В этом примере показано, как спроектировать и обучить агента DQN для окружения с дискретным пространством действий, используя Reinforcement Learning Designer.
Откройте приложение Reinforcement Learning Designer.
reinforcementLearningDesigner
Первоначально никакие агенты или окружения не загружаются в приложение.
При использовании Reinforcement Learning Designer можно импортировать окружение из MATLAB® рабочей области или создать предопределённое окружение. Для получения дополнительной информации смотрите Создать окружения MATLAB для Reinforcement Learning Designer и Создать окружения Simulink для Reinforcement Learning Designer.
В данном примере используйте предопределенную дискретную тележку с шестом MATLAB окружения. Чтобы импортировать это окружение, на вкладке Reinforcement Learning, в разделе Environments, выберите New > Discrete Cart-Pole.
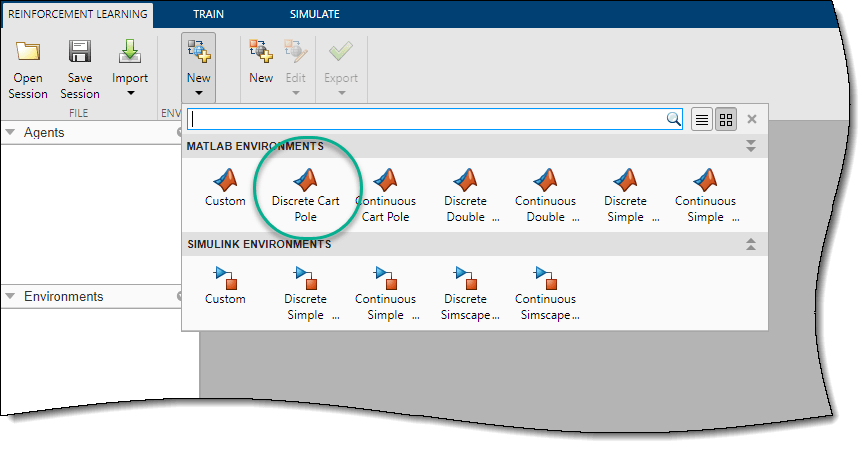
На панели Environments приложение добавляет импортированную Discrete CartPole окружение. Чтобы переименовать окружение, щелкните текст окружения. Можно также импортировать несколько окружения в сеансе.
Чтобы просмотреть размерности пространства наблюдений и действий, щелкните текст окружения. Приложение показывает размерности на панели Preview.
![The Preview pane shows the dimensions of the state and action spaces being [4 1] and [1 1], respectively](app_dqn_cartpole_03b.png)
Это окружение имеет непрерывное четырехмерное пространство наблюдений (положения и скорости как тележки, так и полюса) и дискретное одномерное пространство действий, состоящее из двух возможных сил, -10N или 10N. Это окружение используется в примере Train DQN Agent для балансировки системы тележки с шестом. Дополнительные сведения о предопределенных окружениях системы управления см. в разделе Загрузка предопределять Окружениях системы управления.
Чтобы создать агента, на вкладке Reinforcement Learning, в разделе Agent, нажмите New. В диалоговом окне Create agent укажите имя агента, окружение и алгоритм настройки. В данном примере сохраните строение агента по умолчанию, которая использует импортированное окружение и алгоритм DQN. Дополнительные сведения о создании агентов см. в разделе Создание агентов с использованием Reinforcement Learning Designer.
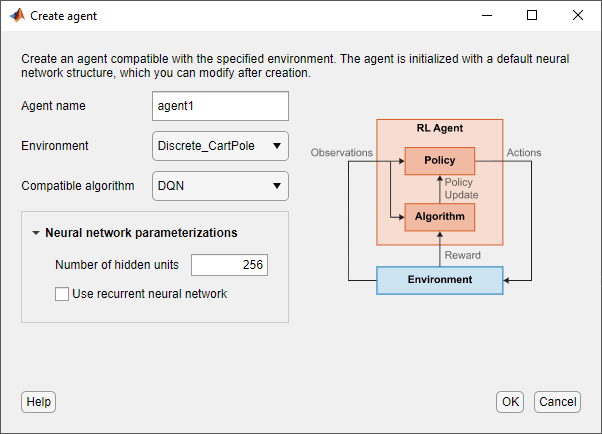
Нажмите OK.
Приложение добавляет нового агента в область Agents и открывает соответствующий Agent_1 документ.
