С помощью Parallel Computing Toolbox™ можно запускать параллельный код в различных параллельных окружениях, такие как окружения на основе потоков или на основе процессов. Эти окружения обеспечивают различные преимущества.
Обратите внимание, что окружения на основе потоков поддерживают только подмножество MATLAB® функций, доступных для технологических работников. Если вы заинтересованы в функции, которая не поддерживается, сообщите об этом группе технической поддержки MathWorks. Дополнительные сведения о поддержке см. в разделе Проверка поддержки окружении на основе потоков.
В зависимости от типа параллельного окружения, которую вы выбираете, функции выполняются либо на рабочих процессах, либо на рабочих потоках. Чтобы решить, какое окружение вам подходит, смотрите следующую схему и таблицу.
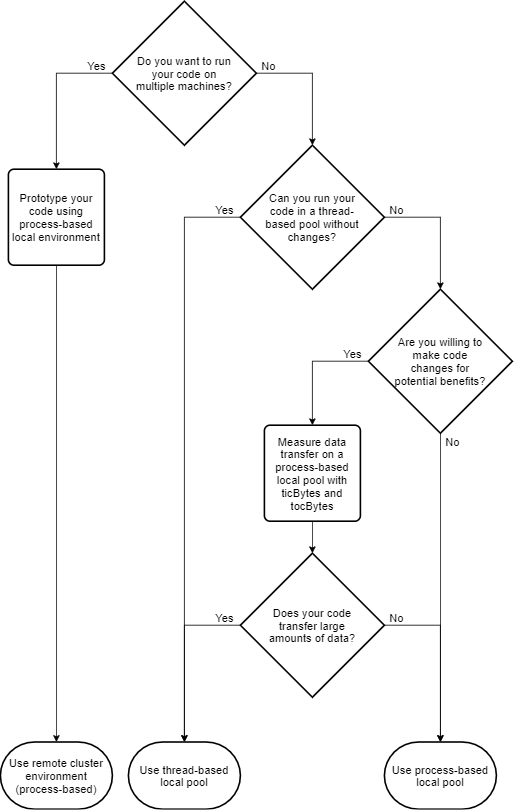
Использование функций параллельного пула, таких как parfor или parfeval, создайте параллельный пул в выбранном окружении с помощью parpool функция.
| Окружение | Рекомендация | Пример |
|---|---|---|
| Окружение на основе потоков на локальной машине | Используйте эту настройку для уменьшения использования памяти, ускорения планирования и снижения затрат на передачу данных. |
parpool('threads')Примечание Если вы выбираете Чтобы узнать, можно ли получить достаточные преимущества от пула на основе потоков, измерьте передачу данных в пуле на основе процессов с |
| Основанные на процессах окружения на локальной машине | Используйте эту настройку для большинства вариантов использования и для прототипирования перед масштабированием в кластеры или облака. |
parpool('local') |
| Основанные на процессах окружения на удаленном кластере | Используйте эту настройку для масштабирования расчетов. | parpool('MyCluster')MyCluster - имя профиля кластера. |
Как использовать функции кластера, такие как batch, создать объект кластера в выбранном окружении при помощи parcluster функция. Обратите внимание, что функции кластера поддерживаются только в окружениях, основанных на процессах.
| Окружение | Рекомендация | Пример |
|---|---|---|
| Основанные на процессах окружения на локальной машине | Используйте эту настройку, если у вас есть достаточные локальные ресурсы, или чтобы прототип перед масштабированием на кластеры или облака. |
parcluster('local') |
| Основанные на процессах окружения на удаленном кластере | Используйте эту настройку для масштабирования расчетов. |
parcluster('MyCluster')где |
Рекомендация
По умолчанию рекомендуется использовать окружения, основанные на процессах.
Они поддерживают полный параллельный язык.
Они назад совместимы с предыдущими релизами.
Они более устойчивы в случае сбоев.
Внешние библиотеки не должны быть безопасными для потоков.
Выбирайте окружения на основе потоков, когда:
Ваш параллельный код поддерживается окружениями на основе потоков.
Вы хотите уменьшить использование памяти, ускорить планирование и снизить затраты на передачу данных.
Ниже показано сравнение производительности между рабочими процессами и рабочими потоками для примера, в котором используется эффективность рабочих потоков.
