Ошибка классификации
L = loss(tree,TBL,ResponseVarName)tree классифицирует данные в TBL, когда TBL.ResponseVarName содержит истинные классификации.
При расчете потерь loss нормализует вероятности классов в Y к вероятностям класса, используемым для обучения, хранящимся в Prior свойство tree.
L = loss(___,Name,Value)Name,Value аргументы в виде пар, с использованием любого из предыдущих синтаксисов. Для примера можно задать функцию потерь или веса наблюдений.
Вычислите повторно замещенную ошибку классификации для ionosphere набор данных.
load ionosphere
tree = fitctree(X,Y);
L = loss(tree,X,Y)L = 0.0114
Необрезанные деревья решений, как правило, перегружаются. Один из способов сбалансировать сложность модели и эффективности вне выборки - это обрезать дерево (или ограничить его рост), чтобы эффективность в выборке и вне выборки были удовлетворительными.
Загрузите набор данных радужки Фишера. Разделите данные на наборы для обучения (50%) и валидации (50%).
load fisheriris n = size(meas,1); rng(1) % For reproducibility idxTrn = false(n,1); idxTrn(randsample(n,round(0.5*n))) = true; % Training set logical indices idxVal = idxTrn == false; % Validation set logical indices
Создайте дерево классификации с помощью набора обучающих данных.
Mdl = fitctree(meas(idxTrn,:),species(idxTrn));
Просмотрите дерево классификации.
view(Mdl,'Mode','graph');

Классификационное дерево имеет четыре уровня обрезки. Уровень 0 является полным, несрезанным деревом (как показано). Уровень 3 является только корневым узлом (то есть без разделений).
Исследуйте ошибку классификации обучающей выборки для каждого поддерева (или уровня обрезки), исключая самый высокий уровень.
m = max(Mdl.PruneList) - 1;
trnLoss = resubLoss(Mdl,'SubTrees',0:m)trnLoss = 3×1
0.0267
0.0533
0.3067
Полное, несрезанное дерево ошибочно классифицирует около 2,7% обучающих наблюдений.
Дерево, обрезанное до уровня 1, неправильно классифицирует около 5,3% обучающих наблюдений.
Дерево, обрезанное до уровня 2 (то есть пень), неправильно классифицирует около 30,6% обучающих наблюдений.
Исследуйте ошибку классификации выборок валидации на каждом уровне, исключая самый высокий уровень.
valLoss = loss(Mdl,meas(idxVal,:),species(idxVal),'SubTrees',0:m)valLoss = 3×1
0.0369
0.0237
0.3067
Полное, несрезанное дерево ошибочно классифицирует около 3,7% наблюдений валидации.
Дерево, обрезанное до уровня 1, неправильно классифицирует около 2,4% наблюдений валидации.
Дерево, обрезанное до уровня 2 (то есть пень), неправильно классифицирует около 30,7% наблюдений валидации.
Чтобы сбалансировать сложность модели и несовпадающую эффективность, рассмотрите обрезку Mdl на уровень 1.
pruneMdl = prune(Mdl,'Level',1); view(pruneMdl,'Mode','graph')