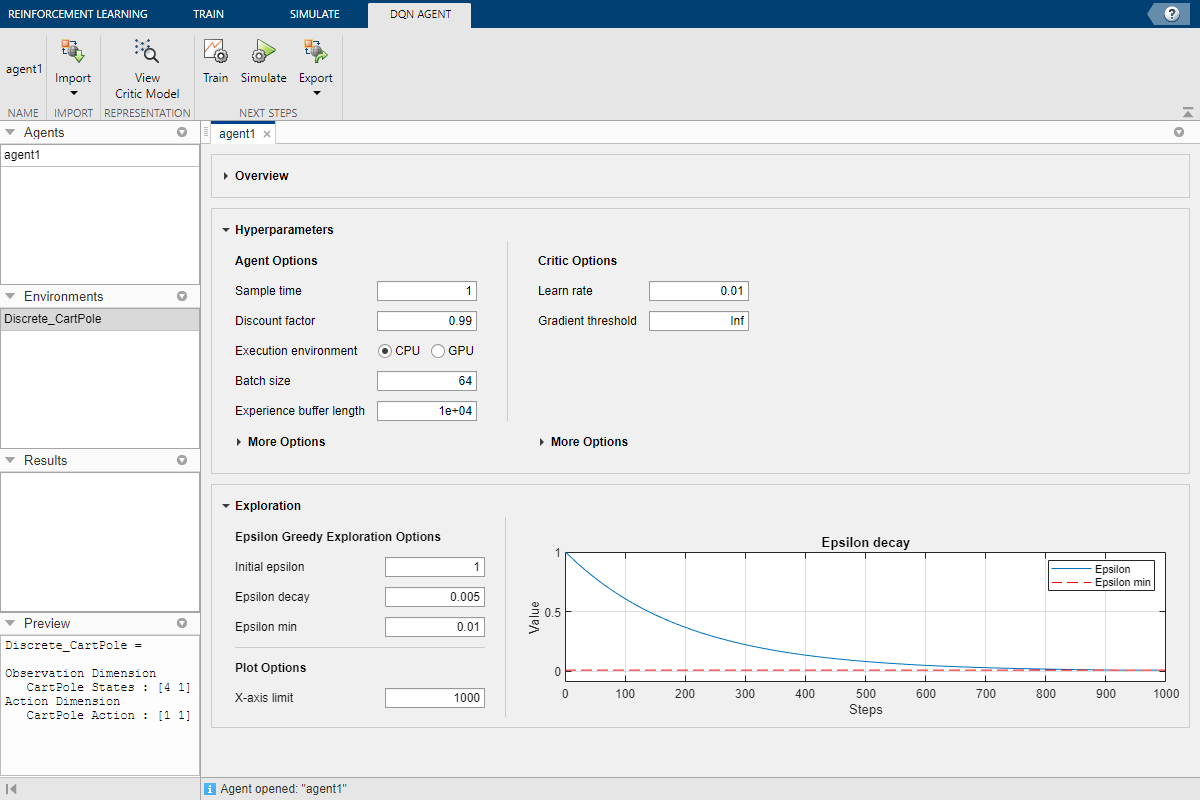
Для кратких сводных данных функций агента DQN и просмотра наблюдений и спецификаций действия для агента нажмите Overview.
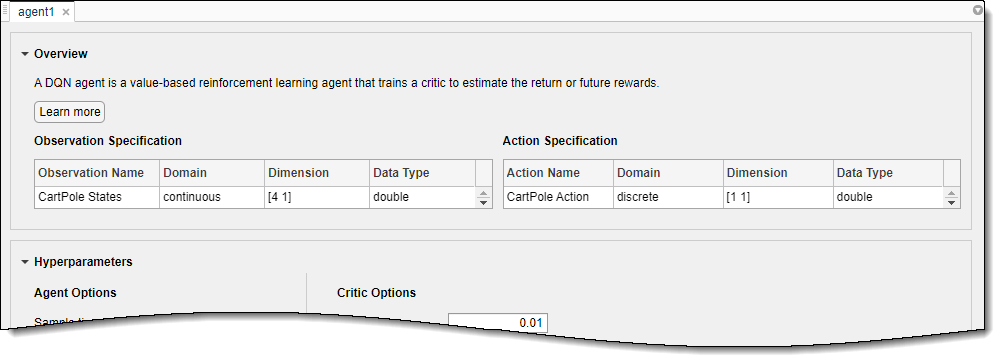
Когда вы создаете агента DQN в Reinforcement Learning Designer, агент использует структуру глубокой нейронной сети по умолчанию для своего критика. Чтобы просмотреть сеть критика, на вкладке DQN Agent, нажмите View Critic Model.
