Распределенная арифметика (DA) является широко используемым методом для реализации расчетов суммы произведения без использования умножителей. Дизайнеры часто используют DA, чтобы создать эффективную Multiply-Accumulate Circuitry (MAC) для фильтров и других приложений DSP.
Основным преимуществом DA является его высокая вычислительная эффективность. DA распределяет операции умножения и накопления между сдвигателями, интерполяционными таблицами (LUT) и сумматорами таким образом, что обычные умножители не требуются.
Кодер поддерживает DA в HDL-кодах, сгенерированных для нескольких структур фильтра с одной и несколькими конечных импульсных характеристик для созданий фильтра с фиксированной точкой. (См. Требования и факторы для генерации распределенного арифметического кода.)
В этом разделе кратко описывается операция DA. Подробные обсуждения теоретических основ ДА появляются в следующих публикациях:
Meyer-Baese, U., Digital Signal Processing with Field Programmable Gate Arrays, Second Edition, Springer, pp 88-94, 128-143.
White, S.A., Applications of Distributed Arithmetics to Digital Signal Processing: A Tutorial Review. Журнал IEEE ASSP Magazine, том 6, № 3.
В реализации DA структуры конечной импульсной характеристики фильтра последовательность слов входных данных ширины W подается через параллельный регистр последовательного сдвига. Этот канал производит сериализованный поток бит. Сериализованные данные затем подаются в битовый регистр сдвига. Этот регистр сдвига служит линией задержки, сохраняя бит выборок последовательных данных.
Задержка линии достигнута (на основе входа размера слова W), для формирования W- битовый адрес, который индексируется в интерполяционную таблицу (LUT). LUT хранит возможные суммы частичных продуктов в пространстве коэффициентов фильтра. Сдвиг и сумматор (масштабирующий аккумулятор) следуют за LUT. Эта логика последовательно добавляет значения, полученные из LUT.
Поиск таблицы выполняется последовательно для каждого бита (в порядке значимости, начиная с LSB). На каждом тактовом цикле результат LUT добавляется к накопленному и сдвинутому результату от предыдущего цикла. Для последнего бита (MSB) вычитается результат поиска таблицы с учетом знака операнда.
Эта базовая форма DA полностью последовательная, работающая на одном бите за раз. Если последовательность входных данных W bits wide, тогда структура конечной импульсной характеристики принимает W синхроимпульсы для вычисления выходов. Симметричные и асимметричные структуры конечной импульсной характеристики являются исключением, требующим W+1 циклы, потому что для обработки бита переноса предварительных сумматоров требуется один дополнительный тактовый цикл.
Последовательная природа бита DA может ограничивать пропускную способность. Чтобы улучшить пропускную способность, основной алгоритм DA может быть изменен, чтобы вычислить более одной битовой суммы за раз. Количество одновременно вычисленных битовых сумм выражается как степень двойки названных DA radix. Для примера DA-радикал 2 (2^1) указывает, что вычисляется одна битовая сумма за раз. A DA radix of 4 (2^2) указывает, что одновременно вычисляются две битовые суммы и так далее.
Чтобы вычислить более одной битовой суммы за раз, кодер наследует LUT. Для примера для выполнения DA на двух битах за раз (радис 4) нечетные биты подаются на одну LUT, и четные биты одновременно подаются на идентичную LUT. Результаты LUT, соответствующие нечетным битам, сдвигаются влево, прежде чем они добавляются к результатам LUT, соответствующим четным битам. Этот результат затем подается в масштабирующий аккумулятор, который смещает свое значение обратной связи на два места.
Обработка более одного бита за раз вносит в операцию степень параллелизма, которая может улучшить эффективность за счет площади. The DARadix Свойство позволяет вам задать количество бит, обрабатываемых одновременно в DA.
Размер LUT растет экспоненциально с порядком фильтра. Для фильтра с N коэффициенты, LUT должны иметь 2^N значения. Для фильтров более высокого порядка размер LUT должен быть уменьшен до разумных уровней. Чтобы уменьшить размер, можно подразделить LUT на несколько LUT, называемых LUT partitions. Каждый раздел LUT работает с различным набором ответвлений. Результаты, полученные из разбиений, суммируют.
Для примера для 160-контактного фильтра размер LUT (2^160)*W биты, где W - размер слова данных LUT. Вы можете добиться значительного сокращения размера LUT, разделив LUT на 16 разделов LUT, каждый из которых принимает 10 входов (отводов). Это деление уменьшает общий размер LUT до 16*(2^10)*W биты.
Несмотря на то, что разбиение LUT уменьшает размер LUT, архитектура использует больше сумматоров для суммирования данных LUT.
The DALUTPartition Свойство позволяет указать, как LUT разделяется в DA.
Кодер позволяет вам контролировать, как код DA генерируется с помощью DALUTPartition и DARadix свойства (или эквивалентные опции диалогового окна Генерация HDL). Прежде чем использовать эти свойства, проверьте следующие общие требования, ограничения и другие факторы для генерации кода DA.
