold on; plot(x,ypred,'r','LineWidth',1.5); xlabel('x'); ylabel('y'); legend('Data','GPR predictions'); hold off

Загрузите образцы данных.
load('gprdata2.mat')Данные имеют одну предикторную переменную и непрерывный ответ. Это смоделированные данные.
Поместите модель GPR, используя квадратную экспоненциальную функцию ядра с параметрами ядра по умолчанию.
gprMdl1 = fitrgp(x,y,'KernelFunction','squaredexponential');
Теперь поместите вторую модель, где укажите начальные значения параметров ядра.
sigma0 = 0.2; kparams0 = [3.5, 6.2]; gprMdl2 = fitrgp(x,y,'KernelFunction','squaredexponential',... 'KernelParameters',kparams0,'Sigma',sigma0);
Вычислите прогнозы повторного замещения для обеих моделей.
ypred1 = resubPredict(gprMdl1); ypred2 = resubPredict(gprMdl2);
Постройте график прогнозов ответа от обеих моделей и ответов в данных обучения.
figure(); plot(x,y,'r.'); hold on plot(x,ypred1,'b'); plot(x,ypred2,'g'); xlabel('x'); ylabel('y'); legend({'data','default kernel parameters',... 'kparams0 = [3.5,6.2], sigma0 = 0.2'},... 'Location','Best'); title('Impact of initial kernel parameter values'); hold off
![Figure contains an axes. The axes with title Impact of initial kernel parameter values contains 3 objects of type line. These objects represent data, default kernel parameters, kparams0 = [3.5,6.2], sigma0 = 0.2.](../examples/stats/win64/ImpactofSpecifyingInitialKernelParameterValuesExample_01.png)
Предельная вероятность того, что fitrgp максимизирует для оценки параметров GPR имеет множество локальных решений; решение, к которому он сходится, зависит от начальной точки. Каждое локальное решение соответствует конкретной интерпретации данных. В этом примере решение с исходными параметрами ядра по умолчанию соответствует низкочастотному сигналу с высоким уровнем шума, тогда как второе решение с пользовательскими начальными параметрами ядра соответствует высокочастотному сигналу с низким уровнем шума.
Загрузите образцы данных.
load('gprdata.mat')Существует шесть непрерывных переменных предиктора. В наборе учебных данных 500 наблюдений и 100 наблюдений в наборе тестовых данных. Это смоделированные данные.
Поместите модель GPR с использованием квадратной экспоненциальной функции ядра с отдельной шкалой длины для каждого предиктора. Эта ковариационная функция определяется как:
) 2startm2].
где представляет шкалу длины для предиктора , = 1, 2,..., d и startf - среднеквадратичное отклонение сигнала. Неограниченная параметризация
1 = logstartf.
Инициализировать шкалы длины функции ядра при 10 и среднеквадратических отклонениях сигнала и шума при среднеквадратическом отклонении отклика.
sigma0 = std(ytrain); sigmaF0 = sigma0; d = size(Xtrain,2); sigmaM0 = 10*ones(d,1);
Подгоните модель GPR, используя начальные значения параметров ядра. Стандартизируйте предикторы в данных обучения. Используйте методы точного подбора и прогнозирования.
gprMdl = fitrgp(Xtrain,ytrain,'Basis','constant','FitMethod','exact',... 'PredictMethod','exact','KernelFunction','ardsquaredexponential',... 'KernelParameters',[sigmaM0;sigmaF0],'Sigma',sigma0,'Standardize',1);
Вычислите потери регрессии на тестовых данных.