Откроется Deep Learning Network Analyzer и отобразит структуру критика.
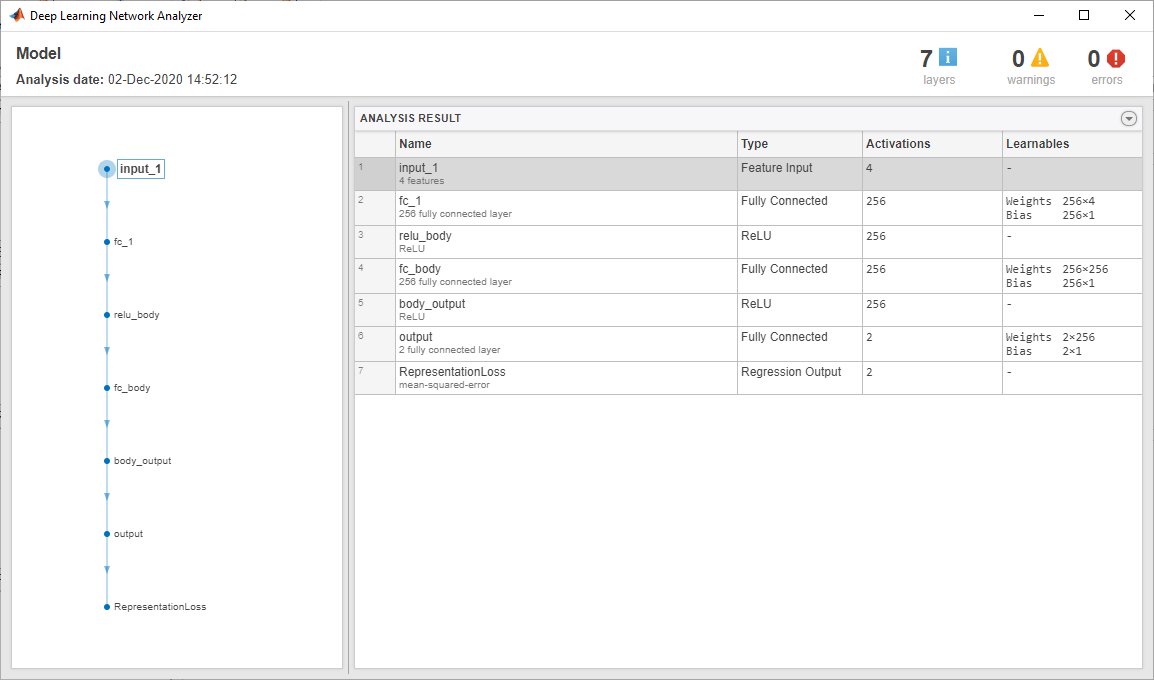
Закройте Deep Learning Network Analyzer.
Чтобы обучить агента, на вкладке Train сначала задайте опции для обучения агента. Для получения информации об указании опций обучения смотрите Задать Симуляцию Опций в Reinforcement Learning Designer.
В данном примере задайте максимальное количество эпизодов тренировки путем установки значения Max Episodes 1000. Для других опций обучения используйте их значения по умолчанию. Критерием по умолчанию для остановки является время, когда среднее количество шагов на эпизод (за последний 5 эпизоды) больше 500.

Чтобы начать обучение, нажмите Train.
Во время обучения приложение открывает вкладку Training Session и отображает процесс обучения в Training Results документе.
