Класс: RegingGP
Модель регрессии гауссова процесса с перекрестной проверкой
cvMdl = crossval(gprMdl)
cvmdl = crossval(gprMdl,Name,Value)
cvMdl = crossval(gprMdl)cvMdl, построенный на основе модели регрессии гауссова процесса (GPR), gprMdl, используя 10-кратную перекрестную проверку.
cvmdl является RegressionPartitionedModel объект, и gprMdl является RegressionGP (полный) объект.
cvmdl = crossval(gprMdl,Name,Value)cvmdl, с дополнительными опциями, указанными одним или несколькими Name,Value аргументы пары. Например, можно указать количество складок или долю данных для тестирования.
Загрузите данные по жилью [1] из репозитория машинного обучения UCI [4].
В наборе данных 506 наблюдений. Первые 13 столбцов содержат предикторные значения, а последний столбец содержит ответные значения. Цель состоит в том, чтобы предсказать медианную стоимость домов, занятых владельцами в пригородном Бостоне, в зависимости от 13 предикторов.
Загрузите данные и определите вектор отклика и матрицу предиктора.
load('housing.data');
X = housing(:,1:13);
y = housing(:,end);
Поместите модель GPR с использованием квадратной экспоненциальной функции ядра с отдельной шкалой длины для каждого предиктора. Стандартизация переменных предиктора.
gprMdl = fitrgp(X,y,'KernelFunction','ardsquaredexponential','Standardize',1);
Создайте раздел перекрестной проверки для данных, используя предиктор 4 в качестве переменной группировки.
rng('default') % For reproducibility cvp = cvpartition(X(:,4),'kfold',10);
Создание 10-кратной перекрестной проверенной модели с использованием секционированных данных в cvp.
cvgprMdl = crossval(gprMdl,'CVPartition',cvp);
Вычислите потерю регрессии для кратных наблюдений, используя модели, обученные на внеплановых наблюдениях.
L = kfoldLoss(cvgprMdl)
L =
9.5299Предсказать реакцию на кратные наблюдения, т.е. наблюдения, не используемые для обучения.
ypred = kfoldPredict(cvgprMdl);
Для каждого раза, kfoldPredict прогнозирует ответы для наблюдений в этом масштабе с использованием моделей, обученных на внеплановых наблюдениях.
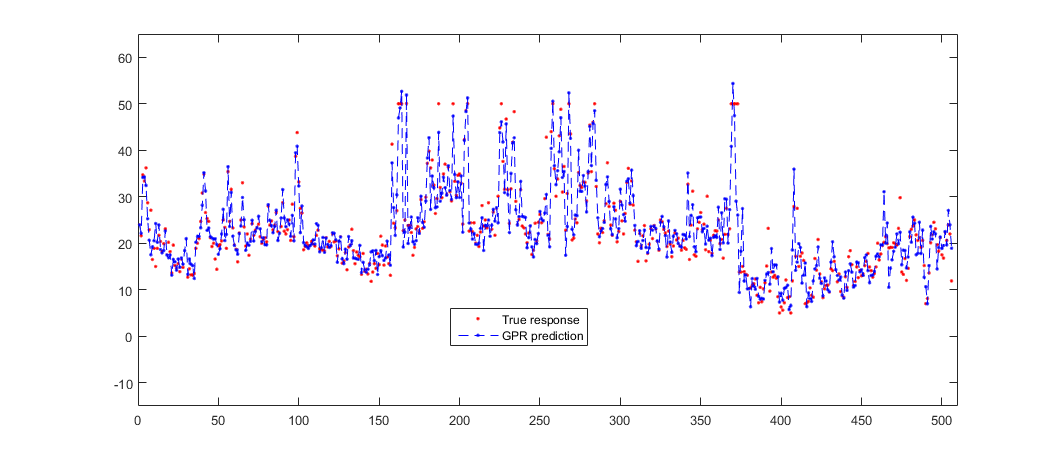
Постройте график фактических откликов и данных прогнозирования.
plot(y,'r.'); hold on; plot(ypred,'b--.'); axis([0 510 -15 65]); legend('True response','GPR prediction','Location','Best'); hold off;
Загрузите данные abalone [2], [3] из репозитория машинного обучения UCI [4] и сохраните их в текущем каталоге с именем abalone.data.
Считывание данных в table.
tbl = readtable('abalone.data','Filetype','text','ReadVariableNames',false);
В наборе данных 4177 наблюдений. Цель - предсказать возраст абалона из 8 физических измерений.
Подогнать модель GPR с использованием подмножества регрессоров (sr) метод оценки параметров и полностью независимый условный (fic) способ прогнозирования. Стандартизируйте предикторы и используйте квадратную экспоненциальную функцию ядра с отдельной шкалой длины для каждого предиктора.
gprMdl = fitrgp(tbl,tbl(:,end),'KernelFunction','ardsquaredexponential',... 'FitMethod','sr','PredictMethod','fic','Standardize',1);
Перекрестная проверка модели с использованием четырехкратной перекрестной проверки. При этом данные разделяются на 4 набора. Для каждого аппарата, fitrgp использует этот набор (25% данных) в качестве тестовых данных и обучает модель на оставшихся 3 наборах (75% данных).
rng('default') % For reproducibility cvgprMdl = crossval(gprMdl,'KFold',4);
Вычислите потери по отдельным складкам.
L = kfoldLoss(cvgprMdl,'mode','individual')
L =
4.3669
4.6896
4.0565
4.3162Вычислите среднюю перекрестную проверенную потерю по всем складкам. Значением по умолчанию является среднеквадратичная ошибка.
L2 = kfoldLoss(cvgprMdl)
L2 =
4.3573
Это равно средней потере по отдельным складкам.
mse = mean(L)
mse =
4.3573
Одновременно можно использовать только один из аргументов пары имя-значение.
Невозможно вычислить интервалы прогнозирования для перекрестно проверенной модели.
Можно также обучить модель с перекрестной проверкой, используя связанные аргументы пары имя-значение в fitrgp.
Если вы предоставляете пользовательский 'ActiveSet' в вызове для fitrgp, то нельзя выполнить перекрестную проверку модели GPR.
[1] Харрисон, Д. и Д. Л., Рубинфельд. «Гедонические цены и спрос на чистый воздух». Дж. Энвирон. Экономика и управление. Vol.5, 1978, стр. 81-102.
[2] Нэш, У. Джей, Т. Л. Селлерс, С. Р. Толбот, А. Дж. Коуторн и У. Б. Форд. "Популяционная биология Абалоне (вид Haliotis) в Тасмании. И. Блэклип Абалоне (Х. рубра) с Северного побережья и островов Бассова пролива ". Отдел морского рыболовства, Технический доклад № 48, 1994 год.
[3] Во, С. «Расширение и сравнительный анализ каскадной корреляции: расширение каскадно-корреляционной архитектуры и сравнительный анализ искусственных нейронных сетей, находящихся под контролем Feed-Forward». Факультет компьютерных наук Тасманийского университета, 1995 год.
[4] Лихман, M. UCI Machine Learning Repository, Ирвайн, Калифорния: Калифорнийский университет, Школа информации и компьютерных наук, 2013. http://archive.ics.uci.edu/ml.
fitrgp | kfoldLoss | kfoldPredict | RegressionGP | RegressionPartitionedModel
