В этом примере показано, как использовать приложение Distribution Fitter для интерактивной подгонки распределения вероятностей к данным.
Загрузите выборочные данные.
load carsmallОткройте инструмент Distribution Fitter.
distributionFitter
Чтобы импортировать векторную MPG в приложении Distribution Fitter нажмите кнопку Data. Откроется диалоговое окно Data.
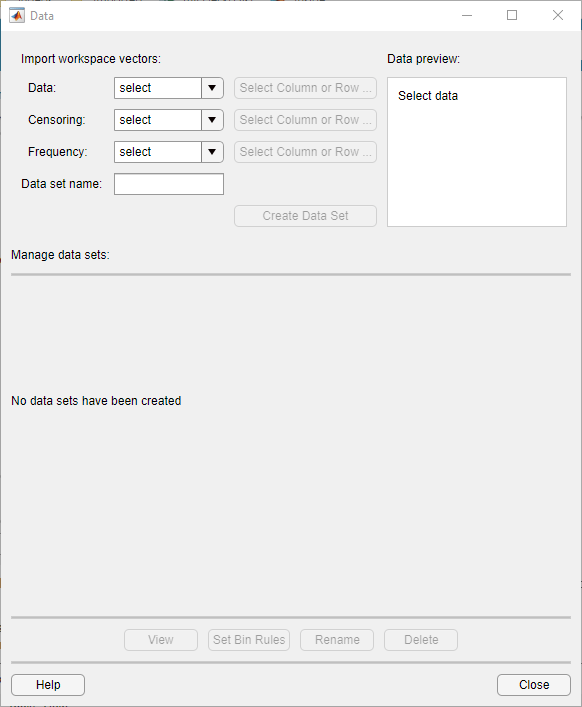
В Data поле отображаются все числовые массивы в MATLAB® рабочей области. В раскрывающемся списке выберите MPG. Гистограмма выбранных данных появится на панели Data preview.
В поле Data set name введите имя для набора данных, например MPG data, и нажмите Create Data Set. В главном окне приложения Distribution Fitter теперь отображается большая версия гистограммы на панели Data preview.
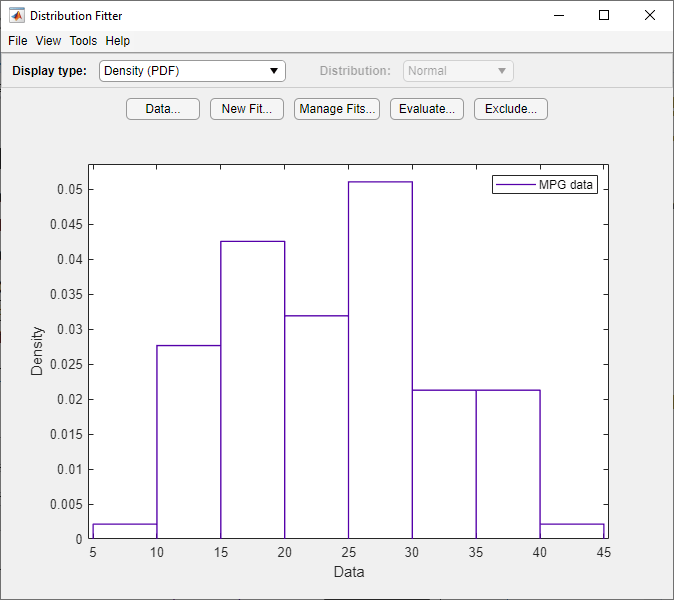
Чтобы подогнать распределение к данным, в главном окне приложения Distribution Fitter, нажмите New Fit.
Подбор нормального распределения к MPG data:
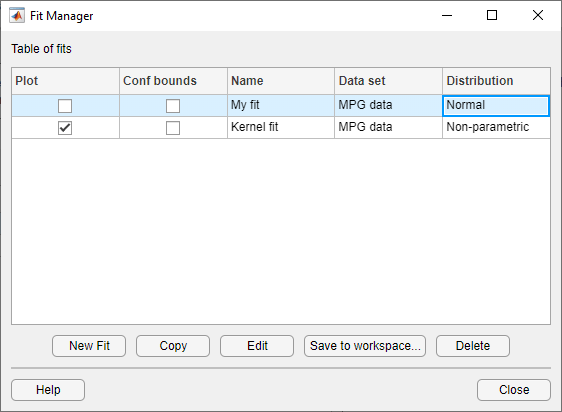
В Fit name поле введите имя подгонки, например My fit.