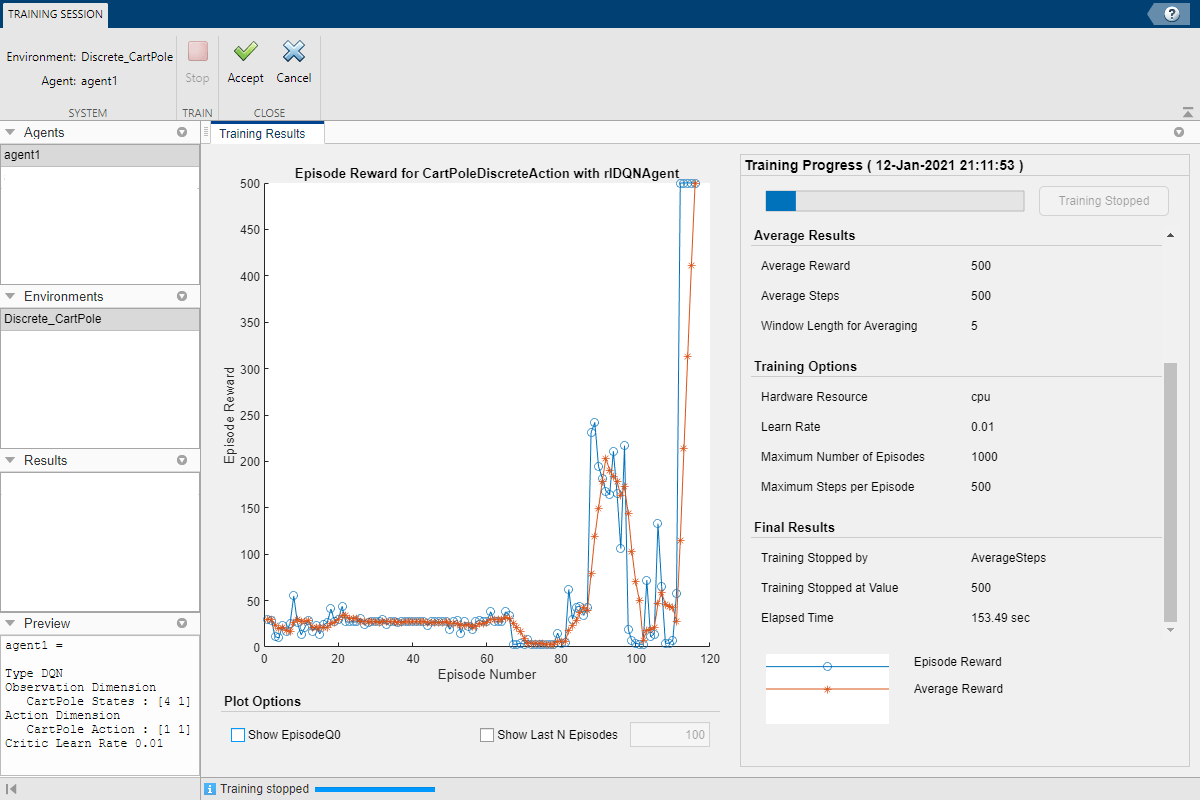
Здесь обучение останавливается, когда среднее количество шагов на эпизод составляет 500.
Чтобы принять результаты обучения, на вкладке Training Session нажмите Accept. На панели Agents приложение добавляет обученного агента agent1_Trained.
Чтобы симулировать обученного агента, на вкладке Simulate сначала выберите agent1_Trained в раскрывающемся списке Agent, затем настройте опции симуляции. В данном примере используйте количество эпизодов по умолчанию (10) и максимальная длина эпизода (500). Для получения дополнительной информации об указании параметров симуляции см. Опции «Задание опций обучения» в Reinforcement Learning Designer.
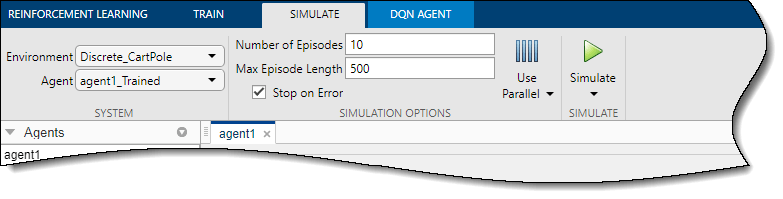
Чтобы симулировать агента, нажмите Simulate.
Приложение открывает вкладку Simulation Session. После завершения симуляции в Simulation Results документе показано вознаграждение для каждого эпизода, а также среднее вознаграждение и стандартное отклонение.
