Классификация точек запроса на основе их расстояния до точек в обучающие данные наборе может быть простым, но эффективным способом классификации новых точек. Для определения расстояния можно использовать различные метрики, описанные далее. Использовать pdist2 чтобы найти расстояние между набором данных и точками запроса.
Учитывая mx n матрицей данных X, который рассматривает как mx (1-by-<reservedrangesplaceholder13>) векторы - строки x1, x2..., xmx, и my n матрица данных Y, который рассматривают как my (1-by-<reservedrangesplaceholder5>) векторы - строки y1, y2..., ymy, различные расстояния между вектором xs и yt определены следующим образом:
Евклидово расстояние
Евклидово расстояние является частным случаем расстояния Минковского, где p = 2.
Стандартизированное Евклидово расстояние
где V - n -by n диагональная матрица, j-й диагональный элемент которой (S (j))2, где S является вектором масштабирующих коэффициентов для каждой размерности.
Расстояние Махаланобиса
где C - ковариационная матрица.
Расстояние между блоками
Расстояние городского блока является частным случаем расстояния Минковского, где p = 1.
Расстояние Минковского
Для особого случая p = 1 расстояние Минковского даёт городскую блочную дистанцию. Для особого случая p = 2 расстояние Минковского даёт евклидово расстояние. Для особого случая p = ∞ дистанция Минковского даёт дистанцию Чебычева.
Чебычевская дистанция
Дистанция Чебычева является частным случаем дистанции Минковского, где p = ∞.
Косинусоидальное расстояние
Расстояние корреляции
где
и
Расстояние Хемминга
Расстояние Жаккара
Расстояние копьеносца
где
rsj - это ранг xsj, занятый x 1 j, x 2 j,... xmx,j, как вычисляетсяtiedrank.
rtj - это ранг ytj, занятый y 1 j, y 2 j,... ymy,j, как вычисляетсяtiedrank.
rs и rt являются координатно-ранговыми векторами xs и yt, то есть rs = (rs 1, rs 2,... rsn) и rt = (r t 1, r t 2,... rtn).
.
.
Учитывая X n точек и функцию расстояния, k ближайшего соседа (k NN) поиск позволяет вам найти k ближайшие точки в X к точке запроса или набору точек Y. Метод k поиска NN и k алгоритмов на основе NN широко используются в качестве эталонных правил обучения. Относительная простота k метода поиска NN облегчает сравнение результатов других методов классификации с k результатов NN. Метод использовался в различных областях, таких как:
биоинформатика
обработка изображений и сжатие данных
поиск документов
компьютерное зрение
мультимедийная база данных
анализ маркетинговых данных
Можно использовать поиск k NN для других алгоритмов машинного обучения, таких как:
k классификацию NN
локальная взвешенная регрессия
отсутствующие вменения данных и интерполяция
оценка плотности
Можно также использовать поиск k NN со многими дистанционными функциями обучения, такими как кластеризация K-средних значений.
Напротив, для положительного реального значения r, rangesearch находит все точки в X которые находятся на расстоянии r каждой точки в Y. Этот поиск с фиксированным радиусом тесно связан с k поиском NN, так как он поддерживает те же метрики расстояния и классы поиска и использует те же алгоритмы поиска.
Когда ваши входные данные удовлетворяют любому из следующих критериев, knnsearch использует метод исчерпывающего поиска по умолчанию, чтобы найти k - ближайших соседей :
Количество столбцов X более 10.
X является разреженным.
Метрика расстояния либо:
'seuclidean'
'mahalanobis'
'cosine'
'correlation'
'spearman'
'hamming'
'jaccard'
Пользовательская функция расстояния
knnsearch также использует метод исчерпывающего поиска, если ваш объект поиска является ExhaustiveSearcher объект модели. Метод исчерпывающего поиска находит расстояние от каждой точки запроса до каждой точки в X, ранжирует их в порядке возрастания и возвращает k точки с наименьшими расстояниями. Для примера эта схема показывает k = 3 ближайших соседей.
