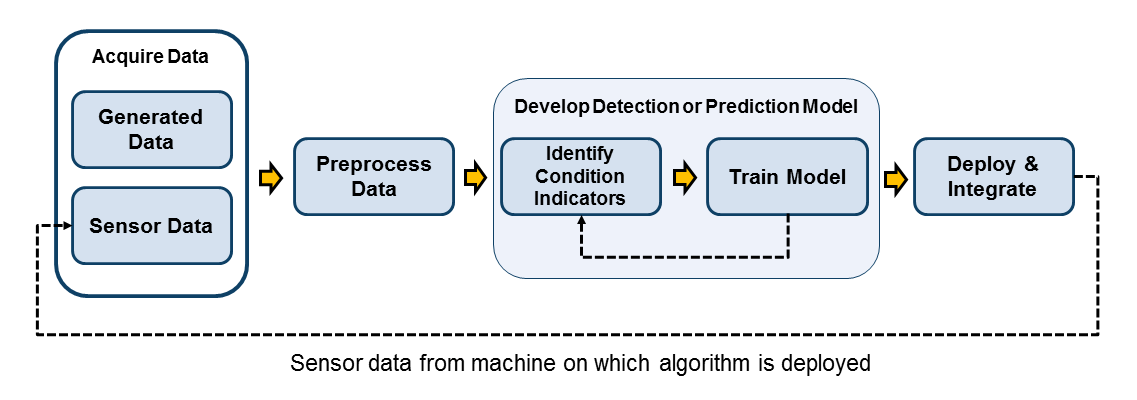
Мониторинг условия включает различение дефектного и исправного состояний (fault detection) или, когда присутствует состояние отказа, определение источника отказа (fault diagnosis). Чтобы спроектировать алгоритм мониторинга условия, вы используете индикаторы состояния, извлеченные из данных системы, чтобы обучить модель принятия решений, которая может анализировать индикаторы, извлеченные из тестовых данных, для определения текущего состояния системы. Таким образом, этот шаг в процессе разработки алгоритма является следующим шагом после идентификации индикаторов состояния.
(Для получения информации об использовании индикаторов состояния для предсказания отказа, смотрите Модели для Прогнозирования Оставшейся Полезной Жизни.)
Некоторые примеры моделей принятия решений для мониторинга условия включают:
Пороговое значение или набор границ значения индикатора состояния, который указывает на отказ, когда индикатор превышает его
Распределение вероятностей, которое описывает вероятность того, что любое конкретное значение индикатора состояния указывает на любой конкретный тип отказа
Классификатор, который сравнивает текущее значение индикатора состояния со значениями, связанными с состояниями отказа, и возвращает вероятность того, что то или иное состояние отказа присутствует
В целом, когда вы тестируете различные модели для обнаружения или диагностики отказов, вы создаете таблицу значений одного или нескольких индикаторов состояния. Индикаторы состояния являются функциями, которые вы извлекаете из данных в ансамбле, представляющих различные здоровые и дефектные условия работы. (См. «Индикаторы состояния» для мониторинга, обнаружения неисправностей и предсказания.) Полезно разбить ваши данные на подмножество, которое вы используете для настройки модели принятия решений (training data) и несвязанное подмножество, которое вы используете для валидации (validation data). По сравнению с обучением и валидацией с перекрывающимися наборами данных использование полностью отдельных данных обучения и валидации обычно дает вам лучшее представление о том, как модель принятия решений будет работать с новыми данными.
При разработке своего алгоритма вы можете протестировать различные модели обнаружения и диагностики отказов с помощью различных индикаторов состояния. Таким образом, этот шаг в процессе проекта, вероятно, итеративен с шагом извлечения индикаторов состояния, так как вы пробуете различные индикаторы, различные комбинации индикаторов и различные модели принятия решений.
Statistics and Machine Learning Toolbox™ и другие тулбоксы включают функциональность, которую можно использовать для обучения моделей принятия решений, таких как классификаторы и регрессионные модели. Здесь обобщены некоторые общие подходы.