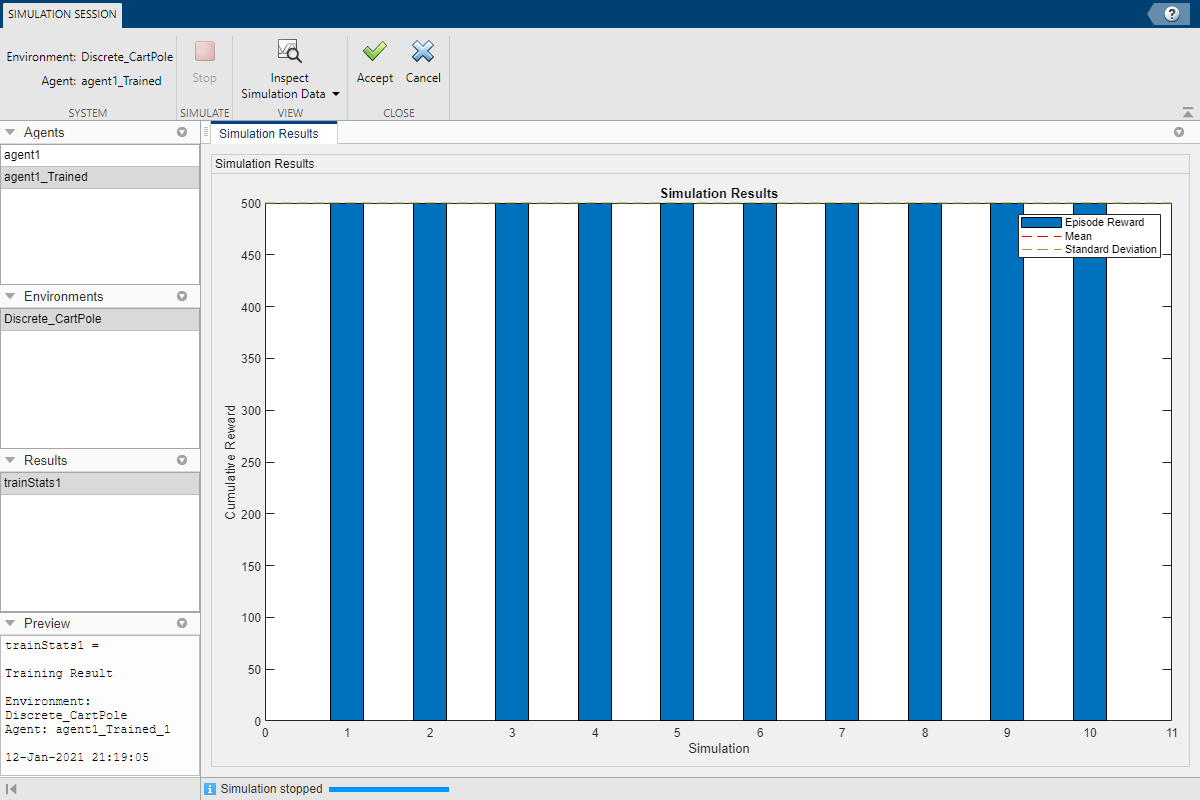
Чтобы проанализировать результаты симуляции, нажмите Inspect Simulation Data.
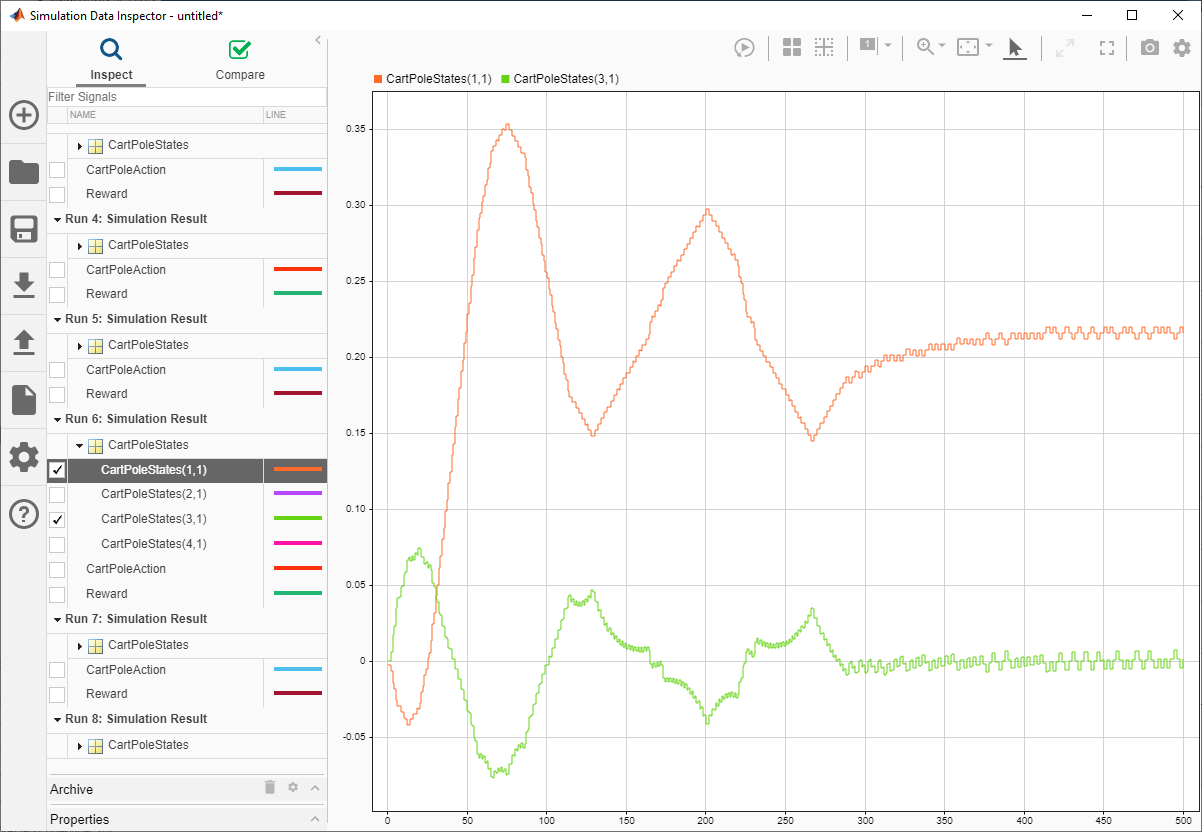
В Simulation Data Inspector можно просмотреть сохраненные сигналы для каждого эпизода симуляции. На следующем изображении показаны первое и третье состояния системы тележки с шестом (положение тележки и угол шеста) для шестого эпизода симуляции. Агент успешно балансирует полюс с углом около нуля.
Для получения дополнительной информации смотрите Данные моделирования Inspector (Simulink).
Закройте Simulation Data Inspector.
Чтобы принять результаты симуляции, на вкладке Simulation Session нажмите Accept.
На панели Results приложение добавляет структуру результатов симуляции experience1.
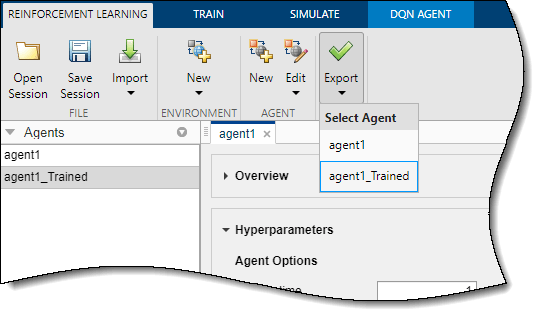
Чтобы экспортировать обученного агента в рабочее пространство MATLAB для дополнительной симуляции, на вкладке Reinforcement Learning, под Export, выберите агента.
