Используйте эти наборы данных для начала работы с применениями глубокого обучения.
| Набор данных | Описание | Задача |
|---|---|---|
Цифры
| Набор данных цифр состоит из 10 000 синтетических полутоновых изображений рукописных цифр. Каждое изображение составляет 28 на 28 пикселей и имеет связанную метку, обозначающую, какую цифру представляет изображение (0-9). Каждое изображение повернуто на определенный угол. При загрузке изображений в виде массивов можно также загрузить угол поворота изображения. Загрузите данные цифр в виде числовых массивов в памяти с помощью [XTrain,YTrain,anglesTrain] = digitTrain4DArrayData; [XTest,YTest,anglesTest] = digitTest4DArrayData; Для примеров, показывающих, как обработать эти данные для глубокого обучения, смотрите Мониторинг процесса обучения и Обучите сверточную нейронную сеть для регрессии. | Классификация изображений и регрессия изображений |
Загрузите данные цифр в качестве datastore изображений с помощью dataFolder = fullfile(toolboxdir('nnet'),'nndemos','nndatasets','DigitDataset'); imds = imageDatastore(dataFolder, ... 'IncludeSubfolders',true, .... 'LabelSource','foldernames'); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Создать Простую Сеть Глубокого Обучения для Классификации. | Классификация изображений | |
MNIST
(Демонстрационный пример) | Набор данных MNIST состоит из 70 000 рукописных цифр, разделенных на обучающие и тестовые разделы, состоящие из 60 000 и 10 000 изображений, соответственно. Каждое изображение составляет 28 на 28 пикселей и имеет связанную метку, обозначающую, какую цифру представляет изображение (0-9). Загрузите файлы MNIST из http://yann.lecun.com/exdb/mnist/ и загрузите набор данных в рабочую область. Чтобы загрузить данные из файлов в виде массивов MATLAB, поместите файлы в рабочую директорию, а затем используйте вспомогательные функции oldpath = addpath(fullfile(matlabroot,'examples','nnet','main')); filenameImagesTrain = 'train-images-idx3-ubyte.gz'; filenameLabelsTrain = 'train-labels-idx1-ubyte.gz'; filenameImagesTest = 't10k-images-idx3-ubyte.gz'; filenameLabelsTest = 't10k-labels-idx1-ubyte.gz'; XTrain = processImagesMNIST(filenameImagesTrain); YTrain = processLabelsMNIST(filenameLabelsTrain); XTest = processImagesMNIST(filenameImagesTest); YTest = processLabelsMNIST(filenameLabelsTest); В качестве примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Train Variational Autoencoder (VAE), чтобы Сгенерировать изображения. Чтобы восстановить путь, используйте path(oldpath); | Классификация изображений |
Omniglot
| Набор данных Omniglot содержит наборы символов для 50 алфавитов, разделенных на 30 наборов для обучения и 20 наборов для проверки. Каждый алфавит содержит ряд символов, от 14 для Ojibwe (канадская слоговая система аборигенов) до 55 для Tifinagh. Наконец, каждый символ имеет 20 рукописных наблюдений. Загрузите и извлечите набор данных Omniglot [1] из https://github.com/brendenlake/omniglot. Задайте downloadFolder = tempdir; url = "https://github.com/brendenlake/omniglot/raw/master/python"; urlTrain = url + "/images_background.zip"; urlTest = url + "/images_evaluation.zip"; filenameTrain = fullfile(downloadFolder,"images_background.zip"); filenameTest = fullfile(downloadFolder,"images_evaluation.zip"); dataFolderTrain = fullfile(downloadFolder,"images_background"); dataFolderTest = fullfile(downloadFolder,"images_evaluation"); if ~exist(dataFolderTrain,"dir") fprintf("Downloading Omniglot training data set (4.5 MB)... ") websave(filenameTrain,urlTrain); unzip(filenameTrain,downloadFolder); fprintf("Done.\n") end if ~exist(dataFolderTest,"dir") fprintf("Downloading Omniglot test data (3.2 MB)... ") websave(filenameTest,urlTest); unzip(filenameTest,downloadFolder); fprintf("Done.\n") end Чтобы загрузить обучающие и тестовые данные как хранилища данных изображений, используйте imdsTrain = imageDatastore(dataFolderTrain, ... 'IncludeSubfolders',true, ... 'LabelSource','none'); files = imdsTrain.Files; parts = split(files,filesep); labels = join(parts(:,(end-2):(end-1)),'_'); imdsTrain.Labels = categorical(labels); imdsTest = imageDatastore(dataFolderTest, ... 'IncludeSubfolders',true, ... 'LabelSource','none'); files = imdsTest.Files; parts = split(files,filesep); labels = join(parts(:,(end-2):(end-1)),'_'); imdsTest.Labels = categorical(labels); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Обучите сиамскую сеть сравнению изображений. | Сходство изображений |
Цветы
| Набор данных Flowers содержит 3670 изображений цветов, относящихся к пяти классам (ромашка, одуванчик, розы, подсолнухи и тюльпаны). Загрузите и извлеките набор данных Flowers [2] из http://download.tensorflow.org/example_images/flower_photos.tgz. Набор данных составляет около 218 МБ. В зависимости от вашего подключения к Интернету процесс загрузки может занять некоторое время. Задайте url = 'http://download.tensorflow.org/example_images/flower_photos.tgz'; downloadFolder = tempdir; filename = fullfile(downloadFolder,'flower_dataset.tgz'); dataFolder = fullfile(downloadFolder,'flower_photos'); if ~exist(dataFolder,'dir') fprintf("Downloading Flowers data set (218 MB)... ") websave(filename,url); untar(filename,downloadFolder) fprintf("Done.\n") end Загрузите данные как datastore изображений, используя imds = imageDatastore(dataFolder, ... 'IncludeSubfolders',true, ... 'LabelSource','foldernames'); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Обучите Генеративную Состязательную Сеть (GAN). | Классификация изображений |
