Сравнение предиктивной точности двух классификационных моделей
testcholdout статистически оценивает точность двух классификационных моделей. Функция сначала сравнивает их предсказанные метки с истинными метками, а затем обнаруживает, является ли разница между показателями неправильной классификации статистически значимой.
Можно оценить, отличается ли точность классификационных моделей или одна классификационная модель работает лучше другой. testcholdout может проводить несколько вариаций теста МакНемара, включая асимптотический тест, точно-условный тест и тест среднего p-значения. Для оценки с учетом затрат доступные тесты включают тест хи-квадрат (требуется лицензия Optimization Toolbox™) и тест отношения правдоподобия.
h = testcholdout(YHat1,YHat2,Y)YHat1 и YHat2 имеют одинаковую точность для прогнозирования меток истинного класса Y. Альтернативная гипотеза заключается в том, что метки имеют неравную точность.
h = 1 указывает на отклонение нулевой гипотезы на уровне значимости 5%. h = 0 указывает, что не отклонять нулевую гипотезу на уровне 5%.
h = testcholdout(YHat1,YHat2,Y,Name,Value)Name,Value аргументы пары. Например, можно указать тип альтернативной гипотезы, указать тип теста или предоставить матрицу затрат.
Тесты Макнемара - это тесты гипотез, которые сравнивают две пропорции популяции, решая при этом проблемы, возникающие в результате двух зависимых, согласованных пар выборок.
Одним из способов сравнения прогностической точности двух классификационных моделей является:
Разбейте данные на обучающие и тестовые наборы.
Обучение обеих моделей классификации с использованием обучающего набора.
Спрогнозировать метки классов с помощью тестового набора.
Сведите результаты в таблицу «два на два», аналогичную этой диаграмме.
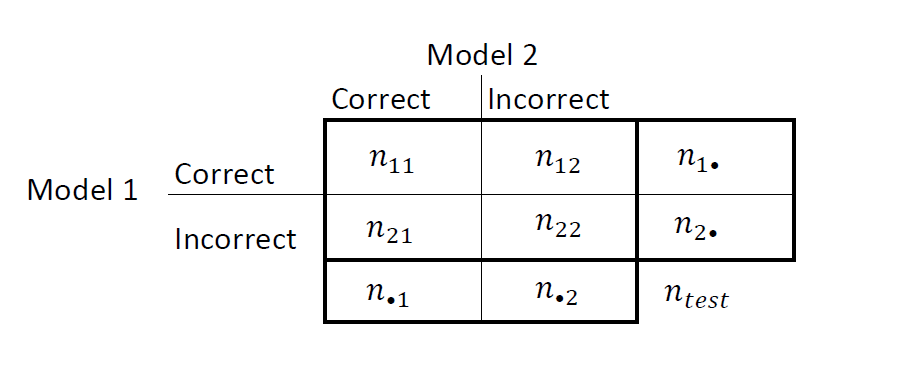
nii - количество совпадающих пар, то есть количество наблюдений, которые обе модели классифицируют одинаково (правильно или неправильно). nij, i ≠ j, - количество дискордантных пар, то есть количество наблюдений, которые модели классифицируют по-разному (правильно или неправильно).
Коэффициенты неправильной классификации для Моделей 1 и 2 составляют n2 •/2 = n • 2/n соответственно. Двусторонний тест для сравнения точности двух моделей
Нулевая гипотеза предполагает, что популяция проявляет маргинальную однородность, что сводит нулевую гипотезу к security21. Также при нулевой гипотезе N12 ~ Биномиал (n12 + n21,0,5) [1].
Эти факты являются основой для доступных вариантов теста Макнемара: асимптотических, точно-условных и среднезначных тестов Макнемара. Следующие определения суммируют доступные варианты.
Асимптотическая - асимптотическая статистика теста МакНемара и области отклонения (для уровня значимости α):
Для односторонних тестов статистика теста равна
Если < α, где Startявляется стандартным гауссовым cdf, то отклоните H0.
Для двусторонних тестов статистика теста равна
Если ) < α, (x; m) - cdf, вычисленный при x, то отклонить H0.
Асимптотический тест требует теории больших выборок, в частности, гауссова аппроксимации к биномиальному распределению.
Общее число несогласованных пар, n21, должно быть больше 10 ([1], Ch. 10,1,4).
В целом асимптотические тесты не гарантируют номинального покрытия. Наблюдаемая вероятность ложного отклонения нулевой гипотезы может превышать α, как предложено в имитационных исследованиях в [18]. Однако асимптотический тест Макнемара хорошо работает с точки зрения статистической мощности.
Точная - условная - точная условная статистика теста Макнемара и области отклонения (для уровня значимости α) являются ([36], [38]):
Для односторонних тестов статистика теста равна
Если < α, n, p) является биномиальным cdf с размером выборки n и вероятностью успеха p, оцененной при x, то отклонить H0.
Для двусторонних тестов статистика теста равна
).
Если α/2, то отклоните H0.
Точный условный тест всегда достигает номинального покрытия. Исследования моделирования в [18] показывают, что тест является консервативным, а затем показывают, что тест не обладает статистической мощностью по сравнению с другими вариантами. Для небольших или очень дискретных испытательных образцов рекомендуется использовать испытание среднего значения p ([1], гл. 3.6.3).
Тест среднего p-значения - статистика теста среднего p-значения McNemar и области отклонения (для уровня значимости α) являются ([32]):
Для односторонних тестов статистика теста равна
Если t1∗;n12+n21,0.5) < α, (x; nfBin (x; n, p) являются биномиальными cdf и pdf соответственно с размером выборки n и вероятностью успеха p, оцененной при x, то отклонить H0.
Для двусторонних тестов статистика теста равна
).
Если < α/2, то отбраковать H0.
Тест среднего p-значения обращается к чрезмерно консервативному поведению теста точного условия. Исследования моделирования в [18] показывают, что этот тест достигает номинального охвата и обладает хорошей статистической мощностью.
Это хорошая практика для получения прогнозируемых меток классов путем передачи любой обученной модели классификации и новых данных предиктора в predict способ. Например, для получения информации о прогнозируемых метках из модели SVM см. predict.
Чувствительные к затратам тесты выполняют численную оптимизацию, что требует дополнительных вычислительных ресурсов. Тест отношения правдоподобия проводит численную оптимизацию косвенно путем нахождения корня множителя Лагранжа в интервале. Для некоторых наборов данных, если корень лежит близко к границам интервала, то метод может завершиться ошибкой. Поэтому, если у вас есть лицензия Optimization Toolbox, рассмотрите возможность проведения теста хи-квадрат с учетом затрат. Дополнительные сведения см. в разделе CostTest и тестирование с учетом затрат.
[1] Agresti, A. Категориальный анализ данных, 2-й ред. Джон Уайли и сыновья, Inc.: Хобокен, Нью-Джерси, 2002.
[2] Фагерлан, М.В., С. Лидерсен и П. Лааке. «Тест McNemar для двоичных согласованных пар данных: Mid-p и асимптотические лучше, чем точные условные». Методология медицинских исследований BMC. Том 13, 2013, стр. 1-8.
[3] Ланкастер, H.O. «Тесты значимости в дискретных распределениях». JASA, том 56, номер 294, 1961, стр. 223-234.
[4] McNemar, Q. «Примечание об ошибке выборки разницы между коррелированными пропорциями или процентами». Психометрика, т. 12, № 2, 1947, с. 153-157.
[5] Мостеллер, Ф. «Некоторые статистические проблемы в измерении субъективной реакции на наркотики». Биометрия, т. 8, № 3, 1952, с. 220-226.