Чтобы сохранить сеанс приложения, на вкладке Reinforcement Learning нажмите Save Session. В дальнейшем, чтобы возобновить работу там, где вы остановились, можно открыть сеанс в Reinforcement Learning Designer.
Чтобы симулировать агент в командной строке MATLAB, сначала загрузите окружение тележки с шестом.
env = rlPredefinedEnv("CartPole-Discrete");Окружение тележки с шестом имеет визуализатор окружения, который позволяет вам видеть, как система ведет себя во время симуляции и обучения.
Постройте график окружения и выполните симуляцию, используя обученного агента, который вы ранее экспортировали из приложения.
plot(env) xpr2 = sim(env,agent1_Trained);
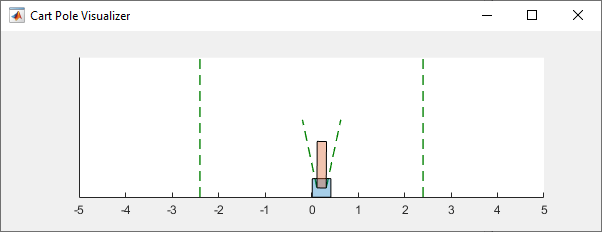
Во время симуляции визуализатор показывает движение тележки и шеста. Обученный агент способен быстро стабилизировать систему.
Наконец, отобразите совокупное вознаграждение для симуляции.
sum(xpr2.Reward)
env = 500
Как и ожидалось, вознаграждение составляет 500.
analyzeNetwork | Reinforcement Learning Designer