L = loss(gprMdl,Xtest,ytest)
L = 0.6919
Доступ к информации о ядре.
gprMdl.KernelInformation
ans = struct with fields:
Name: 'ARDSquaredExponential'
KernelParameters: [7x1 double]
KernelParameterNames: {7x1 cell}
Отображение имен параметров ядра.
gprMdl.KernelInformation.KernelParameterNames
ans = 7x1 cell
{'LengthScale1'}
{'LengthScale2'}
{'LengthScale3'}
{'LengthScale4'}
{'LengthScale5'}
{'LengthScale6'}
{'SigmaF' }
Отображение параметров ядра.
sigmaM = gprMdl.KernelInformation.KernelParameters(1:end-1,1)
sigmaM = 6×1
104 ×
0.0004
0.0007
0.0004
5.2709
0.1018
0.0056
sigmaF = gprMdl.KernelInformation.KernelParameters(end)
sigmaF = 28.1721
sigma = gprMdl.Sigma
sigma = 0.8162
Постройте журнал усвоенных шкал длины.
figure() plot((1:d)',log(sigmaM),'ro-'); xlabel('Length scale number'); ylabel('Log of length scale');

Логарифмическая шкала длины для 4-й и 5-й прогнозирующих переменных высока по сравнению с остальными. Эти переменные предиктора, по-видимому, не так влиятельны на ответ, как другие переменные предиктора.
Подгоните модель GPR без использования 4-й и 5-й переменных в качестве переменных предиктора.
X = [Xtrain(:,1:3) Xtrain(:,6)]; sigma0 = std(ytrain); sigmaF0 = sigma0; d = size(X,2); sigmaM0 = 10*ones(d,1); gprMdl = fitrgp(X,ytrain,'Basis','constant','FitMethod','exact',... 'PredictMethod','exact','KernelFunction','ardsquaredexponential',... 'KernelParameters',[sigmaM0;sigmaF0],'Sigma',sigma0,'Standardize',1);
Вычислите ошибку регрессии для данных теста.
xtest = [Xtest(:,1:3) Xtest(:,6)]; L = loss(gprMdl,xtest,ytest)
L = 0.6928
Потеря аналогична той, когда все переменные используются в качестве предикторных переменных.
Вычислите прогнозируемый отклик для тестовых данных.
ypred = predict(gprMdl,xtest);
Постройте график исходного ответа вместе с подходящими значениями.
figure; plot(ytest,'r'); hold on; plot(ypred,'b'); legend('True response','GPR predicted values','Location','Best'); hold off

В этом примере показано, как оптимизировать гиперпараметры автоматически с помощью fitrgp. В примере используется gprdata2 данные, поставляемые с программным обеспечением.
Загрузите данные.
load('gprdata2.mat')Данные имеют одну предикторную переменную и непрерывный ответ. Это смоделированные данные.
Поместите модель GPR, используя квадратную экспоненциальную функцию ядра с параметрами ядра по умолчанию.
gprMdl1 = fitrgp(x,y,'KernelFunction','squaredexponential');
Найдите гиперпараметры, которые минимизируют пятикратные потери при перекрестной проверке, используя автоматическую оптимизацию гиперпараметров.
Для воспроизводимости задайте случайное начальное число и используйте 'expected-improvement-plus' функция приобретения.
rng default gprMdl2 = fitrgp(x,y,'KernelFunction','squaredexponential',... 'OptimizeHyperparameters','auto','HyperparameterOptimizationOptions',... struct('AcquisitionFunctionName','expected-improvement-plus'));
|======================================================================================| | Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Sigma | | | result | log(1+loss) | runtime | (observed) | (estim.) | | |======================================================================================| | 1 | Best | 0.29417 | 4.8721 | 0.29417 | 0.29417 | 0.0015045 | | 2 | Best | 0.037898 | 2.9698 | 0.037898 | 0.060792 | 0.14147 | | 3 | Accept | 1.5693 | 2.2862 | 0.037898 | 0.040633 | 25.279 | | 4 | Accept | 0.29417 | 3.9255 | 0.037898 | 0.037984 | 0.0001091 | | 5 | Accept | 0.29393 | 3.575 | 0.037898 | 0.038029 | 0.029932 | | 6 | Accept | 0.13152 | 3.2312 | 0.037898 | 0.038127 | 0.37127 | | 7 | Best | 0.037785 | 5.189 | 0.037785 | 0.037728 | 0.18116 | | 8 | Accept | 0.03783 | 4.3223 | 0.037785 | 0.036524 | 0.16251 | | 9 | Accept | 0.037833 | 4.9764 | 0.037785 | 0.036854 | 0.16159 | | 10 | Accept | 0.037835 | 5.3911 | 0.037785 | 0.037052 | 0.16072 | | 11 | Accept | 0.29417 | 5.427 | 0.037785 | 0.03705 | 0.00038214 | | 12 | Accept | 0.42256 | 3.4003 | 0.037785 | 0.03696 | 3.2067 | | 13 | Accept | 0.03786 | 3.6868 | 0.037785 | 0.037087 | 0.15245 | | 14 | Accept | 0.29417 | 4.3881 | 0.037785 | 0.037043 | 0.0063584 | | 15 | Accept | 0.42302 | 3.1663 | 0.037785 | 0.03725 | 1.2221 | | 16 | Accept | 0.039486 | 2.6376 | 0.037785 | 0.037672 | 0.10069 | | 17 | Accept | 0.038591 | 3.091 | 0.037785 | 0.037687 | 0.12077 | | 18 | Accept | 0.038513 | 2.4893 | 0.037785 | 0.037696 | 0.1227 | | 19 | Best | 0.037757 | 2.0492 | 0.037757 | 0.037572 | 0.19621 | | 20 | Accept | 0.037787 | 3.169 | 0.037757 | 0.037601 | 0.18068 | |======================================================================================| | Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Sigma | | | result | log(1+loss) | runtime | (observed) | (estim.) | | |======================================================================================| | 21 | Accept | 0.44917 | 2.4079 | 0.037757 | 0.03766 | 8.7818 | | 22 | Accept | 0.040201 | 3.4579 | 0.037757 | 0.037601 | 0.075414 | | 23 | Accept | 0.040142 | 3.7027 | 0.037757 | 0.037607 | 0.087198 | | 24 | Accept | 0.29417 | 5.0095 | 0.037757 | 0.03758 | 0.0031018 | | 25 | Accept | 0.29417 | 5.1286 | 0.037757 | 0.037555 | 0.00019545 | | 26 | Accept | 0.29417 | 4.7136 | 0.037757 | 0.037582 | 0.013608 | | 27 | Accept | 0.29417 | 3.9032 | 0.037757 | 0.037556 | 0.00076147 | | 28 | Accept | 0.42162 | 1.9316 | 0.037757 | 0.037854 | 0.6791 | | 29 | Best | 0.037704 | 2.7232 | 0.037704 | 0.037908 | 0.2367 | | 30 | Accept | 0.037725 | 3.5853 | 0.037704 | 0.037881 | 0.21743 |


__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 140.3815 seconds
Total objective function evaluation time: 110.8067
Best observed feasible point:
Sigma
______
0.2367
Observed objective function value = 0.037704
Estimated objective function value = 0.038223
Function evaluation time = 2.7232
Best estimated feasible point (according to models):
Sigma
_______
0.16159
Estimated objective function value = 0.037881
Estimated function evaluation time = 3.3839
Сравните соответствия перед и после оптимизации.
ypred1 = resubPredict(gprMdl1); ypred2 = resubPredict(gprMdl2); figure(); plot(x,y,'r.'); hold on plot(x,ypred1,'b'); plot(x,ypred2,'k','LineWidth',2); xlabel('x'); ylabel('y'); legend({'data','Initial Fit','Optimized Fit'},'Location','Best'); title('Impact of Optimization'); hold off

В этом примере используются данные abalone [1], [2] из репозитория машинного обучения UCI [3]. Загрузите данные и сохраните их в текущей папке с именем abalone.data.
Сохранение данных в table. Просмотрите первые семь строк.
tbl = readtable('abalone.data','Filetype','text','ReadVariableNames',false); tbl.Properties.VariableNames = {'Sex','Length','Diameter','Height','WWeight','SWeight','VWeight','ShWeight','NoShellRings'}; tbl(1:7,:)
ans =
Sex Length Diameter Height WWeight SWeight VWeight ShWeight NoShellRings
___ ______ ________ ______ _______ _______ _______ ________ ____________
'M' 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15
'M' 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7
'F' 0.53 0.42 0.135 0.677 0.2565 0.1415 0.21 9
'M' 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10
'I' 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7
'I' 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12 8
'F' 0.53 0.415 0.15 0.7775 0.237 0.1415 0.33 20В наборе данных 4177 наблюдений. Цель - предсказать возраст абалона из восьми физических измерений. Последняя переменная, число оболочечных колец показывает возраст абалона. Первый предиктор - категориальная переменная. Последней переменной в таблице является переменная ответа.