Пример Изображения еды
| Продовольственный набор данных Изображений Примера содержит 978 фотографий еды в девяти классах (caeser_salad, caprese_salad, french_fries, greek_salad, гамбургер, hot_dog, пицца, сашими и суши). Загрузите набор данных Example Food Image с помощью fprintf("Downloading Example Food Image data set (77 MB)... ") filename = matlab.internal.examples.downloadSupportFile('nnet', ... 'data/ExampleFoodImageDataset.zip'); fprintf("Done.\n") filepath = fileparts(filename); dataFolder = fullfile(filepath,'ExampleFoodImageDataset'); unzip(filename,dataFolder); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Просмотр поведения сети Используя tsne. | Классификация изображений |
CIFAR-10
(Демонстрационный пример) | Набор CIFAR-10 данных содержит 60 000 цветных изображений размером 32 на 32 пикселя, относящихся к 10 классам (самолет, автомобиль, птица, кошка, олень, собака, лягушка, лошадь, корабль и грузовик). На класс приходится 6000 изображений, и набор данных разделяется на набор обучающих данных с 50 000 изображений и тестовый набор с 10 000 изображений. Этот набор данных является одним из наиболее широко используемых наборов данных для проверки новых моделей классификации изображений. Загрузите и извлечите CIFAR-10 набор данных [7] из https://www.cs.toronto.edu/%7Ekriz/cifar-10-matlab.tar.gz. Набор данных составляет около 175 МБ. В зависимости от вашего подключения к Интернету процесс загрузки может занять некоторое время. Задайте url = 'https://www.cs.toronto.edu/~kriz/cifar-10-matlab.tar.gz'; downloadFolder = tempdir; filename = fullfile(downloadFolder,'cifar-10-matlab.tar.gz'); dataFolder = fullfile(downloadFolder,'cifar-10-batches-mat'); if ~exist(dataFolder,'dir') fprintf("Downloading CIFAR-10 dataset (175 MB)... "); websave(filename,url); untar(filename,downloadFolder); fprintf("Done.\n") end loadCIFARData, который используется в примере «Train остаточной сети для классификации изображений».oldpath = addpath(fullfile(matlabroot,'examples','nnet','main')); [XTrain,YTrain,XValidation,YValidation] = loadCIFARData(downloadFolder); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Обучите Остаточную Сеть для Классификации Изображений. Чтобы восстановить путь, используйте path(oldpath); | Классификация изображений |
MathWorks® Товар
| Это небольшой набор данных, содержащий 75 изображений товаров MathWorks, принадлежащих пяти различным классам (прописная буква, cube, игральные карты, отвертка и факел). Вы можете использовать этот набор данных, чтобы быстро опробовать передачу обучения и классификацию изображений. Изображения имеют размер 227 227 3. Извлеките набор данных MathWorks Merch. filename = 'MerchData.zip'; dataFolder = fullfile(tempdir,'MerchData'); if ~exist(dataFolder,'dir') unzip(filename,tempdir); end Загрузите данные как datastore изображений, используя imds = imageDatastore(dataFolder, ... 'IncludeSubfolders',true, .... 'LabelSource','foldernames'); Для примеров, показывающих, как обработать эти данные для глубокого обучения, смотрите Запуск с Передачей Обучения и Обучите Нейронную сеть для глубокого обучения для классификации Новых Изображений. | Классификация изображений |
CamVid
| Набор данных CamVid представляет собой набор изображений, содержащих виды уличного уровня, полученные от управляемых автомобилей. Набор данных полезен для обучения сетей, которые выполняют семантическую сегментацию изображений и обеспечивают метки пиксельного уровня для 32 семантических классов, включая автомобиль, пешеходов и дорогу. Изображения имеют размер 720 на 960 на 3. Загрузите и извлеките набор данных CamVid [8] из http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData. Набор данных составляет около 573 МБ. В зависимости от вашего подключения к Интернету процесс загрузки может занять некоторое время. Задайте downloadFolder = tempdir; url = "http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData" urlImages = url + "/files/701_StillsRaw_full.zip"; urlLabels = url + "/data/LabeledApproved_full.zip"; dataFolder = fullfile(downloadFolder,'CamVid'); dataFolderImages = fullfile(dataFolder,'images'); dataFolderLabels = fullfile(dataFolder,'labels'); filenameLabels = fullfile(dataFolder,'labels.zip'); filenameImages = fullfile(dataFolder,'images.zip'); if ~exist(filenameLabels, 'file') || ~exist(imagesZip,'file') mkdir(dataFolder) fprintf("Downloading CamVid data set images (557 MB)... "); websave(filenameImages, urlImages); unzip(filenameImages, dataFolderImages); fprintf("Done.\n") fprintf("Downloading CamVid data set labels (16 MB)... "); websave(filenameLabels, urlLabels); unzip(filenameLabels, dataFolderLabels); fprintf("Done.\n") end Загрузите данные как pixel label datastore, используя oldpath = addpath(fullfile(matlabroot,'examples','deeplearning_shared','main')); imds = imageDatastore(dataFolderImages,'IncludeSubfolders',true); classes = ["Sky" "Building" "Pole" "Road" "Pavement" "Tree" ... "SignSymbol" "Fence" "Car" "Pedestrian" "Bicyclist"]; labelIDs = camvidPixelLabelIDs; pxds = pixelLabelDatastore(dataFolderLabels,classes,labelIDs); Пример, показывающий, как обработать эти данные для глубокого обучения, см. в Семантическая Сегментация Using Deep Learning. Чтобы восстановить путь, используйте path(oldpath); | Семантическая сегментация |
Транспортное средство