Кодер поддерживает DA в HDL-кодах, сгенерированных для следующих структур фильтра с одной и несколькими конечных импульсных характеристик:
прямая форма (dfilt.dffir или dsp.FIRFilter)
прямая форма симметричная (dfilt.dfsymfir или dsp.FIRFilter)
прямая асимметричная форма (dfilt.dfasymfir или dsp.FIRFilter)
dsp.FIRDecimator
dsp.FIRInterpolator
Генерация кода DA поддерживается только для созданий фильтра с фиксированной точкой.
Путь к данным в HDL-коде, сгенерированный для архитектуры DA, оптимизирован для полной точности расчетов. Фильтр приводит результат к размеру выходных данных на заключительном этапе. Если для вашего объекта фильтра задано использование полных типов данных точности, числовые результаты симуляции сгенерированного HDL-кода имеют битовое значение true к выходу исходного объекта фильтра.
Если ваш объект фильтра имеет настраиваемое слово или длины дроби, сгенерированный код DA может привести к числовым результатам, которые отличаются от выходов исходного объекта фильтра.
DA игнорирует отводы, которые имеют нулевые коэффициенты, и уменьшает размер DA LUT соответственно.
Для симметричных и асимметричных конечная импульсная характеристика:
Предварительный сумматор битового уровня или пресубтрактор требуется для добавления значений данных касания, которые имеют коэффициенты равного значения и/или противоположного знака. Для вычисления результата требуется один дополнительный тактовый цикл из-за дополнительного бита переноса.
Кодер использует симметрию фильтра. Эта симметрия существенно уменьшает размер DA LUT, поскольку эффективная длина фильтра для этих типов фильтров уменьшается вдвое.
Секционированные распределенные арифметические архитектуры реализуют внутреннюю тактовую частоту, превышающую скорость входа. В таких реализациях фильтра существуют N циклы (N >= 2) базового синхроимпульса для каждой входной выборки. Можно задать, сколько тактовых циклов испытательный стенд содержит значения входных данных в допустимом состоянии.
При выборе Hold input data between samples (по умолчанию) испытательный стенд содержит значения входных данных в допустимом состоянии для N тактовые импульсы.
Когда вы снимаете Hold input data between samples, испытательный стенд содержит значения в допустимом состоянии только для одного такта. Для следующего N-1 циклы, испытательный стенд приводит данные в неизвестное состояние (выраженное как 'X') пока следующая входная выборка не будет синхронизирована. Принудительное преобразование входных данных в неизвестное состояние проверяет, что сгенерированный код фильтра регистрирует входные данные только в первом цикле.
generatehdl СвойстваДва свойства задают распределенные арифметические опции для generatehdl функция:
DALUTPartition - Количество и размер разделов интерполяционной таблицы (LUT).
DARadix - Количество битов, обработанных параллельно.
Вы можете использовать функцию helper hdlfilterdainfo чтобы исследовать возможные разделы и настройки радиуса для вашего фильтра.
Для примеров см.
Диалоговое окно Генерация HDL предоставляет несколько опций, связанных с генерацией кода DA.
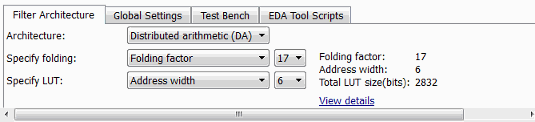
Всплывающее меню Architecture, которое позволяет включать генерацию кода DA и отображать соответствующие опции.
Раскрывающееся меню Specify folding, которое позволяет непосредственно задать коэффициент складывания или задать значение для DARadix свойство.
Раскрывающееся меню Specify LUT, которое позволяет непосредственно задать значение для DALUTPartition свойство. Можно также выбрать ширину адреса для LUT. Если вы задаете ширину адреса, кодер использует входные LUT при необходимости.
В диалоговом окне Генерация HDL (Generate HDL) первоначально отображаются значения опций, относящихся к DA по умолчанию, которые соответствуют текущему созданию фильтра. Требования к установке этих опций см. в разделе DALUTPartition и DARadix.
Чтобы задать генерацию кода DA с помощью диалогового окна Generate HDL, выполните следующие шаги:
Создайте конечная импульсная характеристика (с помощью Filter Designer, Filter Builder или MATLAB® команды), который удовлетворяет требованиям, описанным в «Требованиях и факторах для генерации распределенного арифметического кода».
Откройте диалоговое окно Генерация HDL.
Выберите Distributed Arithmetic (DA) из Architecture всплывающего меню.
При выборе этой опции под меню Architecture отображаются соответствующие Specify folding и Specify LUT опции. Следующий рисунок показывает опции DA по умолчанию для фильтра конечной импульсной характеристики прямой формы.
