Приложение Distribution Fitter обеспечивает визуальный, интерактивный подход к подбору кривой одномерных распределений к данным.
Можно использовать приложение Distribution Fitter, чтобы в интерактивном режиме подгонять распределения вероятностей к данным, импортированным из MATLAB® рабочей области. Вы можете выбрать из 22 встроенных распределений вероятностей, или создать своё собственное пользовательское распределение. Приложение отображает установленное распределение по графикам эмпирических распределений, включая pdf, cdf, графики вероятностей и функции выжившего. Можно экспортировать данные подгонки, включая подобранные значения параметров, в рабочую область для последующего анализа.
Чтобы подогнать распределение вероятностей к выборочным данным:
На панели инструментов MATLAB щелкните вкладку Apps. В группе Math, Statistics and Optimization откройте приложение Distribution Fitter. Кроме того, в командной строке введите distributionFitter.
Импортируйте свои выборочные данные или создайте вектор данных непосредственно в приложении. Вы также можете управлять наборами данных и выбирать, какой из них подходит. См. «Создание и управление наборами данных».
Создайте новую подгонку для данных. См. Раздел «Создание новой подгонки»
Отображение результатов подгонки. Можно принять решение отобразить плотность (pdf), совокупную вероятность (cdf), квантиль (обратный cdf), график вероятностей (выберите одно из нескольких распределений), функцию выжившего и совокупную опасность. См. раздел «Отображение результатов».
Вы можете создать дополнительные подгонки и управлять несколькими подгонками из приложения См. «Управление подгонками».
Вычислите функции вероятности для подгонки. Можно принять решение вычислить плотность (pdf), совокупную вероятность (cdf), квантиль (обратный cdf), функцию выжившего и совокупную опасность. См. «Оценка подгонок».
Улучшите подгонку, исключив определенные данные. Можно задать границы для исключаемых данных или можно исключить данные графически с помощью графика значений в выборочных данных. См. «Исключить данные».
Сохраните сеанс приложения распределения тока Fitter, чтобы открыть его позже. См. Раздел «Сохранение и загрузка сеансов».
Чтобы открыть диалоговое окно Данные, нажмите кнопку Data в приложении Distribution Fitter.
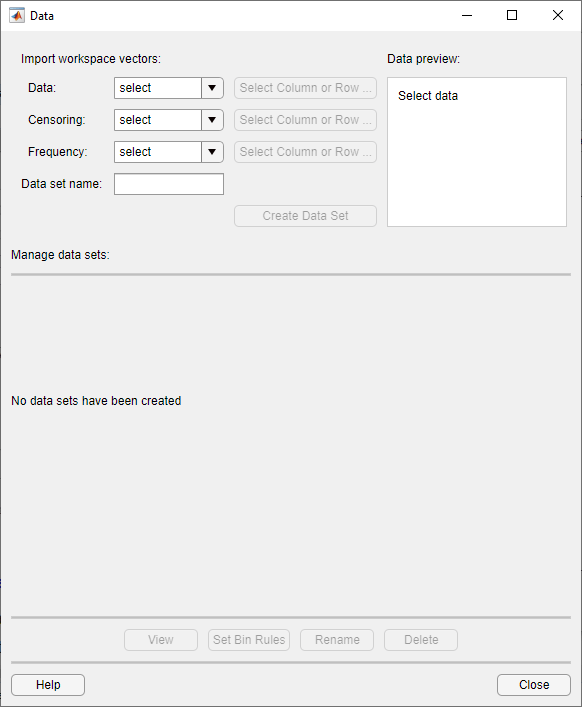
Создайте набор данных путем импорта вектора из рабочего пространства MATLAB с помощью панели Import workspace vectors.
Data - В поле Data раскрывающийся список содержит имена всех матриц и векторов, кроме матриц 1 на 1 (скаляров) в рабочем пространстве MATLAB. Выберите массив, содержащий данные, которые вы хотите подгонять. Фактические данные, которые вы импортируете, должны быть вектором. Если вы выбираете матрицу в поле Data, первый столбец матрицы импортируется по умолчанию. Чтобы выбрать другой столбец или строку матрицы, нажмите Select Column or Row. Матрица отображается в редакторе Переменных. Можно выбрать строку или столбец, подсвечивая ее.
Кроме того, в поле Data можно ввести любое допустимое выражение MATLAB.
При выборе вектора в поле Data на панели Data preview появляется гистограмма данных.
Censoring - Если некоторые точки в наборе данных подвергнуты цензуре, введите логический вектор того же размера, что и вектор данных, задавая цензурные значения данных. A 1 в векторе цензуры задает, что соответствующий ввод вектора данных подвергается цензуре. A 0 указывает, что запись не подвергается цензуре. Если вы вводите матрицу, можно выбрать столбец или строку нажав Select Column or Row. Если у вас нет цензурных данных, оставьте Censoring поле пустым.
