Прогнозирующее обслуживание позволяет пользователям и производителям оборудования оценивать рабочее условие машин, диагностировать отказы или оценивать, когда может произойти следующий отказ оборудования. Когда вы можете диагностировать или предсказать отказы, вы можете планировать техническое обслуживание заранее, лучше управлять запасами, сократить время простоя и повысить операционную эффективность.
Разработка программы прогнозирующего обслуживания требует хорошо разработанной стратегии для оценки рабочего условия машины и своевременного обнаружения начальных отказов. Это требует эффективного использования как доступных измерений датчика, так и ваших знаний о системе. Вы должны принять во внимание многие факторы, включая:
Наблюдаемые источники разломов и их относительная частота. Такими источниками могут быть основные компоненты машины (такие как блейды рабочего колеса и расходные клапаны в насосе), ее приводы (такие как электродвигатель) или ее различные датчики (такие как акселерометры и расходомеры).
Наличие технологических измерений через датчики. Количество, тип и расположение датчиков, а также их надежность и избыточность влияния как разработка алгоритмов, так и стоимость.
Как различные источники неисправностей приводят к наблюдаемым симптомам. Такой анализ причин может потребовать обширной обработки данных с доступных датчиков.
Физические знания о динамике системы. Эти знания могут быть получены из математического моделирования системы и ее отказов и из понимания экспертов в области. Понимание динамики системы включает в себя подробное знание отношений между различными сигналами от машины (такими как отношения вход-выход между приводами и датчиками), рабочей области значений машины и характера измерений (для примера, периодических, постоянных или стохастических).
Конечная цель технического обслуживания, например, восстановление отказа или разработка графика технического обслуживания.
Программа прогнозирующего обслуживания использует алгоритмы мониторинга условий и прогностики, чтобы анализировать данные, измеренные от системы в операции.
Condition monitoring использует данные от машины, чтобы оценить ее текущее условие и обнаружить и диагностировать отказы в машине. Данные машины - это данные, такие как температура, давление, напряжение, шум или измерения вибрации, собранные с помощью специальных датчиков. Алгоритм мониторинга условия выводит метрики из данных, называемых индикаторами состояния. condition indicator является любой функцией системных данных, поведение которых изменяется предсказуемым образом по мере ухудшения системы. Индикатор состояния может быть любое количество, полученное из данных, которые кластеры одинаковый статус системы вместе и устанавливает различный статус отдельно. Таким образом, алгоритм мониторинга состояния может выполнить обнаружение или диагностику отказа путем сравнения новых данных с установленными маркерами неисправных условий.
Prognostics прогнозирует, когда отказ произойдет на основе текущего и прошлого состояния машины. Алгоритм прогнозирования обычно оценивает remaining useful life машины (RUL) или время до отказа путем анализа текущего состояния машины. Прогностика может использовать моделирование, машинное обучение или комбинацию обоих для предсказания будущих значений индикаторов состояния. Эти будущие значения затем используются для вычисления показателей RUL, которые определяют, должно ли и когда выполняться обслуживание. Для примера коробки передач алгоритм прогностики может соответствовать изменяющейся пиковой частоте вибрации и величины к временным рядам, чтобы предсказать их будущие значения. Затем алгоритм может сравнить предсказанные значения с порогом, определяющим работоспособность операции коробки передач, прогнозируя, произойдет ли и когда отказ.
Система прогнозирующего обслуживания реализует прогнозы и алгоритмы мониторинга условия с другой ИТ-инфраструктурой, что делает конечные результаты алгоритма доступными и действительными для конечных пользователей, которые выполняют фактические задачи обслуживания. Predictive Maintenance Toolbox™ предоставляет инструменты, которые помогут вам проектировать такие алгоритмы.
Следующий рисунок показывает рабочий процесс для разработки прогнозирующего алгоритма обслуживания.
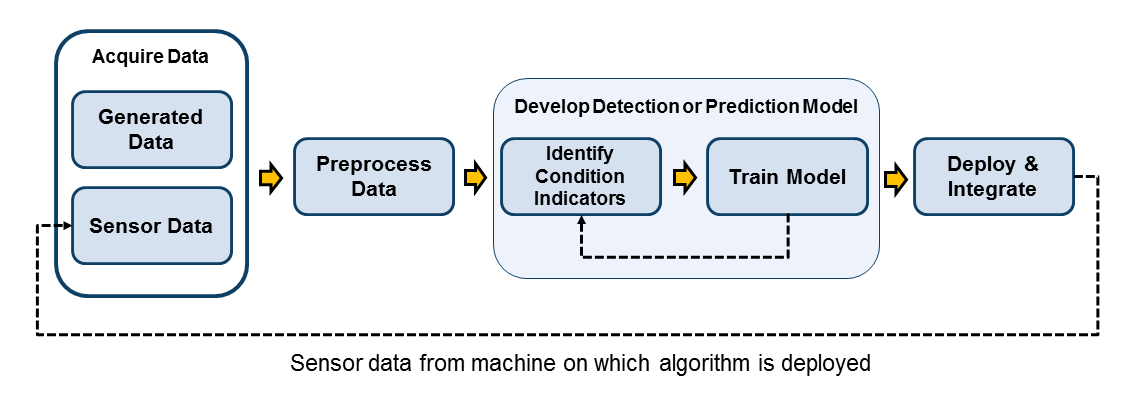
Начиная с данных, которые описывают вашу систему в ряде здоровых и неисправных условий, вы разрабатываете модель обнаружения (для мониторинга условия) или модель предсказания (для прогнозирования). Разработка такой модели требует определения соответствующих индикаторов состояния и обучения модели для их интерпретации. Этот процесс, вероятно, будет итеративным, так как вы пробуете различные индикаторы состояния и различные модели, пока не найдете лучшую модель для вашего приложения. Наконец, вы развертываете алгоритм и интегрируете его в свои системы для мониторинга и обслуживания машин.