| Набор данных транспортного средства состоит из 295 изображений, содержащих один или два маркированных образца транспортного средства. Этот небольшой набор данных полезен для исследования YOLO-v2 процедуры обучения, но на практике для обучения устойчивого детектора необходимо больше маркированных изображений. Изображения имеют размер 720 на 960 на 3. Извлечение набора данных Транспортного средства. Задайте filename = 'vehicleDatasetImages.zip'; dataFolder = fullfile(tempdir,'vehicleImages'); if ~exist(dataFolder,'dir') unzip(filename,tempdir); end Загрузите набор данных в виде таблицы имен файлов и ограничивающих рамок из извлеченного файла MAT и преобразуйте имена файлов в абсолютные пути к файлам. data = load('vehicleDatasetGroundTruth.mat');
vehicleDataset = data.vehicleDataset;
vehicleDataset.imageFilename = fullfile(tempdir,vehicleDataset.imageFilename);Создайте datastore, содержащее изображения, и datastore прямоугольных меток, содержащее ограничительные рамки, используя filenamesImages = vehicleDataset.imageFilename;
tblBoxes = vehicleDataset(:,'vehicle');
imds = imageDatastore(filenamesImages);
blds = boxLabelDatastore(tblBoxes);
cds = combine(imds,blds);Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Обнаружение объектов с использованием YOLO v2 Deep Learning. | Обнаружение объектов |
RIT-18
| Набор RIT-18 данных содержит данные об изображениях, полученные беспилотником над парком штата Хэмлин-Бич в состоянии Нью-Йорк. Данные содержат маркированные наборы обучения, валидации и тестирования с 18 метками класса объекта, включая разметку дороги, дерево и создание. Загрузите RIT-18 набор данных [9] из https://www.cis.rit.edu/%7Ermk6217/rit18_data.mat. Набор данных составляет около 3 ГБ. В зависимости от вашего подключения к Интернету процесс загрузки может занять некоторое время. Задайте downloadFolder = tempdir; url = 'http://www.cis.rit.edu/~rmk6217/rit18_data.mat'; filename = fullfile(downloadFolder,'rit18_data.mat'); if ~exist(filename,'file') fprintf("Downloading Hamlin Beach data set (3 GB)... "); websave(filename,url); fprintf("Done.\n") end Пример, показывающий, как обработать эти данные для глубокого обучения, см. в Семантической сегментации мультиспектральных изображений с использованием глубокого обучения. | Семантическая сегментация |
BraTS
| Набор данных BraTS содержит сканы МРТ опухолей головного мозга, а именно глиомы, которые являются наиболее распространенными первичными злокачественными новообразованиями головного мозга. Набор данных содержит 750 4-D томов, каждый из которых представляет собой стек 3-D изображений. Каждый 4-D объем имеет размер 240 на 240 на 155 на 4, где первые три измерения соответствуют высоте, ширине и глубине 3D объемного изображения. Четвертая размерность соответствует различным модальностям скана. Набор данных разделен на 484 обучающих тома с воксельными метками и 266 тестовых томов. Создайте директорию для хранения набора данных BraTS [10]. dataFolder = fullfile(tempdir,'BraTS'); if ~exist(dataFolder,'dir') mkdir(dataFolder); end Загрузите данные BraTS из Medical Segmentation Decathlon, нажав ссылку «Загрузить данные». Загрузите файл «Task01_BrainTumour.tar». Набор данных составляет около 7 ГБ. В зависимости от вашего подключения к Интернету процесс загрузки может занять некоторое время. Извлеките файл TAR в директорию, заданную Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите 3-D Сегментация Опухоли Мозга с Использованием Глубокого Обучения. | Семантическая сегментация |
Camelyon16
| Данные о Camelyon16 вызове содержат в общей сложности 400 WSI лимфатических узлов из двух независимых источников, разделенных на 270 обучающих изображений и 130 тестовых изображений. WSI хранятся как файлы TIF в обрезанном формате с 11-уровневой структурой пирамиды. Обучающие данные состоят из 159 WSI нормальных лимфатических узлов и 111 изображений (WSI) лимфатических узлов с опухолью и здоровой тканью. Обычно опухолевая ткань является небольшой частью здоровой ткани. Основные истины контуров поражения сопровождают изображения опухоли. Создайте директории для хранения Camelyon16 набора данных [11]. dataFolderTrain = fullfile(tempdir,'Camelyon16','training'); dataFolderNormalTrain = fullfile(dataFolderTrain,'normal'); dataFolderTumorTrain = fullfile(dataFolderTrain,'tumor'); dataFolderAnnotationsTrain = fullfile(dataFolderTrain,'lesion_annotations'); if ~exist(dataFolderTrain,'dir') mkdir(dataFolderTrain); mkdir(dataFolderNormalTrain); mkdir(dataFolderTumorTrain); mkdir(dataFolderAnnotationsTrain); end Загрузите Camelyon16 набор данных из Camelyon17, нажав на первую ссылку «CAMELYON16 data set». Откройте директорию «обучение», а затем выполните следующие действия:
Набор данных составляет около 2 ГБ. В зависимости от вашего подключения к Интернету процесс загрузки может занять некоторое время. Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Классификацию Больших Мультирезолюционных Изображений Используя blockedImage и Глубокое Обучение. | Классификация изображений (большие изображения) |
Общие объекты в контексте (COCO)
(Демонстрационный пример) | Набор данных обучающих изображений COCO 2014 состоит из 82 783 изображений. Данные аннотаций содержат по меньшей мере пять подписей, соответствующих каждому изображению. Создайте директории для хранения набора данных COCO. dataFolder = fullfile(tempdir,"coco"); if ~exist(dataFolder,'dir') mkdir(dataFolder); end Загрузите и извлеките учебные изображения и подписи COCO 2014 из https://cocodataset.org/#download, нажав на ссылки «2014 Train image» и «2014 Train/Val annotations» соответственно. Сохраните данные в папке, заданной как Извлеките подписи из файла filename = fullfile(dataFolder,"annotations_trainval2014","annotations", ... "captions_train2014.json"); str = fileread(filename); data = jsondecode(str); The Пример, показывающий, как обработать эти данные для глубокого обучения, см. в Изображение Captioning Using Attention. | Подписывание изображений |