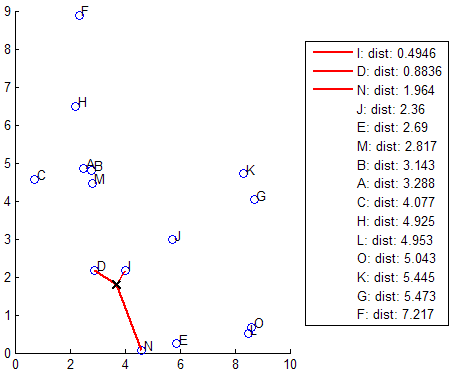
Когда ваши входные данные удовлетворяют всем следующим критериям, knnsearch создает K d-дерево по умолчанию, чтобы найти k - ближайших соседей:
Количество столбцов X меньше 10.
X не разрежен.
Метрика расстояния либо:
'euclidean' (по умолчанию)
'cityblock'
'minkowski'
'chebychev'
knnsearch также использует K d-дерево, если ваш объект поиска является KDTreeSearcher объект модели.
K d-деревья делят ваши данные на узлы, самое большее BucketSize (по умолчанию это 50) точек на узел, основанных на координатах (в отличие от категорий). Следующие схемы иллюстрируют эту концепцию, используя patch объекты для цветового кода различных «блоков».
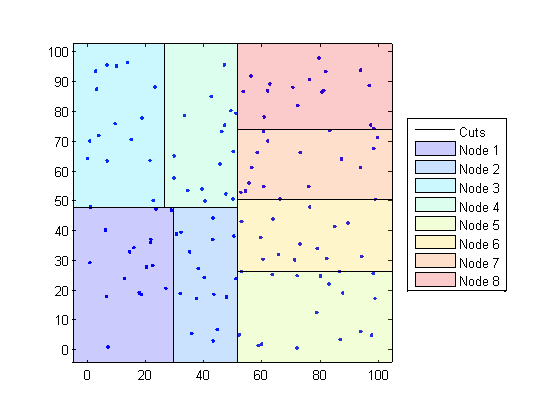
Когда вы хотите найти k - ближайших соседей к заданной точке запроса, knnsearch делает следующее:
Определяет узел, которому принадлежит точка запроса. В следующем примере точка запроса (32,90) принадлежит узлу 4.
Находит ближайшие k точки в этом узле и его расстояние до точки запроса. В следующем примере точки в красных кругах равноудалены от точки запроса и являются ближайшими точками к точке запроса в узле 4.
Выбирает все другие узлы, имеющие любую область, которая находится на том же расстоянии, в любом направлении, от точки запроса до k-й ближайшей точки. В этом примере только Узел 3 перекрывает сплошной черный круг с центром в точке запроса с радиусом, равным расстоянию до ближайших точек в Узле 4 .
Ищет в узлах этой области значений любые точки ближе к точке запроса. В следующем примере точка в красном квадрате немного ближе к точке запроса, чем точки в узле 4.
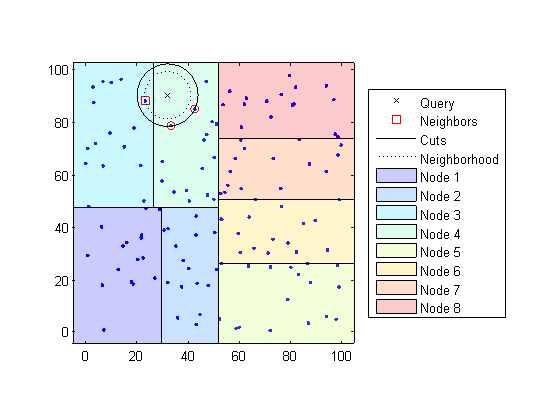
Использование K d-дерева для больших наборов данных с менее чем 10 размерностями (столбцами) может быть намного более эффективным, чем использование исчерпывающего метода поиска, как knnsearch нужно вычислить только подмножество расстояний. Чтобы максимизировать эффективность K d-деревьев, используйте KDTreeSearcher модель.
В основном объекты модели являются удобным способом хранения информации. Связанные модели имеют те же свойства со значениями и типами, релевантными заданному методу поиска. В дополнение к хранению информации в моделях можно выполнить определенные действия над моделями.