Разработка прогнозирующих алгоритмов обслуживания начинается с тела данных. Часто вы должны управлять и обрабатывать большие наборы данных, включая данные с нескольких датчиков и нескольких машин, работающих в разное время и при различных условиях работы. У вас может быть доступ к одному или нескольким из следующих типов данных:
Реальные данные от нормальной операции системы
Реальные данные от системы, работающей в неисправном условии
Реальные данные от отказов системы (run-to-failure данные)
Например, у вас могут быть данные о датчике от операции системы, такие как температура, давление и вибрация. Такие данные обычно хранятся в виде сигнала или данных временных рядов. Вы также можете иметь текстовые данные, такие как данные из записей обслуживания или данные в других формах. Эти данные хранятся в файлах, базах данных или распределенных файловых системах, таких как Hadoop®.
Во многих случаях данные об отказах от машин недоступны, или существует только ограниченное количество наборов данных об отказах из-за регулярного обслуживания и относительной редкости таких инцидентов. В этом случае данные об отказе могут быть сгенерированы из Simulink® модель, представляющая операцию системы в различных условиях отказа.
Predictive Maintenance Toolbox предоставляет функциональные возможности для организации, маркировки и доступа к таким данным, хранящимся на диске. Он также предоставляет инструменты, чтобы облегчить генерацию данных из моделей Simulink для разработки алгоритмов прогнозирующего обслуживания. Для получения дополнительной информации смотрите Data Ensembles для мониторинга условия и прогнозирующего обслуживания.
Предварительная обработка данных часто необходима, чтобы преобразовать данные в форму, из которой индикаторы состояния легко извлекаются. Предварительная обработка данных включает в себя простые методы, такие как удаление выбросов и отсутствующих значений, и расширенные методы обработки сигналов, такие как краткосрочные преобразования Фурье и преобразования в область порядка.
Понимание вашей машины и типа данных, которые вы имеете, может помочь определить, какие методы предварительной обработки использовать. Например, если вы фильтруете зашумленные данные о вибрации, знание того, какая частотная область значений наиболее вероятно отобразит полезные функции, может помочь вам выбрать методы предварительной обработки. Точно так же может быть полезно преобразовать данные о вибрации коробки передач в область порядка точности, которая используется для вращающихся машин, когда скорость вращения изменяется с течением времени. Однако эта же предварительная обработка не была бы полезной для данных о вибрации от шасси автомобиля, которое является жестким корпусом.
Для получения дополнительной информации о предварительной обработке данных для прогнозирующих алгоритмов обслуживания, см. «Предварительная обработка данных для мониторинга условия и прогнозирующего обслуживания».
Ключевым шагом в разработке алгоритмов прогнозирующего обслуживания является идентификация индикаторов состояния, функций в данных вашей системы, поведение которых изменяется предсказуемым образом, когда система ухудшается. Индикатор состояния может быть любой функцией, которая полезна для отличия нормальной и неисправной операции или для прогнозирования оставшегося срока службы. Полезный индикатор состояния группирует одинаковый статус системы вместе и устанавливает различный статус отдельно. Примеры индикаторов состояния включают величины, выведенные из:
Простой анализ, такой как среднее значение данных с течением времени
Более комплексный анализ сигнала, такой как частота пиковой величины в спектре сигнала или статистический момент, описывающий изменения спектра с течением времени
Основанный на модели анализ данных, такой как максимальное собственное значение модели пространства состояний, которая была оценена с использованием данных
Комбинация нескольких функций в один эффективный индикатор состояния (слияние)
Например, контролировать условие коробки передач можно с помощью данных о вибрации. Повреждение коробки передач приводит к изменениям частоты и величины колебаний. Таким образом, пиковая частота и пиковая величина являются полезными индикаторами состояния, предоставляя информацию о типе колебаний, присутствующих в коробке передач. Для мониторинга работоспособности коробки передач можно постоянно анализировать данные о вибрации в частотный диапазон, чтобы извлечь эти индикаторы состояния.