Из раскрывающегося списка в поле Data выберите MPG data.
Подтвердите, что Normal выбирается из выпадающего меню в поле Distribution.
Нажмите Apply.
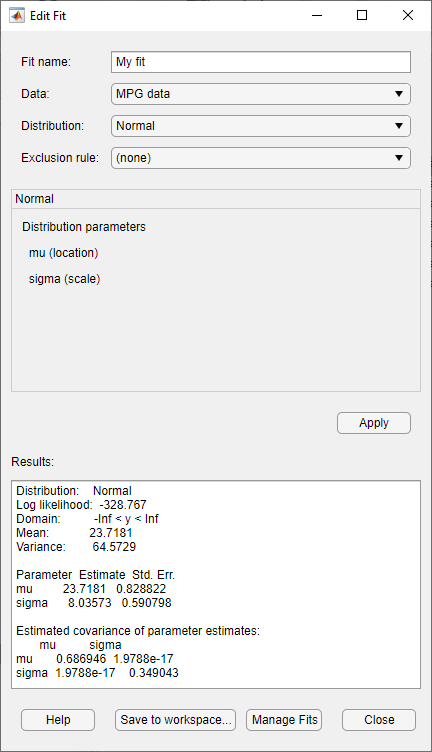
На Results панели отображаются среднее и стандартное отклонения нормального распределения, которое лучше всего подходит MPG data.
В главном окне приложения Distribution Fitter отображается график нормального распределения с этим средним и стандартным отклонением.
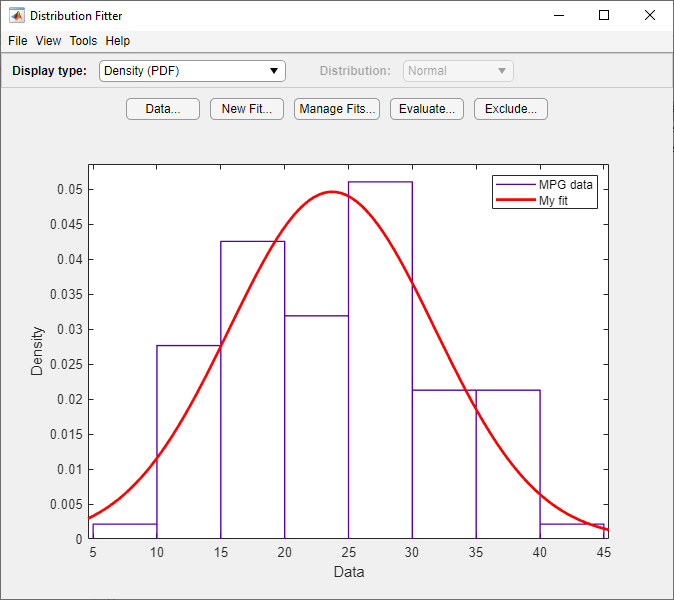
Исходя из графика, нормальное распределение, по-видимому, не обеспечивает хорошую подгонку для MPG данные. Чтобы получить лучшую оценку, выберите Probability plot из раскрывающегося списка Display type. Подтвердите, что в выпадающем списке Distribution задано значение Normal. В главном окне отображается следующий рисунок.
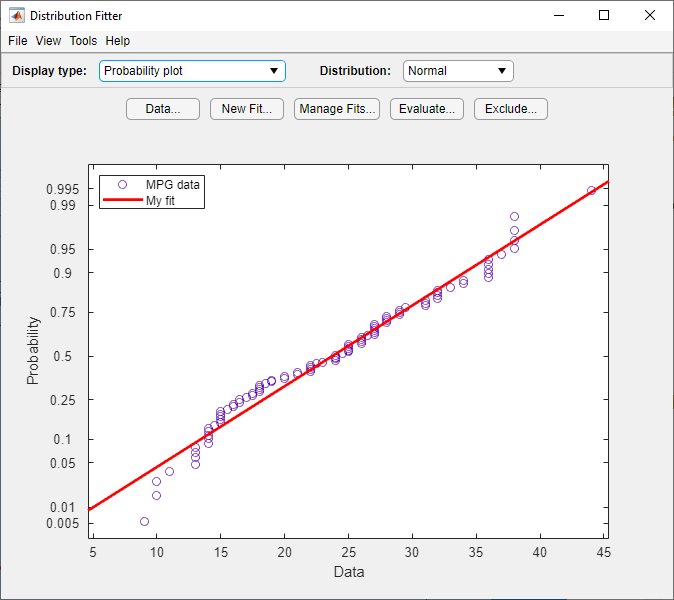
График нормальной вероятности показывает, что данные отклоняются от нормальных, особенно в хвостах.