Classification loss функции измеряют прогнозирующую неточность классификационных моделей. Когда вы сравниваете один и тот же тип потерь среди многих моделей, более низкая потеря указывает на лучшую прогнозирующую модель.
Рассмотрим следующий сценарий.
L - средневзвешенные классификационные потери.
n - размер выборки.
Для двоичной классификации:
yj - наблюдаемая метка класса. Программное обеспечение кодирует его как -1 или 1, указывая на отрицательный или положительный класс (или первый или второй класс в ClassNames свойство), соответственно.
f (Xj) является баллом классификации положительного класса для j наблюдений (строка) X данных предиктора.
mj = yj f (Xj) является классификационной оценкой для классификации j наблюдений в класс, относящийся к yj. Положительные значения mj указывают на правильную классификацию и не вносят большой вклад в средние потери. Отрицательные значения mj указывают на неправильную классификацию и вносят значительный вклад в среднюю потерю.
Для алгоритмов, которые поддерживают многоклассовую классификацию (то есть K ≥ 3):
yj* - вектор с K - 1 нулями, с 1 в положении, соответствующем истинному, наблюдаемому классу yj. Для примера, если истинный класс второго наблюдения является третьим классом и K = 4, то y 2* = [0 0 1 0]′. Порядок классов соответствует порядку в ClassNames свойство модели входа.
f (Xj) является вектором K длины счетов классов для j наблюдений X данных предиктора. Порядок счетов соответствует порядку классов в ClassNames свойство модели входа.
mj = yj*′ f (<reservedrangesplaceholder1>). Поэтому mj является скалярной классификационной оценкой, которую модель предсказывает для истинного наблюдаемого класса.
Вес для j наблюдения wj. Программа нормализует веса наблюдений так, чтобы они суммировались с соответствующей вероятностью предыдущего класса. Программное обеспечение также нормализует предыдущие вероятности, поэтому они равны 1. Поэтому,
С учетом этого сценария в следующей таблице описываются поддерживаемые функции потерь, которые можно задать при помощи 'LossFun' аргумент пары "имя-значение".
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | 'binodeviance' | |
| Неверно классифицированный коэффициент в десятичных числах | 'classiferror' | - метка класса, соответствующая классу с максимальным счетом. I {·} является функцией индикации. |
| Потери перекрестной энтропии | 'crossentropy' |
Взвешенные потери перекрестной энтропии где веса нормированы в сумме к n вместо 1. |
| Экспоненциальные потери | 'exponential' | |
| Потеря шарнира | 'hinge' | |
| Логит потеря | 'logit' | |
| Минимальные ожидаемые затраты на неправильную классификацию | 'mincost' |
Программа вычисляет взвешенные минимальные ожидаемые затраты классификации, используя эту процедуру для наблюдений j = 1,..., n.
Взвешенное среднее значение минимальных ожидаемых потерь от неправильной классификации Если вы используете матрицу затрат по умолчанию (значение элемента которой 0 для правильной классификации и 1 для неправильной классификации), то |
| Квадратичные потери | 'quadratic' |
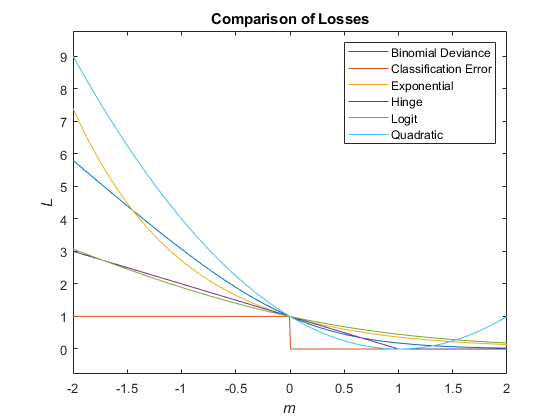
Этот рисунок сравнивает функции потерь (кроме 'crossentropy' и 'mincost') по счету m для одного наблюдения. Некоторые функции нормированы, чтобы пройти через точку (0,1).
Для деревьев score классификации узла листа является апостериорной вероятностью классификации в этом узле. Апостериорная вероятность классификации в узле - это количество обучающих последовательностей, которые ведут к этому узлу с классификацией, разделенной на количество обучающих последовательностей, которые ведут к этому узлу.
Например, рассмотрите классификацию предиктора X как true когда X < 0.15 или X > 0.95, и X в противном случае ложь.
Сгенерируйте 100 случайных точек и классифицируйте их:
rng(0,'twister') % for reproducibility X = rand(100,1); Y = (abs(X - .55) > .4); tree = fitctree(X,Y); view(tree,'Mode','Graph')

Обрезать дерево:
tree1 = prune(tree,'Level',1); view(tree1,'Mode','Graph')

Обрезанное дерево правильно классифицирует наблюдения, которые меньше 0,15, как true. Он также правильно классифицирует наблюдения от .15 до .94 как false. Однако он неправильно классифицирует наблюдения, которые больше 94, как false. Поэтому счет для наблюдений, которые больше 15, должны быть около .05/.85 = .06 для trueи примерно .8/.85 = .94 для false.
Вычислите счета предсказания для первых 10 строк X:
[~,score] = predict(tree1,X(1:10)); [score X(1:10,:)]
ans = 10×3
0.9059 0.0941 0.8147
0.9059 0.0941 0.9058
0 1.0000 0.1270
0.9059 0.0941 0.9134
0.9059 0.0941 0.6324
0 1.0000 0.0975
0.9059 0.0941 0.2785
0.9059 0.0941 0.5469
0.9059 0.0941 0.9575
0.9059 0.0941 0.9649
Действительно, каждое значение X (самый правый столбец), который меньше 0,15 имеет связанные счета (левый и центральный столбцы) 0 и 1, в то время как другие значения X имеют сопоставленные счета 0.91 и 0.09. The различия (счет 0.09 вместо ожидаемого .06) обусловлено статистическим колебанием: существуют 8 наблюдения в X в области значений (.95,1) вместо ожидаемого 5 наблюдения.