Обучение перекрестно проверенной модели GPR с использованием 25% данных для проверки.
rng('default') % For reproducibility cvgprMdl = fitrgp(tbl,'NoShellRings','Standardize',1,'Holdout',0.25);
Вычислите средние потери на складках, используя модели, обученные на нестандартных наблюдениях.
kfoldLoss(cvgprMdl)
ans = 4.6409
Спрогнозировать ответы для устаревших данных.
ypred = kfoldPredict(cvgprMdl);
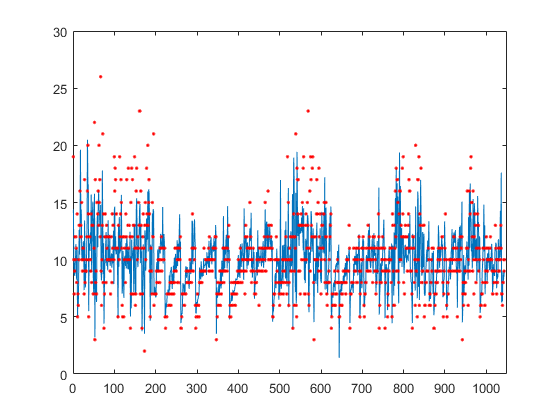
Постройте график истинных ответов, используемых для тестирования, и прогнозов.
figure(); plot(ypred(cvgprMdl.Partition.test)); hold on; y = table2array(tbl(:,end)); plot(y(cvgprMdl.Partition.test),'r.'); axis([0 1050 0 30]); xlabel('x') ylabel('y') hold off;
Создайте образец данных.
rng(0,'twister'); % For reproducibility n = 1000; x = linspace(-10,10,n)'; y = 1 + x*5e-2 + sin(x)./x + 0.2*randn(n,1);
Определите квадратную экспоненциальную функцию ядра как пользовательскую функцию ядра.
Можно вычислить квадратную экспоненциальную функцию ядра как
xi-xj) startl2),
где - среднеквадратичное отклонение сигнала, - шкала длины. И , и должны быть больше нуля. Это условие может быть проведено в жизнь добровольной параметризацией, (1)) (2)), для некоторого добровольного вектора параметризации θ.
Следовательно, можно определить квадратную экспоненциальную функцию ядра как пользовательскую функцию ядра следующим образом:
kfcn = @(XN,XM,theta) (exp(theta(2))^2)*exp(-(pdist2(XN,XM).^2)/(2*exp(theta(1))^2));
Здесь pdist2(XN,XM).^2 вычисляет матрицу расстояний.
Поместите модель GPR с помощью пользовательской функции ядра, kfcn. Укажите начальные значения параметров ядра (Поскольку используется пользовательская функция ядра, необходимо указать начальные значения для неограниченного вектора параметризации, theta).
theta0 = [1.5,0.2]; gprMdl = fitrgp(x,y,'KernelFunction',kfcn,'KernelParameters',theta0);
fitrgp использует аналитические производные для оценки параметров при использовании встроенной функции ядра, тогда как при использовании пользовательской функции ядра использует числовые производные.
Вычислите потерю повторного замещения для этой модели.
L = resubLoss(gprMdl)
L = 0.0391
Подгоните модель GPR с помощью опции встроенной возведенной в квадрат экспоненциальной функции ядра. Укажите начальные значения параметров ядра (поскольку вы используете встроенную пользовательскую функцию ядра и указываете начальные значения параметров, вы должны предоставить начальные значения для стандартного отклонения сигнала и шкалы (шкал) длины ).
sigmaL0 = exp(1.5); sigmaF0 = exp(0.2); gprMdl2 = fitrgp(x,y,'KernelFunction','squaredexponential','KernelParameters',[sigmaL0,sigmaF0]);
Вычислите потерю повторного замещения для этой модели.