IAPR- TC-12
(Демонстрационный пример) | IAPR TC-12 Benchmark [12] состоит из 20 000 все еще естественных изображений. Набор данных включает фотографии людей, животных, городов и многое другое. Размер файла данных составляет около 1,8 ГБ. Загрузите набор TC-12 данных IAPR. dataDir = fullfile(tempdir,'iaprtc12'); url = 'http://www-i6.informatik.rwth-aachen.de/imageclef/resources/iaprtc12.tgz'; if ~exist(dataDir,'dir') fprintf('Downloading IAPR TC-12 data set (1.8 GB)...\n'); try untar(url,dataDir); catch % On some Windows machines, the untar command errors for .tgz % files. Rename to .tg and try again. fileName = fullfile(tempdir,'iaprtc12.tg'); websave(fileName,url); untar(fileName,dataDir); end fprintf('Done.\n\n'); end Загрузите данные как datastore изображений, используя imageDir = fullfile(dataDir,'images') exts = {'.jpg','.bmp','.png'}; imds = imageDatastore(imageDir, ... 'IncludeSubfolders',true, ... 'FileExtensions',exts); Пример, показывающий, как обработать эти данные для глубокого обучения, смотрите в Single Image Super-Resolution Using Deep Learning. | Регрессия изображение-изображение |
Цюрихский RAW в RGB
| Набор данных [13] от Цюрихского RAW до RGB содержит 48 043 пространственно зарегистрированных пар закрашенных фигур RAW и RGB обучающих изображений размера 448 на 448. Набор данных содержит два отдельных тестовых набора. Один тестовый набор состоит из 1 204 пространственно зарегистрированных пар изображений RAW и RGB закрашенных фигур размера 448 на 448. Другой тестовый набор состоит из незарегистрированных изображений RAW и RGB с полным разрешением. Размер набора данных составляет 22 ГБ. Создайте директорию для хранения набора данных Zurich RAW to RGB. imageDir = fullfile(tempdir,'ZurichRAWToRGB'); if ~exist(imageDir,'dir') mkdir(imageDir); end imageDir переменная. При успешном извлечении imageDir содержит три директории с именем full_resolution, test, и train.Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Разработку Конвейера Обработки Необработанной Камеры Используя Глубокое Обучение. | Регрессия изображение-изображение |
LIVE In The Wild
| Набор данных LIVE In the Wild [14] состоит из 1162 фотографий, захваченных мобильными устройствами, с 7 дополнительными обучающими изображениями. Каждое изображение оценивается в среднем 175 индивидуумы по шкале [1, 100]. Набор данных обеспечивает среднее и стандартное отклонение субъективных счетов для каждого изображения. Создайте директорию для хранения набора данных LIVE In the Wild. imageDir = fullfile(tempdir,"LIVEInTheWild"); if ~exist(imageDir,'dir') mkdir(imageDir); end Загрузите набор данных, следуя инструкциям, описанным в LIVE In the Wild Image Quality Challenge Database. Извлеките данные в директорию, заданную Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Количественное определение качества изображения с помощью оценки нейронного изображения. | Классификация изображений |
| Данные | Описание | Задача |
|---|---|---|
Японские гласные
| Набор данных японских гласных [15] содержит предварительно обработанные [16]последовательности, представляющие высказывания японских гласных от разных носителей.
Загрузите набор данных японских гласных как массивы ячеек в памяти, содержащие числовые последовательности, используя [XTrain,YTrain] = japaneseVowelsTrainData; [XTest,YTest] = japaneseVowelsTestData; Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Классификацию последовательностей с использованием глубокого обучения. | Классификация от последовательности до метки |
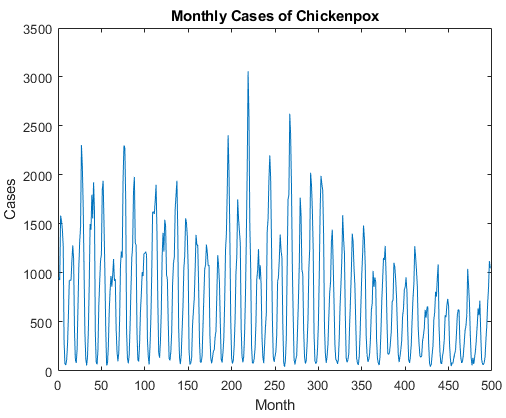
Ветрянка
| Набор данных ветряной оспы содержит один временные ряды с временными шагами, соответствующими месяцам и значениям, соответствующим количеству случаев. Выходы представляют собой массив ячеек, где каждый элемент является одним временным шагом. Загрузите данные ветряной оспы как одну числовую последовательность, используя data = chickenpox_dataset;
data = [data{:}];Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Прогнозирование временных рядов с использованием глубокого обучения. | Прогнозирование временных рядов |
Деятельность человека
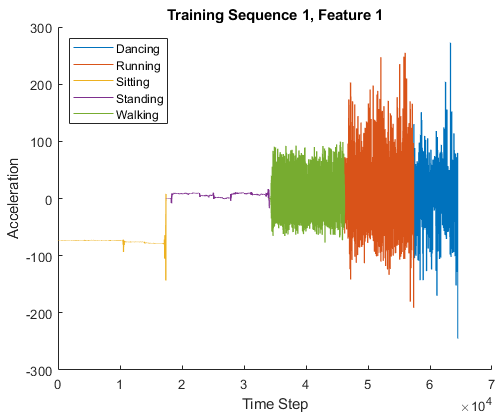
| Набор данных Human Activity содержит семь временных рядов данных о датчике, полученных с носимого на корпусе смартфона. Каждая последовательность имеет три функции и изменяется в длине. Три функции соответствуют показаниям акселерометра в трех разных направлениях. Загрузите набор данных Human Activity. dataTrain = load('HumanActivityTrain'); dataTest = load('HumanActivityTest'); XTrain = dataTrain.XTrain; YTrain = dataTrain.YTrain; XTest = dataTest.XTest; YTest = dataTest.YTest; Пример, показывающий, как обработать эти данные для глубокого обучения, см. в разделе Классификация последовательность-последовательность с использованием глубокого обучения. | Классификация последовательность-последовательность |
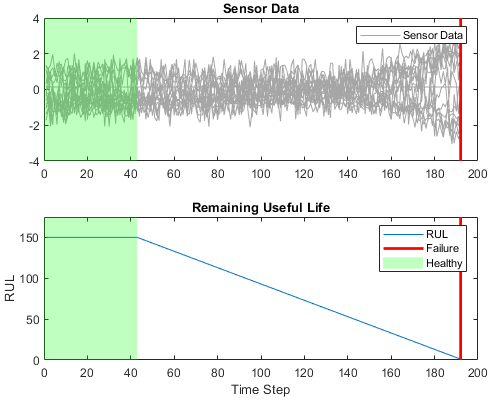
Моделирование деградации Engine турбины
