Совет
Чтобы обучить нейронную сеть для глубокого обучения, используйте trainNetwork.
В этом разделе представлена часть типового многослойного рабочего процесса мелкослойной сети. Для получения дополнительной информации и других шагов см. Multilayer Shallow Neural Networks and Backpropagation Training.
Когда веса и смещения сети инициализируются, сеть готова к обучению. Многослойные сети прямого распространения могут быть обучены для приближения функций (нелинейная регрессия) или распознавания шаблона. Процесс обучения требует набора примеров правильного поведения сети - входов сети p и целевые выходы t.
Процесс обучения нейронной сети включает настройку значений весов и смещений сети для оптимизации эффективности сети, как определено функцией эффективности сети net.performFcn. Функцией эффективности по умолчанию для сетей прямого распространения является средняя квадратная ошибка mse- средняя квадратичная невязка между выходами сети a и целевые выходы t. Определяется следующим образом:
(Отдельные квадратичные невязки также могут быть взвешены. Смотрите Обучите Нейронные Сети с Весами Ошибок.) Существует два различных способа реализации обучения: инкрементный режим и пакетный режим. В инкрементном режиме градиент вычисляется, и веса обновляются после применения каждого входа к сети. В пакетном режиме все входы в набор обучающих данных применяются к сети перед обновлением весов. В этом разделе описывается обучение пакетному режиму с train команда. Инкрементальное обучение с adapt команда обсуждается в инкрементальном обучении с адаптацией. Для большинства задач при использовании программного обеспечения Deep Learning Toolbox™ пакетное обучение происходит значительно быстрее и приводит к меньшим ошибкам, чем инкрементальное обучение.
Для обучения многослойных сетей прямого распространения может использоваться любой стандартный алгоритм численной оптимизации для оптимизации функции эффективности, но есть несколько ключевых таковые, которые показали отличную эффективность для обучения нейронной сети. Эти методы оптимизации используют либо градиент эффективности сети относительно весов сети, либо якобиан сетевых ошибок относительно весов.
Градиент и якобиан вычисляются с помощью метода, называемого алгоритмом обратного распространения, который включает в себя выполнение расчетов назад через сеть. Расчет обратного распространения получен с помощью правила цепи исчисления и описано в главах 11 (для градиента) и 12 (для якобиана) [HDB96].
Как рисунок того, как работает обучение, рассмотрим самый простой алгоритм оптимизации - градиентный спуск. Он обновляет веса сети и смещения в направлении, в котором функция эффективности уменьшается наиболее быстро, отрицательное значение градиента. Одна итерация этого алгоритма может быть записана как
где x k является вектором токовых весов и смещений, g k является градиентом тока, а α k является скорость обучения. Это уравнение итерации пока сеть не сходится.
Список алгоритмов настройки, доступных в программном обеспечении Deep Learning Toolbox и использующих основанные на градиенте или якобиане методы, показан в следующей таблице.
Подробное описание некоторых из этих методов см. также в Hagan, M.T., H.B. Demuth и M.H. Beale, Neural Network Design, Boston, MA: PWS Publishing, 1996, Chapters 11 и 12.
Функция | Алгоритм |
|---|---|
Левенберг-Марквардт | |
Байесовская регуляризация | |
BFGS Квази-Ньютон | |
Упругое обратное распространение | |
Масштабированный сопряженный градиент | |
Сопряженный градиент с перезапусками Powell/Beale | |
Сопряженный градиент Флетчера-Пауэлла | |
Сопряженный градиент Полак-Рибьер | |
Одношаговый секант | |
Градиентный спуск переменной скорости обучения | |
Градиентный спуск с моментом | |
Градиентный спуск |
Самая быстрая функция обучения, как правило, trainlm, и это функция обучения по умолчанию для feedforwardnet. Метод квази-Ньютона, trainbfg, также довольно быстро. Оба этих метода, как правило, менее эффективны для больших сетей (с тысячами весов), поскольку они требуют больше памяти и больше времени расчетов для этих случаев. Также, trainlm выполняет лучше задачи подбора кривой функций (нелинейная регрессия), чем задачи распознавания шаблонов.
При обучении больших сетей, и при обучении сетей распознавания шаблонов, trainscg и trainrp это хороший выбор. Их требования к памяти относительно малы, и тем не менее они намного быстрее, чем стандартные алгоритмы градиентного спуска.
Смотрите Choose a Multilayer Neural Network Training Function для полного сравнения характеристик алгоритмов настройки, показанных в таблице выше.
Как примечание к терминологии, термин «обратное распространение» иногда используется для обозначения конкретно алгоритма градиентного спуска, когда он применяется к обучению нейронной сети. Эта терминология здесь не используется, поскольку процесс вычисления градиента и якобиана путем выполнения вычислений назад через сеть применяется во всех перечисленных выше функциях обучения. Понятнее использовать имя конкретного алгоритма оптимизации, который используется, а не использовать только термин backpropagation.
Кроме того, многослойная сеть иногда упоминается как сеть обратного распространения. Однако метод обратного распространения, который используется для вычисления градиентов и якобийцев в многослойной сети, может также применяться ко многим различным сетевым архитектурам. Фактически, градиенты и якобианы для любой сети, которая имеет дифференцируемые передаточные функции, весовые функции и чистые входные функции, могут быть вычислены с помощью программного обеспечения Deep Learning Toolbox посредством процесса обратного распространения. Можно даже создать свои собственные пользовательские сети и затем обучить их с помощью любой из функций обучения в таблице выше. Градиенты и якобианцы будут автоматически вычислены для вас.