Вы можете эффективно выполнить поиск по k-ближайшим соседям на вашей модели поиска, используяknnsearch. Или можно искать всех соседей в заданном радиусе, используя вашу модель поиска и rangesearch. В сложение существуют дженерик knnsearch и rangesearch функции, которые ищут, не создавая и не используя модель.
Чтобы определить, какой тип модели и метода поиска лучше всего подходит для ваших данных, примите к сведению следующее:
Ваши данные имеют много столбцов, скажем, больше 10? The ExhaustiveSearcher модель может работать лучше.
Ваши данные разрежены? Используйте ExhaustiveSearcher модель.
Вы хотите использовать одну из этих метрик расстояния, чтобы найти ближайших соседей? Используйте ExhaustiveSearcher модель.
'seuclidean'
'mahalanobis'
'cosine'
'correlation'
'spearman'
'hamming'
'jaccard'
Пользовательская функция расстояния
Ваш набор данных огромен (но с менее чем 10 столбцами)? Используйте KDTreeSearcher модель.
Вы ищете ближайших соседей для большого количества точек запроса? Используйте KDTreeSearcher модель.
В этом примере показано, как классифицировать данные запроса по:
Выращивание Kd-дерева
Проведение k ближайшего поиска соседа с помощью выращенного дерева.
Присвоение каждой точке запроса класса с самым высоким представлением среди их соответствующих ближайших соседей.
Классификация новой точки на основе последних двух столбцов данных радужной оболочки глаза Фишера. Использование только последних двух столбцов облегчает построение графика.
load fisheriris x = meas(:,3:4); gscatter(x(:,1),x(:,2),species) legend('Location','best')

Постройте график новой точки.
newpoint = [5 1.45]; line(newpoint(1),newpoint(2),'marker','x','color','k',... 'markersize',10,'linewidth',2)

Подготовим модель Kd-tree neighbor searcher.
Mdl = KDTreeSearcher(x)
Mdl =
KDTreeSearcher with properties:
BucketSize: 50
Distance: 'euclidean'
DistParameter: []
X: [150x2 double]
Mdl является KDTreeSearcher модель. По умолчанию метрика расстояния, которую он использует для поиска соседей, является евклидовым расстоянием.
Найдите 10 точки выборки ближе к новой точке.
[n,d] = knnsearch(Mdl,newpoint,'k',10); line(x(n,1),x(n,2),'color',[.5 .5 .5],'marker','o',... 'linestyle','none','markersize',10)

Кажется, что knnsearch нашел только ближайших восьми соседей. Фактически, этот конкретный набор данных содержит повторяющиеся значения.
x(n,:)
ans = 10×2
5.0000 1.5000
4.9000 1.5000
4.9000 1.5000
5.1000 1.5000
5.1000 1.6000
4.8000 1.4000
5.0000 1.7000
4.7000 1.4000
4.7000 1.4000
4.7000 1.5000
Сделайте ось равной, чтобы вычисленные расстояния соответствовали видимым расстояниям на оси графика равными и увеличьте изображение, чтобы увидеть соседей лучше.
xlim([4.5 5.5]);
ylim([1 2]);
axis square
Найдите вид 10 соседей.
tabulate(species(n))
Value Count Percent virginica 2 20.00% versicolor 8 80.00%
Используя правило, основанное на большинстве голосов 10 ближайших соседей, можно классифицировать эту новую точку как версиколор.
Визуально идентифицируйте соседей путем нанесения окружности вокруг группы из них. Определите центр и диаметр окружности на основе расположения новой точки.
ctr = newpoint - d(end); diameter = 2*d(end); % Draw a circle around the 10 nearest neighbors. h = rectangle('position',[ctr,diameter,diameter],... 'curvature',[1 1]); h.LineStyle = ':';

Используя тот же набор данных, найдите 10 ближайших соседей к трем новым точкам.