L2 = resubLoss(gprMdl2)
L2 = 0.0391
Значения двух потерь совпадают с ожидаемыми.
Обучить модель GPR сгенерированным данным со многими предикторами. Укажите начальный размер шага для оптимизатора LBFGS.
Задайте начальное число и тип генератора случайных чисел для воспроизводимости результатов.
rng(0,'twister'); % For reproducibility
Создайте данные выборки с 300 наблюдениями и 3000 предикторами, где переменная ответа зависит от 4, 7 и 13 предикторов.
N = 300; P = 3000; X = rand(N,P); y = cos(X(:,7)) + sin(X(:,4).*X(:,13)) + 0.1*randn(N,1);
Установите начальные значения для параметров ядра.
sigmaL0 = sqrt(P)*ones(P,1); % Length scale for predictors sigmaF0 = 1; % Signal standard deviation
Установить начальное среднеквадратичное отклонение шума в 1.
sigmaN0 = 1;
Определить 1e-2 в качестве допуска окончания для нормы относительного градиента.
opts = statset('fitrgp');
opts.TolFun = 1e-2;Подгонка модели GPR с использованием начальных значений параметров ядра, начального среднеквадратического отклонения шума и функции автоматического определения релевантности (ARD) в квадрате экспоненциального ядра.
Укажите начальный размер шага как 1 для определения начального гессенского приближения для оптимизатора LBFGS.
gpr = fitrgp(X,y,'KernelFunction','ardsquaredexponential','Verbose',1, ... 'Optimizer','lbfgs','OptimizerOptions',opts, ... 'KernelParameters',[sigmaL0;sigmaF0],'Sigma',sigmaN0,'InitialStepSize',1);
o Parameter estimation: FitMethod = Exact, Optimizer = lbfgs
o Solver = LBFGS, HessianHistorySize = 15, LineSearchMethod = weakwolfe
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 0 | 3.004966e+02 | 2.569e+02 | 0.000e+00 | | 3.893e-03 | 0.000e+00 | YES |
| 1 | 9.525779e+01 | 1.281e+02 | 1.003e+00 | OK | 6.913e-03 | 1.000e+00 | YES |
| 2 | 3.972026e+01 | 1.647e+01 | 7.639e-01 | OK | 4.718e-03 | 5.000e-01 | YES |
| 3 | 3.893873e+01 | 1.073e+01 | 1.057e-01 | OK | 3.243e-03 | 1.000e+00 | YES |
| 4 | 3.859904e+01 | 5.659e+00 | 3.282e-02 | OK | 3.346e-03 | 1.000e+00 | YES |
| 5 | 3.748912e+01 | 1.030e+01 | 1.395e-01 | OK | 1.460e-03 | 1.000e+00 | YES |
| 6 | 2.028104e+01 | 1.380e+02 | 2.010e+00 | OK | 2.326e-03 | 1.000e+00 | YES |
| 7 | 2.001849e+01 | 1.510e+01 | 9.685e-01 | OK | 2.344e-03 | 1.000e+00 | YES |
| 8 | -7.706109e+00 | 8.340e+01 | 1.125e+00 | OK | 5.771e-04 | 1.000e+00 | YES |
| 9 | -1.786074e+01 | 2.323e+02 | 2.647e+00 | OK | 4.217e-03 | 1.250e-01 | YES |
| 10 | -4.058422e+01 | 1.972e+02 | 6.796e-01 | OK | 7.035e-03 | 1.000e+00 | YES |
| 11 | -7.850209e+01 | 4.432e+01 | 8.335e-01 | OK | 3.099e-03 | 1.000e+00 | YES |
| 12 | -1.312162e+02 | 3.334e+01 | 1.277e+00 | OK | 5.432e-02 | 1.000e+00 | YES |
| 13 | -2.005064e+02 | 9.519e+01 | 2.828e+00 | OK | 5.292e-03 | 1.000e+00 | YES |
| 14 | -2.070150e+02 | 1.898e+01 | 1.641e+00 | OK | 6.817e-03 | 1.000e+00 | YES |
| 15 | -2.108086e+02 | 3.793e+01 | 7.685e-01 | OK | 3.479e-03 | 1.000e+00 | YES |