Создайте некоторые данные.
X = rand(10000, 10000);
Создайте параллельный пул рабочих процессов.
pool = parpool('local');Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
Время выполнения и измерения передачи данных некоторого параллельного кода. В данном примере используйте a parfeval выполнение.
ticBytes(pool);
tProcesses = timeit(@() fetchOutputs(parfeval(@sum,1,X,'all')))
tocBytes(pool)tProcesses = 3.9060
BytesSentToWorkers BytesReceivedFromWorkers
__________________ ________________________
1 0 0
2 0 0
3 0 0
4 0 0
5 5.6e+09 16254
6 0 0
Total 5.6e+09 16254 Обратите внимание, что передача данных является значительной. Чтобы избежать затрат на передачу данных, можно использовать рабочие потоки. Удалите текущий параллельный пул и создайте параллельный пул на основе потоков.
delete(pool);
pool = parpool('threads');Время выполнения того же кода.
tThreads = timeit(@() fetchOutputs(parfeval(@sum,1,X,'all')))tThreads = 0.0232
Сравните время.
fprintf('Without data transfer, this example is %.2fx faster.\n', tProcesses/tThreads)Without data transfer, this example is 168.27x faster.
Рабочие потоки превосходят рабочие процессы, потому что рабочие потоки могут использовать данные X не копируя его, и у них меньше накладных расходов на планирование.
Этот пример показывает, как использовать пул на основе процессов и пул на основе потоков, чтобы решить задачу оптимизации параллельно. Пулы на основе потоков оптимизированы для меньшей передачи данных, более быстрого планирования и уменьшения использования памяти, что может привести к повышению эффективности ваших приложений.
Описание задачи
Задача состоит в том, чтобы изменить положение и угол пушки, чтобы выпустить снаряд как можно дальше за стенкой. Пушка имеет дульную скорость 300 м/с. Стенка составляет 20 м. Если пушка слишком близко к стенке, она стреляет под слишком крутым углом, и снаряд не проходит достаточно далеко. Если пушка слишком далеко от стенки, снаряд не проходит достаточно далеко. Для получения полной информации о задаче смотрите Оптимизацию ОДУ в Parallel (Global Optimization Toolbox) или последнюю часть видео Surrogate Optimization.
Формулировка задачи MATLAB
Чтобы решить проблему, вызовите patternsearch решатель из Global Optimization Toolbox. Целевая функция находится в cannonobjective вспомогательная функция, которая вычисляет расстояние, на которое снаряд приземляется за стенку для заданных положения и угла. Ограничение находится в cannonconstraint функция helper, которая вычисляет, попадает ли снаряд в стенку, или даже достигает стенки перед ударом о землю. Вспомогательные функции находятся в отдельных файлах, которые можно просмотреть, когда вы запускаете этот пример.
Установите следующие входы для patternsearch решатель. Обратите внимание, что, чтобы использовать Parallel Computing Toolbox, вы должны задать 'UseParallel' на true в опциях оптимизации.
lb = [-200;0.05]; ub = [-1;pi/2-.05]; x0 = [-30,pi/3]; opts = optimoptions('patternsearch',... 'UseCompletePoll', true, ... 'Display','off',... 'UseParallel',true); % No linear constraints, so set these inputs to empty: A = []; b = []; Aeq = []; beq = [];
Решение на основе пула процессов
Для сравнения сначала решите задачу в основанном на процессах параллельном пуле.
Запустите параллельный пул рабочих процессов.
p = parpool('local');Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
Чтобы воспроизвести те же расчеты позже, задайте значение по умолчанию для случайного генератора.
rng default;Используйте цикл, чтобы решить проблему несколько раз и усреднить результаты.
tProcesses = zeros(5,1); for repetition = 1:numel(tProcesses) tic [xsolution,distance,eflag,outpt] = patternsearch(@cannonobjective,x0, ... A,b,Aeq,beq,lb,ub,@cannonconstraint,opts); tProcesses(repetition) = toc; end tProcesses = mean(tProcesses)
tProcesses = 2.7677
Чтобы подготовиться к сравнению с пулом на основе потоков, удалите текущий параллельный пул.
delete(p);
Решение на пуле на основе потоков
Запустите параллельный пул рабочих потоков.
p = parpool('threads');Starting parallel pool (parpool) ... Connected to the parallel pool (number of workers: 6).