| Каждые временные ряды набора данных Turbofan Engine Degradation Simulation [17] представляют другой механизм. Каждый двигатель запускается с неизвестных степеней начального износа и изменения в производстве. Двигатель работает нормально в начале каждых временных рядов и развивает отказ в какой-то момент во время серии. В наборе обучающих данных отказ растет в величине до отказа системы. Данные содержат сжатые ZIP текстовые файлы с 26 столбцами чисел, разделенными пространствами. Каждая строка является моментальным снимком данных, взятых в течение одного рабочего цикла, и каждый столбец является другой переменной. Столбцы соответствуют следующим:
Создайте директорию для хранения набора данных моделирования деградации Engine Turbofan. dataFolder = fullfile(tempdir,"turbofan"); if ~exist(dataFolder,'dir') mkdir(dataFolder); end Загрузите и извлечите набор данных моделирования деградации Engine Turbofan из https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/. Разархивируйте данные из файла filename = "CMAPSSData.zip";
unzip(filename,dataFolder)Загрузите обучающие и тестовые данные с помощью вспомогательных функций oldpath = addpath(fullfile(matlabroot,'examples','nnet','main')); filenamePredictors = fullfile(dataFolder,"train_FD001.txt"); [XTrain,YTrain] = processTurboFanDataTrain(filenamePredictors); filenamePredictors = fullfile(dataFolder,"test_FD001.txt"); filenameResponses = fullfile(dataFolder,"RUL_FD001.txt"); [XTest,YTest] = processTurboFanDataTest(filenamePredictors,filenameResponses); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Регрессию «Последовательность в последовательности» с использованием глубокого обучения. Чтобы восстановить путь, используйте path(oldpath); | Регрессия от последовательности к последовательности, прогнозирующее поддержание |
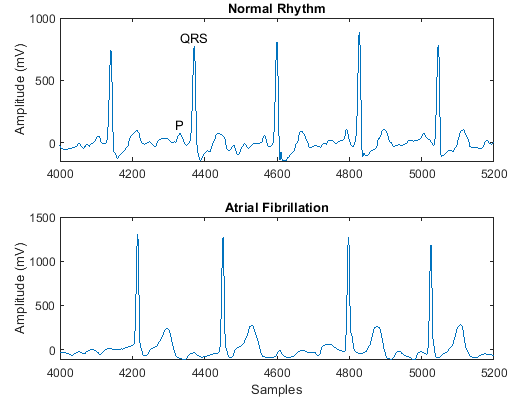
PhysioNet 2017 Challenge
| Набор данных PhysioNet 2017 Challenge [19] состоит из набора записей электрокардиограммы (ЭКГ), отобранных с частотой дискретизации 300 Гц и разделенных группой экспертов на различные классы. Загрузите и извлеките набор данных PhysioNet 2017 Challenge с помощью Набор данных составляет около 95 МБ. В зависимости от вашего подключения к Интернету процесс загрузки может занять некоторое время. oldpath = addpath(fullfile(matlabroot,'examples','deeplearning_shared','main')); ReadPhysionetData data = load('PhysionetData.mat') signals = data.Signals; labels = data.Labels; Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Классификацию сигналов ECG с использованием длинных краткосрочных сетей памяти. Чтобы восстановить путь, используйте path(oldpath); | Классификация от последовательности до метки |
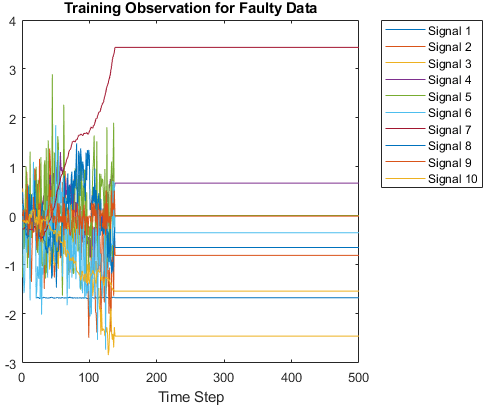
Симуляция процесса Теннесси Eastman (TEP)
| Этот набор данных состоит из файлов MAT, преобразованных из данных моделирования процесса Eastman (TEP) в Теннесси. Загрузите набор данных моделирования Tennessee Eastman Process (TEP) [18] с сайта файлов поддержки MathWorks (см. отказ от ответственности). Набор данных имеет четыре компонента: безаварийное обучение, безаварийная проверка, дефектное обучение и дефектная проверка. Загрузите каждый файл отдельно. Набор данных составляет около 1,7 ГБ. В зависимости от вашего подключения к Интернету процесс загрузки может занять некоторое время. fprintf("Downloading TEP faulty training data (613 MB)... ") filenameFaultyTrain = matlab.internal.examples.downloadSupportFile('predmaint', ... 'chemical-process-fault-detection-data/faultytraining.mat'); fprintf("Done.\n") fprintf("Downloading TEP faulty testing data (1 GB)... ") filenameFaultyTest = matlab.internal.examples.downloadSupportFile('predmaint', ... 'chemical-process-fault-detection-data/faultytesting.mat'); fprintf("Done.\n") fprintf("Downloading TEP fault-free training data (36 MB)... ") filenameFaultFreeTrain = matlab.internal.examples.downloadSupportFile('predmaint', ... 'chemical-process-fault-detection-data/faultfreetraining.mat'); fprintf("Done.\n") fprintf("Downloading TEP fault-free testing data (69 MB)... ") filenameFaultFreeTest = matlab.internal.examples.downloadSupportFile('predmaint', ... 'chemical-process-fault-detection-data/faultfreetesting.mat'); fprintf("Done.\n") Загрузите загруженные файлы в MATLAB® рабочей области. load(filenameFaultyTrain); load(filenameFaultyTest); load(filenameFaultFreeTrain); load(filenameFaultFreeTest); Пример, показывающий, как обработать эти данные для глубокого обучения, смотрите в Chemical Process Fault Detection Using Deep Learning. | Классификация от последовательности до метки |
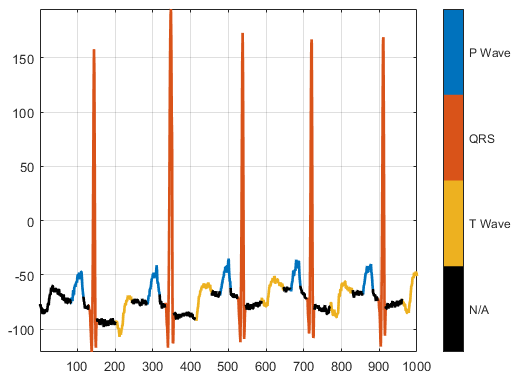
Сегментация ЭКГ ФизиоНет
| Набор данных PhysioNet ECG Segmentation [19] состоит примерно из 15 минут [20]записей ЭКГ от 105 пациентов. Чтобы получить каждую запись, экзаменаторы поместили два электрода в других местах на груди пациента, получая двухканальный сигнал. База данных обеспечивает метки областей сигнала, сгенерированные автоматизированной экспертной системой. Загрузите набор данных сегментации PhysioNet ECG с https://github.com/mathworks/physionet_ECG_segmentation путем загрузки ZIP- файла downloadFolder = tempdir; url = "https://github.com/mathworks/physionet_ECG_segmentation/raw/master/QT_Database-master.zip"; filename = fullfile(downloadFolder,"QT_Database-master.zip"); dataFolder = fullfile(downloadFolder,"QT_Database-master"); if ~exist(dataFolder,"dir") fprintf("Downloading Physionet ECG Segmentation data set (72 MB)... ") websave(filename,url); unzip(filename,downloadFolder); fprintf("Done.\n") end Unzipping создает папку