figure newpoint2 = [5 1.45;6 2;2.75 .75]; gscatter(x(:,1),x(:,2),species) legend('location','best') [n2,d2] = knnsearch(Mdl,newpoint2,'k',10); line(x(n2,1),x(n2,2),'color',[.5 .5 .5],'marker','o',... 'linestyle','none','markersize',10) line(newpoint2(:,1),newpoint2(:,2),'marker','x','color','k',... 'markersize',10,'linewidth',2,'linestyle','none')

Найдите вид 10 ближайших соседей для каждой новой точки.
tabulate(species(n2(1,:)))
Value Count Percent virginica 2 20.00% versicolor 8 80.00%
tabulate(species(n2(2,:)))
Value Count Percent virginica 10 100.00%
tabulate(species(n2(3,:)))
Value Count Percent
versicolor 7 70.00%
setosa 3 30.00%
Для получения дополнительных примеров используйте knnsearch методы и функции, см. отдельные страницы с описанием.
В этом примере показано, как найти индексы трех ближайших наблюдений в X каждому наблюдению в Y относительно расстояния хи-квадрат. Эта метрика расстояния используется в соответствующем анализе, особенно в экологических приложениях.
Случайным образом сгенерируйте нормально распределенные данные в две матрицы. Количество строк может меняться, но количество столбцов должно быть равным. Этот пример использует 2D данные для графического изображения.
rng(1) % For reproducibility X = randn(50,2); Y = randn(4,2); h = zeros(3,1); figure h(1) = plot(X(:,1),X(:,2),'bx'); hold on h(2) = plot(Y(:,1),Y(:,2),'rs','MarkerSize',10); title('Heterogeneous Data')

Строки X и Y соответствуют наблюдениям, и столбцы, в общем, размерности (для примера, предикторы).
Расстояние хи-квадрат между j-мерными точками x и z равняется
где - вес, сопоставленный с размерностью j.
Выберите веса для каждой размерности и задайте функцию хи-квадрат расстояния. Функция расстояния должна:
Взять за входные параметры одну строку X, например, x, и матрица Z.
Сравнение x в каждую строку Z.
Верните вектор D длины , где количество строк Z. Каждый элемент D - расстояние между наблюдением, соответствующим x и наблюдения, соответствующие каждой строке Z.
w = [0.4; 0.6]; chiSqrDist = @(x,Z)sqrt((bsxfun(@minus,x,Z).^2)*w);
Этот пример использует произвольные веса для рисунка.
Найдите индексы трех ближайших наблюдений в X каждому наблюдению в Y.
k = 3; [Idx,D] = knnsearch(X,Y,'Distance',chiSqrDist,'k',k);
idx и D представляют собой матрицы 4 на 3.
idx(j,1) - индекс строка ближайшего наблюдения в X к наблюдению j Y, и D(j,1) их расстояние.
idx(j,2) - индекс строки следующего ближайшего наблюдения в X к наблюдению j Y, и D(j,2) их расстояние.
И так далее.
Идентифицируйте ближайшие наблюдения на графике.
for j = 1:k h(3) = plot(X(Idx(:,j),1),X(Idx(:,j),2),'ko','MarkerSize',10); end legend(h,{'\texttt{X}','\texttt{Y}','Nearest Neighbor'},'Interpreter','latex') title('Heterogeneous Data and Nearest Neighbors') hold off

Несколько наблюдений за Y поделиться ближайшими соседями.
Проверьте, что метрика хи-квадратного расстояния эквивалентна метрике Евклидова расстояния, но с необязательным параметром масштабирования.
[IdxE,DE] = knnsearch(X,Y,'Distance','seuclidean','k',k, ... 'Scale',1./(sqrt(w))); AreDiffIdx = sum(sum(Idx ~= IdxE))
AreDiffIdx = 0
AreDiffDist = sum(sum(abs(D - DE) > eps))
AreDiffDist = 0
Индексы и расстояния между двумя реализациями трех ближайших соседей практически эквивалентны.
The ClassificationKNN классификационная модель позволяет вам:
Подготовьте свои данные к классификации в соответствии с процедурой, описанной в шагах в надзорном обучении. Затем создайте классификатор, используя fitcknn.
Этот пример показывает, как создать k-ближайших соседей классификатор для данных радужной оболочки глаза Фишера.