The MPG pdf указывает, что данные имеют два пика. Попробуйте подгонять непараметрическое ядерное распределение, чтобы получить лучшую подгонку для этих данных.
Нажмите Manage Fits. В диалоговом окне нажмите кнопку New Fit.
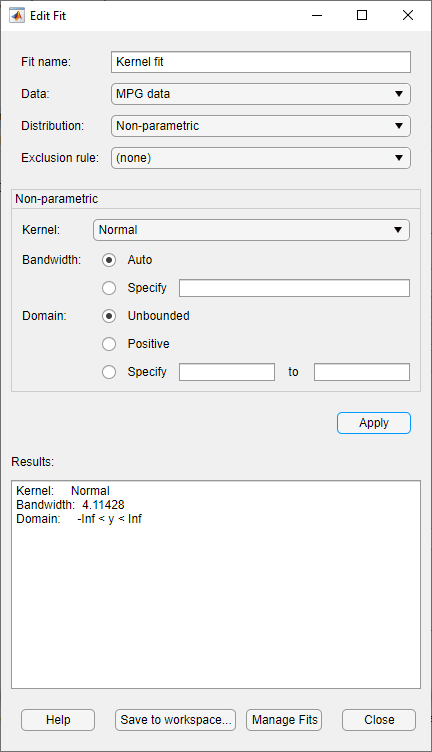
В Fit name поле введите имя подгонки, например Kernel fit.
Из раскрывающегося списка в поле Data выберите MPG data.
В раскрывающемся списке в поле Distribution выберите Non-parametric. Это включает несколько опции на панели Non-parametric, включая Kernel, Bandwidth и Domain. На данный момент примите значение по умолчанию, чтобы применить нормальную форму ядра и автоматически определить пропускную способность ядра (используя Auto). Для получения дополнительной информации о непараметрических ядерных распределениях см. Ядерное распределение.
Нажмите Apply.
На панели Results отображается тип ядра, полоса пропускания и область непараметрической подгонки распределения MPG data.
В главном окне отображаются графики исходных MPG data с наложенными нормальным распределением и непараметрическим ядерным распределением. Чтобы визуально сравнить эти две подгонки, выберите Density (PDF) из раскрывающегося списка Display type.
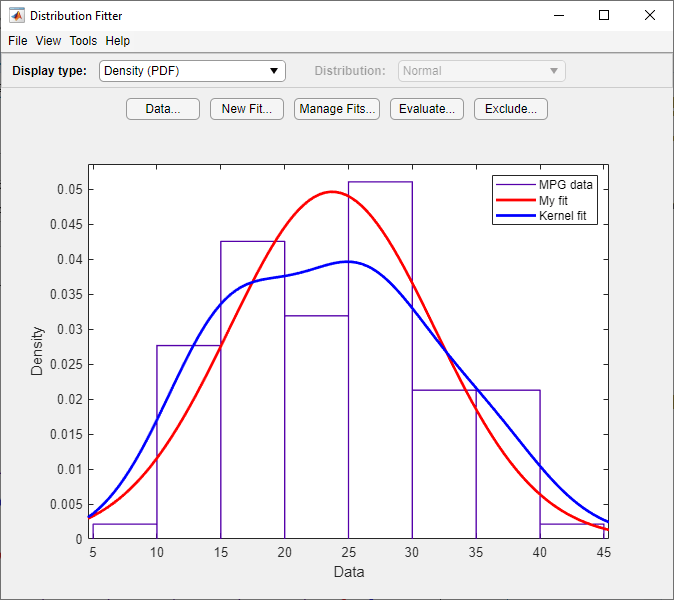
Включение только непараметрической линии подгонки ядра (Kernel fit) на графике нажмите «Управление подгонкой». На панели Table of fits найдите строку для нормальной подгонки распределения (My fit) и очистить поле в Plot столбце.