load(fullfile(dataFolder,'QTData.mat'))Пример, показывающий, как обработать эти данные для глубокого обучения, см. в разделе Сегментация формы волны с использованием глубокого обучения. | Классификация от последовательности до метки, сегментация формы волны |
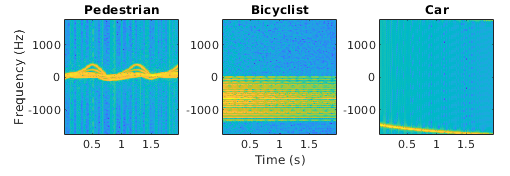
Синтетические пешеходы, автомобили и велосипедисты обратного рассеяния
| Сгенерируйте синтетический набор данных о пешеходе, автомобиле и велосипедисте с помощью вспомогательных функций Функция помощника Функция помощника
oldpath = addpath(fullfile(matlabroot,'examples','phased','main')); numPed = 1; % Number of pedestrian realizations numBic = 1; % Number of bicyclist realizations numCar = 1; % Number of car realizations [xPedRec,xBicRec,xCarRec,Tsamp] = helperBackScatterSignals(numPed,numBic,numCar); [SPed,T,F] = helperDopplerSignatures(xPedRec,Tsamp); [SBic,~,~] = helperDopplerSignatures(xBicRec,Tsamp); [SCar,~,~] = helperDopplerSignatures(xCarRec,Tsamp); Пример, показывающий, как обработать эти данные для глубокого обучения, см. в Классификации пешеходов и бициклистов с использованием глубокого обучения. Чтобы восстановить путь, используйте path(oldpath); | Классификация от последовательности до метки |
Сгенерированные формы волны
| Сгенерируйте прямоугольные, линейные FM и закодированные по фазе формы волны, используя функцию helper Функция помощника
oldpath = addpath(fullfile(matlabroot,'examples','phased','main')); [wav, modType] = helperGenerateRadarWaveforms; Пример, показывающий, как обработать эти данные для глубокого обучения, смотрите в Radar and Communications Waveform Classification Using Deep Learning. Чтобы восстановить путь, используйте path(oldpath); | Классификация «последовательность-метка» |
| Данные | Описание | Задача |
|---|---|---|
HMDB: большая база данных движения человека
(Демонстрационный пример) | Набор HMBD51 данных содержит около 2 ГБ видеоданных для 7000 клипов из 51 класса, таких как напиток, запуск и толчок. Загрузите и извлечите набор HMBD51 данных из HMDB: большой базы данных движения человека. Набор данных составляет около 2 ГБ. В зависимости от вашего подключения к Интернету процесс загрузки может занять некоторое время. После извлечения файлов RAR получите имена файлов и метки видео с помощью функции helper oldpath = addpath(fullfile(matlabroot,'examples','nnet','main')); dataFolder = fullfile(tempdir,"hmdb51_org"); [files,labels] = hmdb51Files(dataFolder); Пример, показывающий, как обработать эти данные для глубокого обучения, см. в разделе «Классификация видео с использованием глубокого обучения». Чтобы восстановить путь, используйте path(oldpath); | Классификация видео |
| Данные | Описание | Задача |
|---|---|---|
|
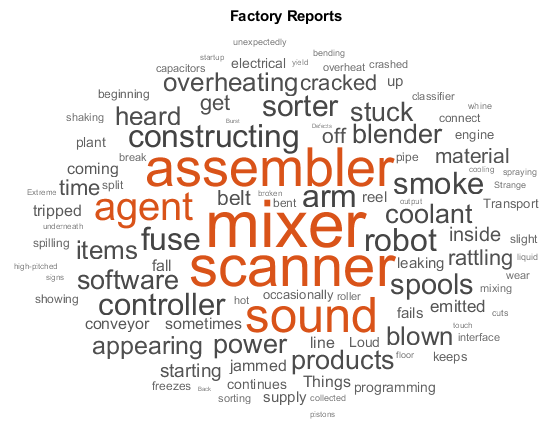
Заводские отчеты
| Набор данных Factory Reports представляет собой таблицу, содержащую приблизительно 500 отчетов с различными атрибутами, включая описание простого текста в переменной Считайте данные заводских отчетов из файла filename = "factoryReports.csv"; data = readtable(filename,'TextType','string'); textData = data.Description; labels = data.Category; Пример, показывающий, как обработать эти данные для глубокого обучения, см. в разделе «Классификация текстовых данных с использованием глубокого обучения». |
Классификация текста, моделирование темы |
|
Сонеты Шекспира
| Файл Считайте данные Sonnets Шекспира из файла filename = "sonnets.txt";
textData = fileread(filename);
Сонеты изрезаны двумя пробелами и разделены двумя символами новой строки. Удалите углубления с помощью textData = replace(textData," ",""); textData = split(textData,[newline newline]); textData = textData(5:2:end); Пример, показывающий, как обработать эти данные для глубокого обучения, см. в разделе «Генерация текста с помощью глубокого обучения». |
Моделирование тем, генерация текста |
|
Метаданные ArXiv
| API ArXiv позволяет вам получить доступ к метаданным научных электронных отпечатков, представленных в https://arxiv.org, включая абстрактные и предметные области. Для получения дополнительной информации смотрите https://arxiv.org/help/api. Импортируйте набор тезисов и меток категорий из математических документов с помощью arXiV API. url = "https://export.arxiv.org/oai2?verb=ListRecords" + ... "&set=math" + ... "&metadataPrefix=arXiv"; options = weboptions('Timeout',160); code = webread(url,options); Для примера, показывающего, как проанализировать возвращенные XML- код и импортировать больше записей, смотрите Мультиметку Классификация текста с использованием Глубокого обучения. |
Классификация текста, моделирование темы |
|
Книги из Project Gutenberg
| Вы можете скачать много книг из Project Gutenberg. Например, скачать текст из Alice's Adventures in Wonderland Льюиса Кэрролла из https://www.gutenberg.org/files/11/11-h/11-h.htm используя url = "https://www.gutenberg.org/files/11/11-h/11-h.htm";
code = webread(url);HTML кода содержит соответствующий текст внутри tree = htmlTree(code);
selector = "p";
subtrees = findElement(tree,selector);Извлеките текстовые данные из HTML с помощью textData = extractHTMLText(subtrees);
textData(textData == "") = [];Пример, показывающий, как обработать эти данные для глубокого обучения, см. в Word-By-Word Text Generation Using Deep Learning. |
Моделирование тем, генерация текста |
|
Обновления выходного дня