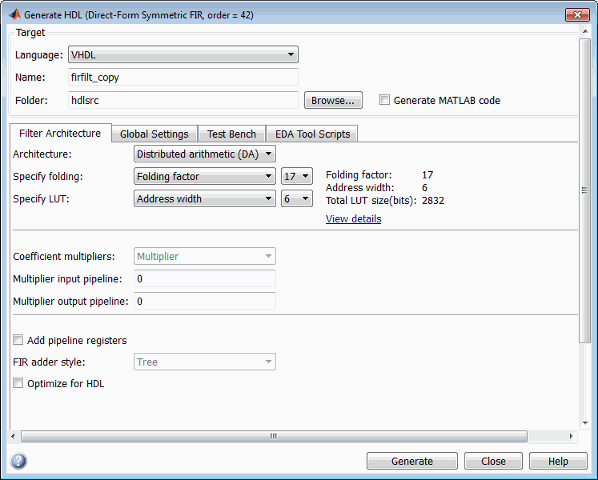
Выберите одну из следующих опций в раскрывающемся меню Specify folding:
Folding factor (по умолчанию): Выберите коэффициент складывания из раскрывающегося меню справа от Specify folding. Меню содержит исчерпывающий список опций коэффициента складывания для фильтра.
DA radix: Выберите количество бит, обработанных одновременно, выраженное в степени 2. Значение по умолчанию DA radix значение 2, задающая обработку одного бита за раз или полностью последовательного DA. При желании установите DA radix поле для значения, отличного от значения по умолчанию.
Выберите одну из следующих опций в раскрывающемся меню Specify LUT:
Address width (по умолчанию): Выберите из раскрывающегося меню справа от Specify LUT. Меню содержит исчерпывающий список ширин адресов LUT для фильтра.
Partition: Выберите или введите вектор, указывающий количество и размер разделов LUT.
Установите другие опции HDL по мере необходимости и сгенерируйте код. Недопустимые или недопустимые значения для LUT Partition или DA Radix сообщаются во время генерации кода.
Когда вы взаимодействуете с Specify folding и Specify LUT опциями, вы можете увидеть результаты по своему выбору в трех полях только для отображения: Folding factor, Address width, и Total LUT size (bits).
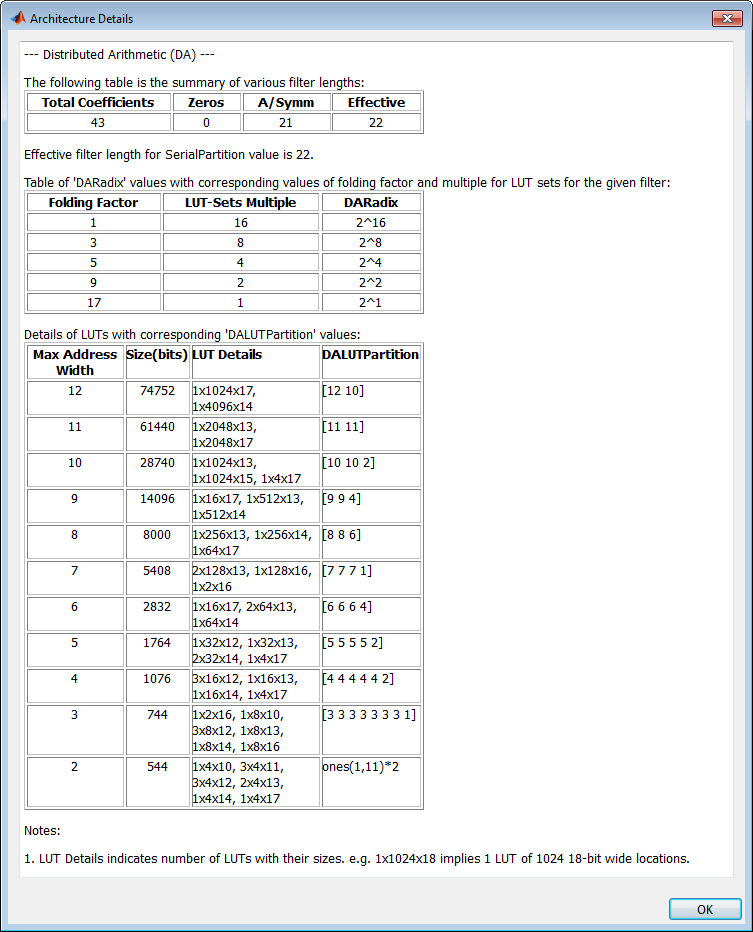
В сложение, при нажатии гиперссылки View details, кодер отображает отчет, показывающий полные архитектурные детали DA для текущего фильтра, включая:
Длины фильтров
Полный список применимых факторов складывания и их применение к наборам LUT
Табуляция строений LUT с общими данными о размере LUT и LUT
Следующий рисунок показывает типовой отчет.
Когда Distributed Arithmetic (DA) выбран в Architecture меню, некоторые другие опции HDL автоматически изменяются на настройки, соответствующие генерации кода DA:
Coefficient multipliers установлено на Multiplier и отключен.
FIR adder style установлено на Tree и отключен.
Add input register (на панели Ports) выбран и отключен. (Входной регистр, используемый как часть сдвигового регистра, используется в коде DA.)
Add output register (на панели Ports) выбран и отключен.