Восстановите генератор случайных чисел к настройкам по умолчанию и запустите тот же код, что и раньше.
rng default tThreads = zeros(5,1); for repetition = 1:numel(tThreads) tic [xsolution,distance,eflag,outpt] = patternsearch(@cannonobjective,x0, ... A,b,Aeq,beq,lb,ub,@cannonconstraint,opts); tThreads(repetition) = toc; end tThreads = mean(tThreads)
tThreads = 1.5790
Сравнение эффективности рабочих потоков и рабочих процессов.
fprintf('In this example, thread workers are %.2fx faster than process workers.\n', tProcesses/tThreads)In this example, thread workers are 1.75x faster than process workers.
Заметьте коэффициент усиления эффективности из-за оптимизации пула на основе потоков.
Когда вы закончите с расчетами, удалите параллельный пул.
delete(p);
В окружениях, основанных на потоках, функции параллельного языка выполняются для рабочих процессов, поддерживаемых вычислительными потоками, которые запускают код на ядрах на машине. Они отличаются от вычислительных процессов тем, что сосуществуют в одном и том же процессе и могут совместно использовать память.
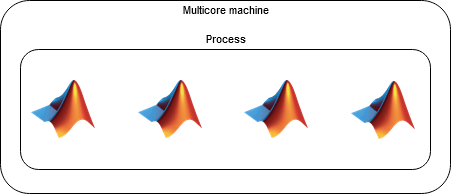
Окружения на основе потоков имеют следующие преимущества по сравнению с окружениями на основе процессов.
Поскольку работники потоков могут совместно использовать память, они могут получить доступ к числовым данным без копирования, поэтому они более эффективны в памяти.
Связь между потоками занимает меньше времени. Поэтому накладные расходы на планирование коммуникации между рабочими или задачами меньше.
Когда вы используете окружения, основанные на потоках, имейте в виду следующие факторы.
Проверьте, что ваш код поддерживается для окружения, основанной на потоках. Для получения дополнительной информации см. раздел «Проверка поддержки окружения на основе потоков».
Если вы используете внешние библиотеки от работников, то необходимо убедиться, что функции библиотеки безопасны для потоков.
В окружениях, основанных на процессах, функции параллельного языка выполняются работниками, поддерживаемыми вычислительными процессами, которые запускают код на ядрах на машине. Они отличаются от вычислительных потоков тем, что они независимы друг от друга.
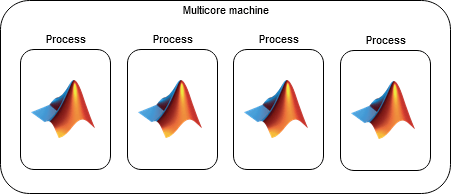
Окружения на основе процессов имеют следующие преимущества по сравнению со окружениями на основе потоков.
Они поддерживают все языковые функции и обратно совместимы с предыдущими релизами.
Они более устойчивы в случае сбоев. Если рабочий процесс завершает работу, клиент MATLAB не аварийно завершает работу. Если рабочий процесс завершает работу, и ваш код не использует spmd или распределенных массивов, тогда остальная часть работников может продолжить работу.
Если вы используете внешние библиотеки от рабочих, то не нужно обращать внимание на thread-safety.
Можно использовать такие функции кластера, как batch.
Когда вы используете основанную на процессах окружение, имейте в виду следующие факторы.
Если ваш код обращается к файлам от рабочих, то вы должны использовать дополнительные опции, такие как 'AttachedFiles' или 'AdditionalPaths', для обеспечения доступности данных.
Рабочие потоки поддерживают только подмножество функций MATLAB, доступных для рабочих процессов. Если вы заинтересованы в функции, которая не поддерживается, сообщите об этом группе технической поддержки MathWorks.
Потоковые рабочие поддерживаются в автономных приложениях, созданных с помощью MATLAB Compiler™ и веб-приложений, размещенных на веб- MATLAB Web App Server™.
Дополнительные сведения о функциях, поддерживаемых рабочими потоками, см. в разделе Проверка поддерживаемых рабочими функциями потоков.