| Файл Извлеките текстовые данные из файла filename = "weekendUpdates.xlsx"; tbl = readtable(filename,'TextType','string'); textData = tbl.TextData; Пример обработки этих данных см. в разделе Анализ данных в тексте (Symbolic Math Toolbox). |
Анализ настроений |
|
Римские числа
| Файл CSV Загрузите десятичные-римские числовые пары из файла CSV filename = fullfile("romanNumerals.csv"); options = detectImportOptions(filename, ... 'TextType','string', ... 'ReadVariableNames',false); options.VariableNames = ["Source" "Target"]; options.VariableTypes = ["string" "string"]; data = readtable(filename,options); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Перевод последовательности в последовательность с использованием внимания. |
Перемещение последовательности в последовательность |
|
Финансовые отчеты
|
Комиссия по ценным бумагам и биржам (SEC) позволяет вам получить доступ к финансовым отчетам через электронный API сбора, анализа и извлечения данных (EDGAR). Для получения дополнительной информации смотрите https://www.sec.gov/edgar/searchedgar/accessing-edgar-data.htm. Чтобы загрузить эти данные, используйте функцию year = 2019; qtr = 4; maxLength = 2e6; textData = financeReports(year,qtr,maxLength); Для примера, показывающего, как обработать эти данные, смотрите Generate Domain Specific Sentiment Lexicon (Symbolic Math Toolbox). |
Анализ настроений |
| Данные | Описание | Задача |
|---|---|---|
Речевые команды
| Набор данных речевых команд [21] состоит приблизительно из 65 000 аудио файлов, помеченных 1 из 12 классов, включая да, нет, включено и отключено, а также классы, соответствующие неизвестным командам и фоновому шуму. Загрузите и извлечите набор данных речевых команд из https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz. Набор данных составляет около 1,4 ГБ. В зависимости от вашего подключения к Интернету процесс загрузки может занять некоторое время. Задайте dataFolder = tempdir; ads = audioDatastore(dataFolder, ... 'IncludeSubfolders',true, ... 'FileExtensions','.wav', ... 'LabelSource','foldernames'); Пример, показывающий, как обработать эти данные для глубокого обучения, см. в Распознание речевых команд с использованием глубокого обучения. | Классификация звука, распознавание речи |
Общий голос Mozilla
| Набор данных Mozilla Common Voice состоит из аудиозаписей речи и соответствующих текстовых файлов. Данные также включают демографические метаданные, такие как возраст, пол и акцент. Загрузите и извлечите набор данных набора данных Mozilla Common Voice из https://voice.mozilla.org/. Набор данных является открытым набором данных, что означает, что он может расти с течением времени. По состоянию на октябрь 2019 года набор данных составляет около 28 ГБ. В зависимости от вашего подключения к Интернету процесс загрузки может занять некоторое время. Задайте dataFolder = tempdir;
ads = audioDatastore(fullfile(dataFolder,"clips"));Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Классификацию полов с использованием сетей GRU. | Классификация звука, распознавание речи. |
Бесплатный набор данных цифр
| Free Spoken Digit Dataset, по состоянию на 29 января 2019 года, состоит из 2000 записей английских цифр от 0 до 9, полученных от четырёх дикторов. Два носителя в этой версии являются носителями американского английского языка, а два носителя являются носителями английского языка с бельгийским французским и немецким акцентом соответственно. Данные отбираются с частотой дискретизации 8000 Гц. Загрузите записи Free Spoken Digit Dataset (FSDD) из https://github.com/Jakobovski/free-spoken-digit-dataset. Задайте dataFolder = fullfile(tempdir,'free-spoken-digit-dataset','recordings'); ads = audioDatastore(dataFolder); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Распознавание Разговорных Цифр с Вейвлет и Глубокое Обучение. | Классификация звука, распознавание речи. |
Берлинская база данных эмоциональной речи
| Берлинская база данных эмоциональной речи [22] содержит 535 высказываний 10 актёров, призванных передать одну из следующих эмоций: гнев, скука, отвращение, беспокойство/страх, счастье, грусть или нейтраль. Эмоции являются независимыми от текста. Имена файлов являются кодами, указывающими на идентификатор динамика, устный текст, эмоции и версию. Веб-сайт содержит ключ для интерпретации кода и дополнительную информацию о докладчиках, таких как пол и возраст. Загрузите Берлинскую базу данных эмоциональной речи из http://emodb.bilderbar.info/index-1280.html. Набор данных составляет около 40 МБ. В зависимости от вашего подключения к Интернету процесс загрузки может занять некоторое время. Задайте dataFolder = tempdir;
ads = audioDatastore(fullfile(dataFolder,"wav"));
Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Распознавание Эмоций Речи. | Классификация звука, распознавание речи. |
TUT Акустические сцены 2017
| Загрузите и извлеките набор данных TUT Acoustic scenes 2017 [23] из набора данных TUT Acoustic scenes 2017, набора данных разработки и TUT Acoustic scenes 2017, набора данных оценки. Набор данных состоит из 10-секундных аудиосегментов из 15 акустических сцен, включая шину, автомобиль и библиотеку. Пример, показывающий, как обработать эти данные для глубокого обучения, см. в Acoustic Scene Recognition Using Late Fusion. | Классификация акустических сцен |
[1] Озеро, Бренден М., Руслан Салахутдинов, и Джошуа Б. Тененбаум. «Обучение концепции уровня человека через вероятностную индукцию программы». Наука 350, № 6266 (11 декабря 2015): 1332-38. https://doi.org/10.1126/science.aab3050.