Даже когда у вас есть реальные или моделируемые данные, представляющие область значений условий отказа, вы можете не знать, как анализировать эти данные, чтобы идентифицировать полезные индикаторы состояния. Правильные индикаторы состояния для вашего приложения зависят от типа системы, системных данных и знаний о системе. Поэтому идентификация индикаторов состояния может потребовать некоторых проб и ошибок и часто итеративна с шагом обучения рабочего процесса разработки алгоритмов. Среди методов, обычно используемых для извлечения индикаторов состояния:
Анализ порядков
Модальный анализ
Спектральный анализ
Огибающая спектра
Усталостный анализ
Нелинейный анализ timeseries
Основанный на модели анализ, такие как остаточные расчеты, оценка состояния и оценка параметра
Predictive Maintenance Toolbox дополняет функциональность в других тулбоксах, таких как Signal Processing Toolbox™, функциями для извлечения основанных на сигнале или основанных на модели индикаторов состояния из измеренных или сгенерированных данных. Для получения дополнительной информации см. раздел Идентификация индикаторов состояния.
В основе прогнозирующего алгоритма обслуживания лежит модель обнаружения или предсказания. Эта модель анализирует извлеченные индикаторы состояния, чтобы определить текущее условие системы (обнаружение и диагностика отказа) или предсказать ее будущее условие (прогнозирование оставшегося полезного срока предсказания).
Обнаружение и диагностика отказов основаны на использовании одного или нескольких значений индикатора состояния для различения здоровой и неисправной операции и между различными типами отказов. Простая модель обнаружения отказа является порогом значением для индикатора состояния, которое указывает на условие отказа при превышении. Другая модель может сравнить индикатор состояния со статистическим распределением значений индикатора, чтобы определить вероятность конкретного состояния отказа. Более комплексным подходом к диагностике отказа является обучение классификатора, который сравнивает текущее значение одного или нескольких индикаторов состояния со значениями, связанными с состояниями отказа, и возвращает вероятность того, что то или иное состояние отказа присутствует.
При разработке вашего прогнозирующего алгоритма обслуживания вы можете протестировать различные модели обнаружения и диагностики отказов с использованием различных индикаторов состояния. Таким образом, этот шаг в процессе проекта, вероятно, итеративен с шагом индикаторов состояния извлечения, так как вы пробуете различные индикаторы, различные комбинации индикаторов и различные модели принятия решений. Statistics and Machine Learning Toolbox™ и другие тулбоксы включают функциональность, которую можно использовать для обучения моделей принятия решений, таких как классификаторы и регрессионные модели. Для получения дополнительной информации см. «Модели принятия решений по обнаружению и диагностике отказов».
Примеры моделей предсказания включают:
Модель, которая соответствует временной эволюции индикатора состояния и предсказывает, как долго это будет до того, как индикатор условия перейдет некоторое пороговое значение, указывающее на состояние отказа.
Модель, которая сравнивает временную эволюцию индикатора состояния с измеренными или моделируемыми временными рядами от систем, которые бежали до отказа. Такая модель может вычислить наиболее вероятное время до отказа текущей системы.
Вы можете предсказать оставшийся срок службы путем прогнозирования с помощью динамических системных моделей или оценок состояния. Кроме того, Predictive Maintenance Toolbox включает специализированную функциональность для предсказания RUL, основанную на таких методах, как подобие, порог и анализ выживания. Для получения дополнительной информации смотрите Модели для Предсказания Оставшейся Полезной Жизни.
Когда вы определили рабочий алгоритм для обработки ваших новых системных данных, их соответствующей обработки и генерации предсказания, разверните алгоритм и интегрировайте его в свою систему. Основываясь на специфике вашей системы, можно развернуть алгоритм на облаке или на встраиваемых устройствах.
Реализация облака может быть полезной, когда вы собираете и храните большие объемы данных в облаке. Устранение необходимости передачи данных между облаком и локальными машинами, на которых работает алгоритм прогнозирования и мониторинга состояния, делает процесс обслуживания более эффективным. Результаты, рассчитанные в облаке, могут быть доступны через твиты, уведомления по электронной почте, веб- приложения и панели мониторинга.
В качестве альтернативы алгоритм может запускаться на встраиваемых устройствах, которые ближе к фактическому оборудованию. Основными преимуществами этого являются то, что объем отправляемой информации уменьшается, когда данные передаются только при необходимости, и обновления и уведомления о работоспособности оборудования немедленно доступны.,
Третья опция - использовать комбинацию двух. Части алгоритма предварительной обработки и редукции данных могут запускаться на встраиваемых устройствах, в то время как прогнозирующая модель может запускаться на облаке и генерировать уведомления по мере необходимости. В таких системах, как масляные сверла и авиационные двигатели, которые работают постоянно и генерируют огромное количество данных, хранение всех данных на борту или передача их не всегда жизнеспособно из-за сотовой полосы пропускания и ограничений затрат. Использование алгоритма, который работает с потоковыми данными или с пакетами данных, позволяет хранить и отправлять данные только при необходимости.
MathWorks® генерация кода могут помочь вам с этим шагом рабочего процесса. Для получения дополнительной информации см. Раздел «Развертывание алгоритмов прогнозирующего обслуживания».
[1] Isermann, R. Диагностики отказа Systems: Введение от обнаружения отказа до Допуска отказа. Берлин: Springer Verlag, 2006.