Feature selection методы помогают вам уменьшить большие наборы данных, исключив функции, нерелевантные анализу, который вы пытаетесь выполнить. В контексте мониторинга условия нерелевантными функциями являются те, которые не отделяют здоровье от дефектной операции или помогают различать различные состояния отказа. Другими словами, выбор признаков означает идентификацию тех функций, которые подходят для того, чтобы служить индикаторами состояния, потому что они изменяются обнаруживаемым, надежным способом, когда производительность системы ухудшается. Некоторые функции для выбора признаков включают:
pca - Выполните principal component analysis, который находит линейную комбинацию независимых переменных данных, которые составляют наибольшее изменение наблюдаемых значений. Например, предположим, что у вас есть десять независимых сигналов датчика для каждого представителя вашего ансамбля, из которых вы извлекаете много функции. В этом случае анализ основных компонентов может помочь вам определить, какие функции или комбинация признаков наиболее эффективны для разделения различных здоровых и неисправных условий, представленных в вашем ансамбле. Пример Прогнозирования высокоскоростного подшипника ветрогенератора использует этот подход к выбору признаков.
sequentialfs - Для набора функций кандидата идентифицируйте функции, которые лучше всего различают здоровые и дефектные условия, последовательно выбирая функции, пока нет улучшения дискриминации.
fscnca - Выполните выбор признаков для классификации, используя анализ соседних компонентов. Пример Использование Simulink для генерации данных о отказе использует эту функцию, чтобы взвесить список извлеченных индикаторов состояния в соответствии с их важностью для различения условий отказа.
Для получения дополнительной информации о функциях, относящихся к выбору признаков, см. «Уменьшение размерности и Редукции данных».
Когда у вас есть таблица значений индикатора состояния и соответствующих состояний отказа, можно подгонять значения к статистическому распределению. Сравнение валидации или тестовых данных с полученным распределением приводит к вероятности того, что валидация или тестовые данные соответствуют тем или иным состояниям отказа. Некоторые функции, которые можно использовать для такого подбора кривой, включают:
ksdensity - Оцените плотность вероятностей для выборочных данных.
histfit - Сгенерируйте гистограмму из данных и подгоните ее к нормальному распределению. Пример Диагностика отказа центробежных насосов с использованием экспериментов в установившемся состоянии использует этот подход.
ztest - Вероятность тестирования, что данные поступают из нормального распределения с заданным средним и стандартным отклонением.
Для получения дополнительной информации о статистических распределениях смотрите Распределения вероятностей.
Существует несколько способов применения методов машинного обучения к проблеме обнаружения и диагностики отказов. Классификация является типом машинного обучения с учителем, в котором алгоритм «учится» классифицировать новые наблюдения из примеров маркированных данных. В контексте обнаружения и диагностики отказов можно передать индикаторы состояния, выведенные из ансамбля, и соответствующие им метки отказа в функцию подбора алгоритмов, которая обучает классификатор.
Например, предположим, что вы вычисляете таблицу значений индикатора состояния для каждого представителя в ансамбле данных, которая охватывает различные здоровые и неисправные условия. Можно передать эти данные функции, которая подходит для модели классификатора. Это training data обучить модель классификатора принимать набор значений индикаторов состояния, извлеченных из нового набора данных, и предположить, какое исправное или дефектное условие относится к данным. На практике вы используете фрагмент своего ансамбля для обучения, и резервируете непересекающийся фрагмент ансамбля для проверки обученного классификатора.