Загрузите данные радужки Фишера.
load fisheriris X = meas; % Use all data for fitting Y = species; % Response data
Создайте классификатор с помощью fitcknn.
Mdl = fitcknn(X,Y)
Mdl =
ClassificationKNN
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
Distance: 'euclidean'
NumNeighbors: 1
Properties, Methods
Классификатор k-ближайших соседей по умолчанию использует только один ближайший соседь. Часто классификатор более прочен с большим количеством соседей.
Измените размер окрестности Mdl на 4, что означает, что Mdl классифицирует с использованием четырех ближайших соседей.
Mdl.NumNeighbors = 4;
В этом примере показано, как изучить качество k-ближайших соседей классификатора с помощью реституции и перекрестной валидации.
Создайте классификатор KNN для данных ириса Фишера, как в Construct KNN Classifier.
load fisheriris X = meas; Y = species; rng(10); % For reproducibility Mdl = fitcknn(X,Y,'NumNeighbors',4);
Рассмотрим потерю реституции, которая, по умолчанию, является частью неправильных классификаций из предсказаний Mdl. (Стоимость без ограничений, веса или априорные значения см. loss.).
rloss = resubLoss(Mdl)
rloss = 0.0400
Классификатор неправильно предсказывает 4% обучающих данных.
Создайте перекрестный проверенный классификатор из модели.
CVMdl = crossval(Mdl);
Исследуйте потери перекрестной валидации, которые являются средними потерями каждой модели перекрестной валидации при прогнозировании данных, которые не используются для обучения.
kloss = kfoldLoss(CVMdl)
kloss = 0.0333
Перекрестная проверенная точность классификации напоминает точность повторного замещения. Поэтому можно ожидать Mdl ошибочно классифицировать приблизительно 4% новых данных, принимая, что новые данные имеют примерно то же распределение, что и обучающие данные.
Этот пример показывает, как предсказать классификацию для k-ближайших соседей классификатора.
Создайте классификатор KNN для данных ириса Фишера, как в Construct KNN Classifier.
load fisheriris X = meas; Y = species; Mdl = fitcknn(X,Y,'NumNeighbors',4);
Предсказать классификацию среднего цветка.
flwr = mean(X); % an average flower
flwrClass = predict(Mdl,flwr)flwrClass = 1x1 cell array
{'versicolor'}
В этом примере показано, как изменить к-ближайший соседний классификатор.
Создайте классификатор KNN для данных ириса Фишера, как в Construct KNN Classifier.
load fisheriris X = meas; Y = species; Mdl = fitcknn(X,Y,'NumNeighbors',4);
Измените модель, чтобы использовать три ближайших соседа, а не ближайшего соседа по умолчанию.
Mdl.NumNeighbors = 3;
Сравните предсказания восстановления и потери перекрестной валидации с новым количеством соседей.
loss = resubLoss(Mdl)
loss = 0.0400
rng(10); % For reproducibility CVMdl = crossval(Mdl,'KFold',5); kloss = kfoldLoss(CVMdl)
kloss = 0.0333
В этом случае модель с тремя соседями имеет такие же перекрестно проверенные потери, как и модель с четырьмя соседями (см. «Изучение качества классификатора KNN»).
Измените модель, чтобы использовать косинусоидальное расстояние вместо значения по умолчанию, и исследуйте потерю. Чтобы использовать расстояние косинуса, необходимо воссоздать модель с помощью метода исчерпывающего поиска.
CMdl = fitcknn(X,Y,'NSMethod','exhaustive','Distance','cosine'); CMdl.NumNeighbors = 3; closs = resubLoss(CMdl)
closs = 0.0200
Теперь классификатор имеет более низкую ошибку реституции, чем раньше.
Проверьте качество перекрестно проверенной версии новой модели.
CVCMdl = crossval(CMdl); kcloss = kfoldLoss(CVCMdl)
kcloss = 0.0200
CVCMdl имеет лучшую потерю с перекрестной проверкой, чем CVMdl. Однако, в целом, улучшение ошибки реституции не обязательно приводит к модели с лучшими предсказаниями тестовой выборки.
ClassificationKNN | ExhaustiveSearcher | fitcknn | KDTreeSearcher