| 16 | -2.122920e+02 | 7.057e+00 | 1.591e-01 | OK | 2.055e-03 | 1.000e+00 | YES |
| 17 | -2.125610e+02 | 4.337e+00 | 4.818e-02 | OK | 1.974e-03 | 1.000e+00 | YES |
| 18 | -2.130162e+02 | 1.178e+01 | 8.891e-02 | OK | 2.856e-03 | 1.000e+00 | YES |
| 19 | -2.139378e+02 | 1.933e+01 | 2.371e-01 | OK | 1.029e-02 | 1.000e+00 | YES |
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 20 | -2.151111e+02 | 1.550e+01 | 3.015e-01 | OK | 2.765e-02 | 1.000e+00 | YES |
| 21 | -2.173046e+02 | 5.856e+00 | 6.537e-01 | OK | 1.414e-02 | 1.000e+00 | YES |
| 22 | -2.201781e+02 | 8.918e+00 | 8.484e-01 | OK | 6.381e-03 | 1.000e+00 | YES |
| 23 | -2.288858e+02 | 4.846e+01 | 2.311e+00 | OK | 2.661e-03 | 1.000e+00 | YES |
| 24 | -2.392171e+02 | 1.190e+02 | 6.283e+00 | OK | 8.113e-03 | 1.000e+00 | YES |
| 25 | -2.511145e+02 | 1.008e+02 | 1.198e+00 | OK | 1.605e-02 | 1.000e+00 | YES |
| 26 | -2.742547e+02 | 2.207e+01 | 1.231e+00 | OK | 3.191e-03 | 1.000e+00 | YES |
| 27 | -2.849931e+02 | 5.067e+01 | 3.660e+00 | OK | 5.184e-03 | 1.000e+00 | YES |
| 28 | -2.899797e+02 | 2.068e+01 | 1.162e+00 | OK | 6.270e-03 | 1.000e+00 | YES |
| 29 | -2.916723e+02 | 1.816e+01 | 3.213e-01 | OK | 1.415e-02 | 1.000e+00 | YES |
| 30 | -2.947674e+02 | 6.965e+00 | 1.126e+00 | OK | 6.339e-03 | 1.000e+00 | YES |
| 31 | -2.962491e+02 | 1.349e+01 | 2.352e-01 | OK | 8.999e-03 | 1.000e+00 | YES |
| 32 | -3.004921e+02 | 1.586e+01 | 9.880e-01 | OK | 3.940e-02 | 1.000e+00 | YES |
| 33 | -3.118906e+02 | 1.889e+01 | 3.318e+00 | OK | 1.213e-01 | 1.000e+00 | YES |
| 34 | -3.189215e+02 | 7.086e+01 | 3.070e+00 | OK | 8.095e-03 | 1.000e+00 | YES |
| 35 | -3.245557e+02 | 4.366e+00 | 1.397e+00 | OK | 2.718e-03 | 1.000e+00 | YES |
| 36 | -3.254613e+02 | 3.751e+00 | 6.546e-01 | OK | 1.004e-02 | 1.000e+00 | YES |
| 37 | -3.262823e+02 | 4.011e+00 | 2.026e-01 | OK | 2.441e-02 | 1.000e+00 | YES |
| 38 | -3.325606e+02 | 1.773e+01 | 2.427e+00 | OK | 5.234e-02 | 1.000e+00 | YES |
| 39 | -3.350374e+02 | 1.201e+01 | 1.603e+00 | OK | 2.674e-02 | 1.000e+00 | YES |
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 40 | -3.379112e+02 | 5.280e+00 | 1.393e+00 | OK | 1.177e-02 | 1.000e+00 | YES |
| 41 | -3.389136e+02 | 3.061e+00 | 7.121e-01 | OK | 2.935e-02 | 1.000e+00 | YES |
| 42 | -3.401070e+02 | 4.094e+00 | 6.224e-01 | OK | 3.399e-02 | 1.000e+00 | YES |
| 43 | -3.436291e+02 | 8.833e+00 | 1.707e+00 | OK | 5.231e-02 | 1.000e+00 | YES |
| 44 | -3.456295e+02 | 5.891e+00 | 1.424e+00 | OK | 3.772e-02 | 1.000e+00 | YES |
| 45 | -3.460069e+02 | 1.126e+01 | 2.580e+00 | OK | 3.907e-02 | 1.000e+00 | YES |
| 46 | -3.481756e+02 | 1.546e+00 | 8.142e-01 | OK | 1.565e-02 | 1.000e+00 | YES |
Infinity norm of the final gradient = 1.546e+00
Two norm of the final step = 8.142e-01, TolX = 1.000e-12
Relative infinity norm of the final gradient = 6.016e-03, TolFun = 1.000e-02
EXIT: Local minimum found.