[2] Команда TensorFlow. «Цветы» https://www.tensorflow.org/datasets/catalog/tf_flowers
[3] Кат, Тюльпаны, изображение, https://www.flickr.com/photos/swimparallel/3455026124. Creative Commons License (CC BY).
[4] Роб Бертольф, Подсолнухи, изображение, https://www.flickr.com/photos/robbertholf/20777358950. Типовая лицензия Creative Commons 2.0.
[5] Парвин, Розы, изображение, https ://www.flickr.com/photos/55948751 @ N00. Типовая лицензия Creative Commons 2.0.
[6] Джон Хаслам, одуванчики, изображение, https://www.flickr.com/photos/foxypar4/645330051. Типовая лицензия Creative Commons 2.0.
[7] Крижевский, Алекс. «Изучение нескольких слоев функций из крошечных изображений». Магистерская диссертация, Университет Торонто, 2009. https://www.cs.toronto.edu/%7Ekriz/learning-features-2009-TR.pdf.
[8] Brostow, Gabriel J., Julien Fauqueur, and Roberto Cipolla. Semantic Object Classes in Video: A High-Definition Ground Truth Database (неопр.) (недоступная ссылка). Pattern Recognition Letters 30, № 2 (январь 2009): 88-97. https://doi.org/10.1016/j.patrec.2008.04.005
[9] Кемкер, Рональд, Карл Сальваджо и Кристофер Канан. «Мультиспектральный набор данных высокого разрешения для семантической сегментации». ArXiv:1703.01918 [Cs], 6 марта 2017 года. https://arxiv.org/abs/1703.01918
[10] Isensee, Fabian, Philipp Kickingereder, Wolfgang Wick, Martin Bendszus, and Klaus H. Maier-Hein. «Сегментация опухоли мозга и предсказание выживания радиомики: вклад в вызов BRATS 2017». В Brainlesion: Глиома, рассеянный склероз, Штрих и травматические травмы головного мозга, под редакцией Алессандро Крими, Спиридона Бакаса, Уго Куйфа, Бьорна Менце и Маурисио Рейеса, 10670: 287-97. Cham, Швейцария: Springer International Publishing, 2018. https://doi.org/10.1007/978-3-319-75238-9_25
[11] Ehteshami Bejnordi, Бэбэк, Митко Вета, Пол Джоханнс ван Дист, Брэм ван Джиннекен, Нико Карссемейджер, Герт Литьенс, Йерун А. В. М. ван дер Лак, и др. «Диагностическая оценка алгоритмов глубокого обучения для обнаружения метастазов в лимфатических узлах у женщин с раком молочной железы». JAMA 318, № 22 (12 декабря 2017): 2199. https://doi.org/10.1001/jama.2017.14585
[12] Грубингер, М., П. Клаф, Х. Мюллер и Т. Дезелаерс. «IAPR TC-12 Benchmark: A New Evaluation Resource for Visual Information Systems». Сведения о языковых ресурсах OntoImage 2006 для поиска изображений на основе содержимого. Генуя, Италия. Том 5, май 2006, стр. 10.
[13] Игнатов, Андрей, Люк Ван Голь и Раду Тимофте. «Замена Mobile Camera ISP на одну модель глубокого обучения». ArXiv:2002.05509 [Cs, Eess], 13 февраля 2020 года. http://arxiv.org/abs/2002.05509. Веб-сайт проекта.
[14] LIVE: Лаборатория инженерии изображений и видео. https://live.ece.utexas.edu/research/ChallengeDB/index.html.
[15] Кудо, Минейчи, Цзюнь Тояма и Масару Симбо. «Многомерная классификация кривых с использованием областей». Pattern Recognition Letters 20, No. 11-13 (November 1999): 1103-11. https://doi.org/10.1016/S0167-8655 (99) 00077-X
[16] Кудо, Минейчи, Цзюнь Тояма и Масару Симбо. Японский набор данных гласных. Распространяется UCI Machine Learning Repository. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
[17] Саксена, Абхинав, Кай Гебель. «Набор данных моделирования деградации Engine». NASA Ames Prognostics Data Repository https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/, Исследовательский центр НАСА им. Эймса, Моффетт-Филд, Калифорния
[18] Рит, Кори А., Бен Д. Амсель, Рэнди Тран и Майя Б. Кук. Дополнительные данные моделирования процесса Eastman в Теннесси для оценки обнаружения аномалий. Гарвардская Dataverse, версия 1, 2017. https://doi.org/10.7910/DVN/6C3JR1.
[19] Голдбергер, Ари Л., Луис А. Н. Амарал, Леон Гласс, Джеффри М. Хаусдорф, Пламен Ч. Иванов, Роджер Г. Марк, Джозеф Е. Миетус, Джордж Б. Муди, Чунг-Канг Пенг PhysioBank, PhysioToolkit и PhysioNet: компоненты нового исследовательского ресурса комплексных физиологических сигналов. Тираж 101, № 23, 2000, п. e215-e220. https://circ.ahajournals.org/content/101/23/e215.full
[20] Лагуна, Пабло, Роджер Г. Марк, Ари Л. Голдбергер и Джордж Б. Муди. «База данных для оценки алгоритмов измерения интервалов QT и других сигналов в ЭКГ». Компьютеры в кардиологии 24, 1997, с. 673-676.
[21] Warden P. «Speech Commands: A public dataset for single-word speech recognition», 2017. Доступно из http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz. Копирайт Google 2017. Набор данных Speech Commands лицензирован по лицензии Creative Commons Attribution 4.0, доступной здесь: https://creativecommons.org/licenses/by/4.0/legalcode.
[22] Буркхардт, Феликс, Астрид Пэшке, Мелисса А. Рольфес, Вальтер Ф. Зендльмайер и Бенджамин Вайсс. «База данных немецкой эмоциональной речи». Труды Interspeech 2005. Лиссабон, Португалия: Международная ассоциация речевых коммуникаций, 2005 год.
[23] Месарос, Аннамария, Тони Хейттола и Туомас Виртанен. «Классификация акустических сцен: обзор задач DCASE 2017». В 2018 году 16-й Международный семинар по усилению акустических сигналов (IWAENC), стр. 411-415. IEEE, 2018.
trainingOptions | trainNetwork