Декодер продукта кода (TPC)
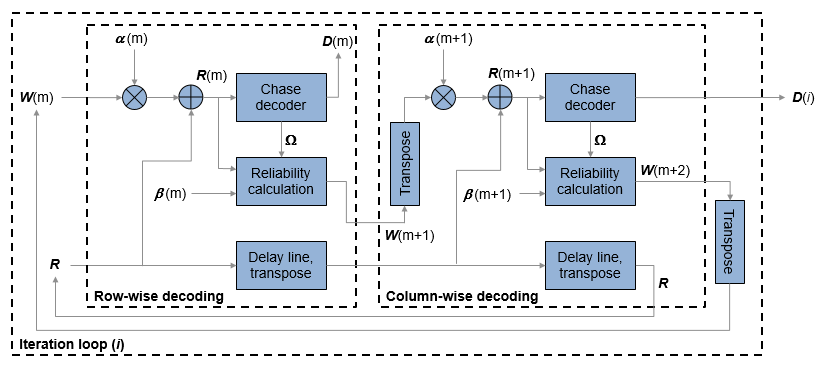
decoded = tpcdec(llr,N,K)llr, используя два линейных блочных кода, заданных длиной кодового слова N и длина сообщения K. Описание декодирования 2-D TPC смотрите в Turbo Product Code Decoding.
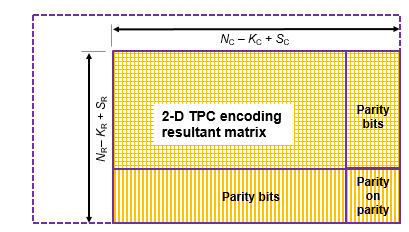
decoded = tpcdec(llr,N,K,S,maxnumiter,earlyterm)maxnumiter итерации декодирования. Как использовать maxnumiter и earlyterm с полнометражными сообщениями задайте S пустой, [].
[также возвращает фактическое количество итераций декодирования после выполнения декодирования 2-D TPC с использованием любого из предыдущих синтаксисов.decoded,actualnumiter] = tpcdec(___)
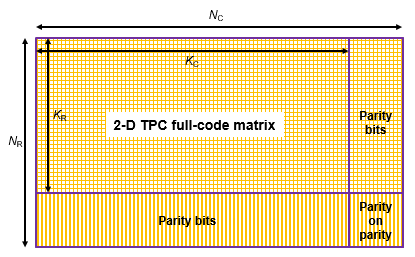
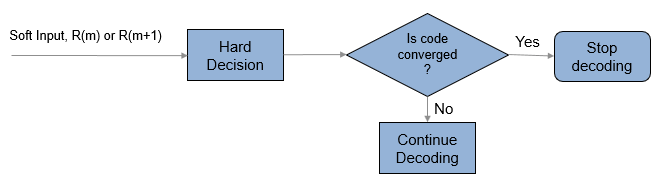
Турбокоды (TPC) продукта являются формой конкатенированных кодов, используемых в качестве кодов прямой коррекции ошибок (FEC). Два или более блочных кодов компонентов, таких как систематические линейные блочные коды, используются для создания TPC. Декодер TPC достигает почти оптимального декодирования продукта кодов, используя декодирование Chase и алгоритм Pyndiah, чтобы выполнить итерационный мягкий вход, мягкий выход декодирование. Подробное описание см. в разделах [1] и [2]. Этот декодер реализует итерационное мягкое входное, мягкое выходное 2-D кодовое декодирование продукта, как описано в [2], с использованием двух линейных блочных кодов. Декодер ожидает коэффициентов правдоподобия мягкого логарифмического журнала (LLR), полученных от цифровой демодуляции, в качестве входного сигнала.
Примечание
Декодер TPC ожидает положительный биполярный сопоставленный вход, в частности -1, сопоставленный с 0 и + 1, сопоставленный с 1. Выходы от демодуляторов в Communications Toolbox™ являются отрицательным биполярным отображением, в частности, + 1 сопоставлен с 0 и -1 сопоставлен с + 1. Поэтому выход LLR от демодуляторов должен быть отменен, чтобы обеспечить положительный биполярный отображенный вход, ожидаемый декодером TPC.
Декодер TPC декодирует либо полноразмерные, либо укороченные коды.
[1] Chase, D «. Класс алгоритмов для декодирования блочных кодов с информацией о измерениях в канале». Транзакции IEEE по теории информации, том 18, номер 1, январь 1972, стр. 170-182.
[2] Pyndiah, R. M. «Near-Optimum Decoding of Product Codes: Block Turbo Codes». Транзакции IEEE по коммуникациям. Том 46, № 8, август 1998, стр. 1003-1010.