o Alpha estimation: PredictMethod = Exact
Поскольку модель GPR использует ядро ARD со многими предикторами, использование приближения LBFGS к гессенскому является более эффективной памятью, чем хранение полной матрицы Гессена. Кроме того, использование начального размера шага для определения начального гессенского приближения может помочь ускорить оптимизацию.
Найдите веса предиктора, взяв экспоненту отрицательных усвоенных шкал длины. Нормализуйте веса.
sigmaL = gpr.KernelInformation.KernelParameters(1:end-1); % Learned length scales weights = exp(-sigmaL); % Predictor weights weights = weights/sum(weights); % Normalized predictor weights
Постройте график нормированных предикторных весов.
figure; semilogx(weights,'ro'); xlabel('Predictor index'); ylabel('Predictor weight');

Обученная модель GPR присваивает наибольшие веса 4-му, 7-му и 13-му предикторам. Неактуальные предикторы имеют веса, близкие к нулю.
fitrgp принимает любую комбинацию методов подбора, прогнозирования и выбора активного набора. В некоторых случаях может оказаться невозможным вычислить стандартные отклонения прогнозируемых откликов, следовательно, интервалы прогнозирования. Посмотрите predict. И в некоторых случаях использование точного метода может быть дорогостоящим из-за размера данных обучения.
PredictorNames свойство сохраняет один элемент для каждого из исходных имен переменных предиктора. Например, если существует три предиктора, один из которых является категориальной переменной с тремя уровнями, PredictorNames представляет собой массив символьных векторов типа «1 на 3».
ExpandedPredictorNames свойство сохраняет один элемент для каждой из переменных предиктора, включая фиктивные переменные. Например, если существует три предиктора, один из которых является категориальной переменной с тремя уровнями, то ExpandedPredictorNames представляет собой массив символьных векторов 1 на 5 ячеек.
Аналогично, Beta свойство хранит один бета-коэффициент для каждого предиктора, включая фиктивные переменные.
X свойство сохраняет данные обучения в том виде, в каком они были первоначально введены. Он не включает фиктивные переменные.
Подход по умолчанию к инициализации гессенского приближения в fitrgp может быть медленным при использовании модели GPR с множеством параметров ядра, например, при использовании ядра ARD со множеством предикторов. В этом случае рассмотрите возможность указания 'auto' или значение начального размера шага.
Можно задать 'Verbose',1 для отображения итеративных диагностических сообщений и начать обучение модели GPR с использованием оптимизатора LBFGS или квазиньютоновского оптимизатора по умолчанию fitrgp оптимизация. Если итеративные диагностические сообщения не отображаются через несколько секунд, возможно, что инициализация гессенского приближения занимает слишком много времени. В этом случае рекомендуется перезапустить обучение и использовать начальный размер шага для ускорения оптимизации.
После обучения модели можно создать код C/C + +, который предсказывает ответы на новые данные. Для создания кода C/C + + требуется Coder™ MATLAB. Дополнительные сведения см. в разделе Введение в создание кода.