Чтобы проиллюстрировать процесс обучения, выполните следующие команды:
load bodyfat_dataset
net = feedforwardnet(20);
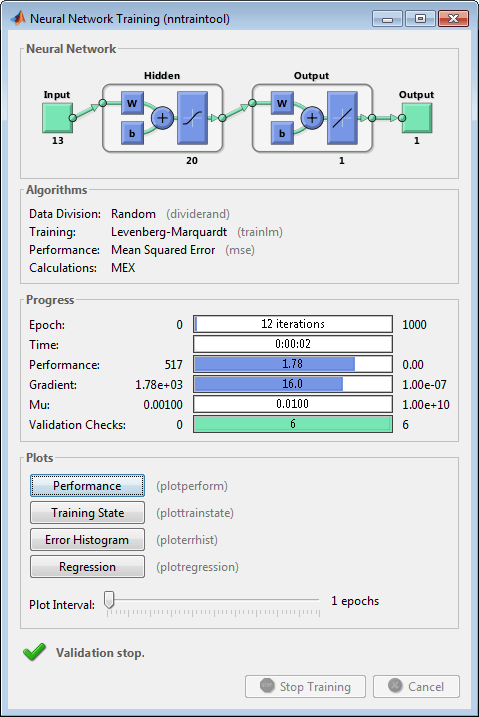
[net,tr] = train(net,bodyfatInputs,bodyfatTargets);Заметьте, что вам не нужно было выдавать configure команда, поскольку строение выполняется автоматически train функция. Окно обучения появится во время обучения, как показано на следующем рисунке. (Если вы не хотите, чтобы это окно отображалось во время обучения, можно задать параметр net.trainParam.showWindow на false. Если необходимо отобразить обучающую информацию в командной строке, можно задать параметр net.trainParam.showCommandLine на true.)
В этом окне показано, что данные были разделены с помощью dividerand function, и Levenberg-Marquardt (trainlm) метод обучения использовался со средним квадратичным значением ошибки эффективность. Напомним, что это настройки по умолчанию для feedforwardnet.
Во время обучения прогресс постоянно обновляется в окне обучения. Наибольший интерес представляют эффективность, величина градиента эффективности и количество проверок валидации. Величина градиента и количество проверок на валидацию используются для завершения обучения. Градиент станет очень маленьким, когда обучение достигает минимума эффективности. Если величина градиента меньше 1e-5, обучение остановится. Этот предел может быть скорректирован путем установки параметра net.trainParam.min_grad. Количество проверок валидации представляет количество последовательных итераций, при которых эффективность валидации не уменьшается. Если это число достигает 6 (значение по умолчанию), обучение остановится. В этом запуске можно увидеть, что обучение остановилось из-за количества проверок валидации. Можно изменить этот критерий, установив параметр net.trainParam.max_fail. (Обратите внимание, что ваши результаты могут отличаться от результатов, показанных на следующем рисунке, из-за случайной настройки начальных весов и смещений.)
Существуют другие критерии, которые могут использоваться, чтобы остановить сетевое обучение. Они перечислены в следующей таблице.
Параметр | Критерий остановки |
|---|---|
min_grad | Минимальная величина градиента |
max_fail | Максимальное количество увеличений валидации |
time | Максимальное время обучения |
goal | Минимальное значение эффективности |
epochs | Максимальное Количество циклов обучения (итерации) |
Обучение также остановится, если вы нажмете кнопку Stop Training в окне обучения. Это может потребоваться, если функция эффективности не может значительно уменьшиться в течение многих итераций. Всегда можно продолжить обучение, переоформив train команда, показанная выше. Он продолжит обучение сети с момента завершения предыдущего запуска.
Из окна обучения можно получить доступ к четырем графикам: эффективность, состоянию обучения, гистограмме ошибок и регрессии. График эффективности показывает значение функции эффективности от числа итерации. Он строит графики обучения, валидации и тестовых выступлений. График состояния обучения показывает прогресс других переменных обучения, таких как величина градиента, количество проверок валидации и т.д. График гистограммы ошибок показывает распределение сетевых ошибок. График регрессии показывает регрессию между выходами сети и сетевыми целями. Можно использовать гистограммы и регрессионные графики для проверки эффективности сети, как обсуждается в Analyze Shallow Neural Network Performance After Training.
После обучения и проверки сети сетевой объект может использоваться, чтобы вычислить сетевой ответ на любой вход. Например, если вы хотите найти сетевой ответ на пятый входной вектор в создании, можно использовать следующее
a = net(bodyfatInputs(:,5))
a = 27.3740
Если вы попробуете эту команду, ваш выход может быть другим, в зависимости от состояния вашего генератора случайных чисел, когда сеть была инициализирована. Ниже вызывается объект сети, чтобы вычислить выходы для параллельного набора всех входных векторов в наборе данных о жировом теле. Это форма симуляции пакетного режима, в которой все входные векторы помещены в одну матрицу. Это намного эффективнее, чем представление векторов по одному.
a = net(bodyfatInputs);
Каждый раз, когда нейронная сеть обучается, может привести к другому решению из-за различных начальных значений веса и смещения и различных делений данных в наборы для обучения, валидации и тестирования. В результате различные нейронные сети, обученные одной и той же задаче, могут выдавать различные выходы для одного и того же входа. Чтобы убедиться, что нейронная сеть с хорошей точностью была найдена, переобучите несколько раз.
Существует несколько других методов улучшения начальных решений, если желательна более высокая точность. Для получения дополнительной информации см. «Улучшение обобщения неглубокой нейронной сети» и «Избегайте избыточного оснащения».