Statistics and Machine Learning Toolbox включает много функций, которые можно использовать для обучения классификаторов. Эти функции включают:
fitcsvm - Обучите двоичную модель классификации для различения двух состояний, таких как наличие или отсутствие условия отказа. Примеры Использование Simulink для генерации данных о отказе используют эту функцию для обучения классификатора с таблицей основанных на признаках индикаторов состояния. Пример Диагностика отказа центробежных насосов с использованием экспериментов в установившемся состоянии также использует эту функцию с основанными на модели индикаторами состояния, вычисленными из статистических свойств параметров, полученных путем подгонки данных к статической модели.
fitcecoc - Обучите классификатор для различения нескольких состояний. Эта функция сводит многоклассовую задачу классификации к набору двоичных классификаторов. В примере Мультиклассовое Обнаружение Неисправностей с Использованием Смоделированных Данных используется эта функция.
fitctree - Обучите многоклассовую модель классификации путем сокращения задачи до набора двоичных деревьев решений.
fitclinear - Обучите классификатор, используя высокомерные обучающие данные. Эта функция может быть полезной, когда у вас есть большое количество индикаторов состояния, которые вы не можете уменьшить, используя такие функции, как fscnca.
Другие методы машинного обучения включают k-means clustering (kmeans), который разделяет данные на взаимоисключающие кластеры. В этом методе новое измерение назначается кластеру путем минимизации расстояния от точки данных до среднего местоположения назначенного кластера. Древовидная упаковка является еще одним методом, который агрегирует ансамбль деревьев решений для классификации. В примере Диагностика отказа центробежных насосов с использованием экспериментов в установившемся состоянии используется TreeBagger классификатор.
Для получения дополнительной общей информации о методах машинного обучения для классификации, смотрите Классификация.
Другим подходом к обнаружению и диагностике отказов является использование идентификации модели. В этом подходе вы оцениваете динамические модели операции системы в исправных и неисправных состояниях. Затем вы анализируете, какая модель с большей вероятностью объяснит живые измерения из системы. Этот подход полезен, когда у вас есть некоторая информация о вашей системе, которая может помочь вам выбрать тип модели для идентификации. Чтобы использовать этот подход, вы:
Сбор или моделирование данных из системы, работающей в исправном состоянии и в известных дефектных, деградированных или терминальных условиях.
Идентифицируйте динамическую модель, представляющую поведение в каждом исправном и неисправном условии.
Используйте методы кластеризации, чтобы провести четкое различие между условиями.
Собирайте новые данные от машины в операции и идентифицируйте модель ее поведения. Затем можно определить, какая из других моделей, здоровых или неисправных, с наибольшей вероятностью объяснит наблюдаемое поведение.
В примере «Обнаружение отказа с использованием моделей, основанных на данных» используется этот подход. Функции, которые можно использовать для идентификации динамических моделей, включают:
Можно использовать такие функции, как forecast для предсказания будущего поведения идентифицированной модели.
Методы статистического контроля процессов (SPC) являются методами мониторинга и оценки качества промышленных товаров. SPC используется в программах, которые определяют, измеряют, анализируют, улучшают и контролируют процессы разработки и производства. В контексте прогнозирующего обслуживания диаграмм управления и правила управления могут помочь вам определить, когда значение индикатора состояния указывает на отказ. Например, предположим, что у вас есть индикатор состояния, который указывает на отказ, если он превышает порог, но также показывает некоторое нормальное изменение, которое затрудняет идентификацию, когда порог пересечен. Можно использовать правила управления, чтобы задать пороговое условие, как возникающее, когда заданное количество последовательных измерений превышает пороговое, а не только одно.
controlchart - Визуализация управляющей диаграммы.
controlrules - Определить правила управления и определить, нарушены ли они.
cusum - Обнаружение небольших изменений в среднем значении данных.
Для получения дополнительной информации о статистическом управлении процессами смотрите Статистическое управление процессами.
Другой способ обнаружения условий отказа - это отслеживать значение индикатора состояния с течением времени и обнаруживать резкие изменения в поведении тренда. Такие резкие изменения могут указывать на отказ. Некоторые функции, которые можно использовать для такого обнаружения точек изменения, включают:
findchangepts - Найти резкие изменения в сигнале.
findpeaks - Найти peaks в сигнале.
pdist, pdist2, mahal - Найти расстояние между измерениями или наборами измерений, согласно различным определениям расстояния.
segment - Сегментные данные и оценка моделей AR, ARX, ARMA или ARMAX для каждого сегмента. В примере «Обнаружение отказа с использованием моделей, основанных на данных» используется этот подход.