Подбор модели GPR включает оценку следующих параметров модели на основе данных:
Ковариационная функция xj 'start), параметризованная в терминах параметров ядра в (см. Параметры функции ядра (ковариации))
Шумовая дисперсия,
Вектор коэффициентов фиксированных базисных функций,
Значение 'KernelParameters' аргумент пары «имя-значение» - вектор, состоящий из начальных значений для среднеквадратичного отклонения сигнале, а также шкал характеристических длин («» length «»). fitrgp функция использует эти значения для определения параметров ядра. Аналогично, 'Sigma' Аргумент пары «имя-значение» содержит начальное значение для среднеквадратичного отклонения шума.
Во время оптимизации, fitrgp создает вектор из неограниченных значений начальных параметров, начальные значения для среднеквадратического отклонения шума и параметров ядра.
fitrgp аналитически определяет явные базисные коэффициенты , определенные 'Beta' аргумент пары "имя-значение", из оценочных значений " Поэтому не появляется в векторе, когда fitrgp инициализирует численную оптимизацию.
Примечание
При отсутствии оценки параметров для модели GPR fitrgp использует значение 'Beta' аргумент пары имя-значение и другие начальные значения параметров в качестве известных значений параметров GPR (см. Beta). Во всех остальных случаях значение 'Beta' аргумент оптимизируется аналитически из целевой функции.
Квазиньютоновский оптимизатор использует метод доверительной области с плотным, симметричным рангом-1 на основе (SR1), квазиньютоновское приближение к гессенскому, в то время как LBFGS оптимизатор использует стандартный метод поиска линий с ограниченной памятью Бройдена-Флетчера-Гольдфарба-Шанно (Lanno См. Нокедаль и Райт [6].
Если установить 'InitialStepSize' аргумент пары имя-значение для 'auto', fitrgp определяет начальный размер шага, s0‖∞, с помощью s0‖∞=0.5‖η0‖∞+0.1.
- начальный пошаговый вектор, - вектор неограниченных значений начальных параметров.
Во время оптимизации, fitrgp использует начальный размер шага, s0‖∞, следующим образом:
Если вы используете 'Optimizer','quasinewton' при начальном размере шага тогда начальное гессенское приближение равно g0‖∞‖s0‖∞I.
Если вы используете 'Optimizer','lbfgs' при начальном размере шага тогда начальное обратногессенское приближение равно s0‖∞‖g0‖∞I.
- начальный градиентный вектор, а - единичная матрица.
[1] Нэш, У. Джей, Т. Л. Селлерс, С. Р. Толбот, А. Дж. Коуторн и У. Б. Форд. "Популяционная биология Абалоне (вид Haliotis) в Тасмании. И. Блэклип Абалоне (Х. рубра) с Северного побережья и островов Бассова пролива ". Отдел морского рыболовства, Технический доклад № 48, 1994 год.
[2] Во, С. «Расширение и сравнительный анализ каскадной корреляции: расширение каскадно-корреляционной архитектуры и сравнительный анализ искусственных нейронных сетей, находящихся под контролем Feed-Forward». Факультет компьютерных наук Тасманийского университета, 1995 год.
[3] Лихман, M. UCI Machine Learning Repository, Ирвайн, Калифорния: Калифорнийский университет, Школа информации и компьютерных наук, 2013. http://archive.ics.uci.edu/ml.
[4] Расмуссен, К. Э. и К. К. И. Уильямс. Гауссовы процессы машинного обучения. Пресс MIT. Кембридж, Массачусетс, 2006.
[5] Лагариас, Дж. С., Дж. А. Ридс, М. Х. Райт и П. Э. Райт. «Свойства сходимости метода Nelder-Mead Simplex в малых размерах». Журнал оптимизации SIAM. Том 9, номер 1, 1998, стр. 112-147.
[6] Nocedal, J. и С. Дж. Райт. Численная оптимизация, второе издание. Springer Series in Operations Research, Springer Verlag, 2006.
