Чтобы настроить обучение агента в приложении Reinforcement Learning Designer, задайте опции обучения на вкладке Train.

На вкладке Train можно задать следующие основные опции обучения.
| Опция | Описание |
|---|---|
| Max Episodes | Максимальное количество эпизодов для обучения агента, заданное как положительное целое число. |
| Max Episode Length | Максимальное количество шагов для запуска в каждом эпизоде, заданное как положительное целое число. |
| Stopping Criteria | Условие завершения обучения, заданное как одно из следующих значений.
|
| Stopping Value | Критическое значение условия завершения обучения в Stopping Criteria, заданное как скаляр. |
| Average Window Length | Длина окна для усреднения счетов, вознаграждений и количества шагов для агента при Stopping Criteria или Save agent criteria задании условия усреднения. |
Чтобы задать дополнительные опции обучения, на вкладке Train нажмите More Options.
В диалоговом окне «Дополнительные опции обучения» можно задать следующие опции.
| Опция | Описание |
|---|---|
| Save agent criteria | Условие сохранения агентов во время обучения, заданное как одно из следующих значений.
|
| Save agent value | Критическое значение условия агента сохранения в Save agent criteria, заданное как скаляр или "none". |
| Save directory | Папка для сохраненных агентов. Если вы задаете имя, а папка не существует, приложение создает папку в текущей рабочей директории. Чтобы в интерактивном режиме выбрать папку, нажмите Browse. |
| Show verbose output | Выберите эту опцию, чтобы отобразить процесс обучения в командной строке. |
| Stop on Error | Выберите эту опцию, чтобы остановить обучение, когда ошибка возникает во время эпизода. |
| Training plot | Опция для графического отображения процесса обучения в приложении, заданная как одно из следующих значений.
|
Чтобы обучить агента с помощью параллельных вычислений, на вкладке Train, нажмите. ![]() Для обучения агентов с помощью параллельных вычислений требуется программное обеспечение Parallel Computing Toolbox™. Для получения дополнительной информации смотрите Train агентов с использованием параллельных вычислений и графических процессоров.
Для обучения агентов с помощью параллельных вычислений требуется программное обеспечение Parallel Computing Toolbox™. Для получения дополнительной информации смотрите Train агентов с использованием параллельных вычислений и графических процессоров.
Чтобы задать опции для параллельного обучения, выберите Use Parallel > Parallel training options.
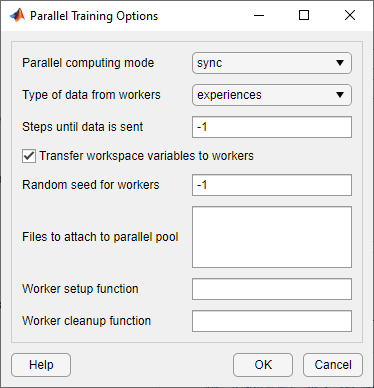
В диалоговом окне Опции параллельного обучения (Parallel Training Options) можно задать следующие опции обучения.
| Опция | Описание |
|---|---|
| Parallel computing mode | Режим параллельных вычислений, заданный как одно из следующих значений.
|
| Type of data from workers | Тип данных, которые рабочие передают на хост, задается как одно из следующих значений.
Примечание Для DQN, DDPG, PPO и TD3 необходимо задать эту опцию |
| Steps until data is sent | Количество шагов, после которых работники отправляют данные на хост и получают обновленные параметры, заданное как |
| Transfer workspace variables to workers | Выберите эту опцию, чтобы отправить переменные модели и рабочей области параллельным рабочим. Когда вы выбираете эту опцию, хост отправляет переменные, используемые в моделях и определенные в MATLAB® рабочей области рабочим. |
| Random seed for workers | Инициализация рандомизатора для рабочих процессов, заданная как одно из следующих значений.
|
| Files to attach to parallel pool | Дополнительные файлы для присоединения к параллельному пулу. Укажите имена файлов в текущей рабочей директории с одним именем в каждой линии. |
| Worker setup function | Функция для выполнения перед началом обучения, заданная как указатель на функцию, не имеющую входных параметров. Эта функция запускается один раз на каждого работника перед началом обучения. Напишите эту функцию, чтобы выполнить любую обработку, которая вам нужна до обучения. |
| Worker cleanup function | Функция для выполнения после окончания обучения, заданная как указатель на функцию, не имеющую входных параметров. Можно записать эту функцию, чтобы очистить рабочую область или выполнить другую обработку после завершения обучения. |
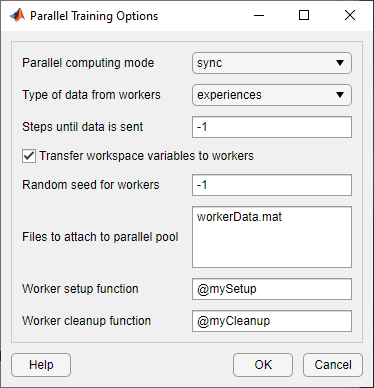
Следующий рисунок показывает пример параллельного строения обучения следующих файлов и функций.
Файл данных, присоединенный к параллельному пулу - workerData.mat
Функция настройки работника - mySetup.m
Функция очистки рабочих - myCleanup.m
Reinforcement Learning Designer