Frequency - Введите вектор положительных целых чисел того же размера, что и вектор данных, чтобы задать частоту соответствующих записей вектора данных. Для примера значение 7 в 15-й записи вектора частоты задает, что существует 7 точек данных, соответствующих значению в 15-й записи вектора данных. Если все записи вектора данных имеют частоту 1, оставьте Frequency поле пустым.
Data set name - введите имя для набора данных, который вы импортируете из рабочей области, например My data.
После ввода информации в предыдущие поля щелкните Create Data Set, чтобы создать набор данных My data.
Просматривайте и управляйте наборами данных, которые вы создаете с помощью панели Manage data sets. При создании набора данных его имя появляется в списке Data sets. Следующий рисунок показывает панель Manage data sets после создания набора данных My data.
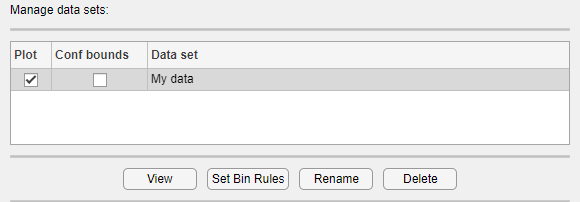
Для каждого набора данных в списке Data sets можно:
Установите флажок Plot, чтобы отобразить график данных в главном окне приложения Distribution Fitter. Когда вы создаете новый набор данных, Plot выбирается по умолчанию. Снятие флажка Plot удаляет данные с графика в главном окне. Можно задать тип графика, отображаемого в Display type поле в главном окне.
Если выбран Plot, можно также выбрать Bounds для отображения доверия интервала границ графика в главном окне. Эти границы являются точечными доверительными границами вокруг эмпирических оценок этих функций. Границы отображаются только при установке Display Type в главном окне одного из следующих значений:
Cumulative probability (CDF)
Survivor function
Cumulative hazard
Приложение Distribution Fitter не может отображать доверительные границы плотности (PDF), квантиль (inverse CDF), или вероятностных графиков. Снятие флажка Bounds удаляет доверительные границы с графика в главном окне.
При выборе набора данных из списка можно получить доступ к следующим кнопкам:
View - отображение данных в таблице в новом окне.
Set Bin Rules - определяет интервалы гистограммы, используемые на графике плотности (PDF).
Rename - Переименуйте набор данных.
Delete - Удалить набор данных.
Чтобы задать правила интервала для гистограммы набора данных, нажмите кнопку Set Bin Rules, чтобы открыть диалоговое окно Set Bin Width Rules.
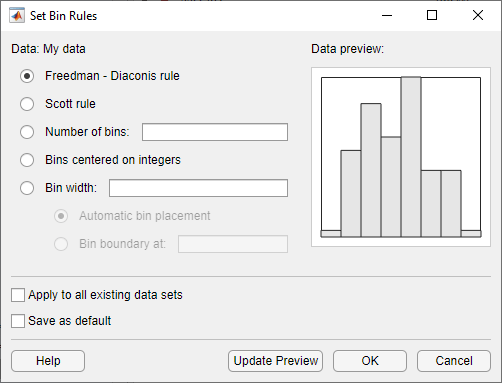
Можно выбрать из следующих правил:
Freedman-Diaconis rule - Алгоритм, который выбирает интервал ширины и местоположения автоматически, основываясь на размере выборки и распространении данных. Это правило, которое является значением по умолчанию, подходит для многих видов данных.
Scott rule - Алгоритм, предназначенный для данных, которые примерно нормальны. Алгоритм выбирает ширины и местоположения интервала автоматически.
Number of bins - Введите количество интервалов. Все интервалы имеют одинаковые ширины.
Bins centered on integers - задает интервалы с центром от целых чисел.
Bin width - введите ширину каждого интервала. Если вы выбираете эту опцию, можно также выбрать:
Automatic bin placement - поместите ребра интервалов в целое число, кратное Bin width.
Bin boundary at - Введите скаляр, чтобы задать контуры интервалов. Контур каждого интервала равен этому скаляру плюс целое число, кратное Bin width.
Вы также можете:
Apply to all existing data sets - Применить правило ко всем наборам данных. В противном случае правило применяется только к набору данных, выбранному в диалоговом окне Данные (Data).
Save as default - Применить текущее правило ко всем новым наборам данных, которые вы создаете. Можно задать правила ширины интервала по умолчанию, выбрав Set Default Bin Rules из меню Tools в главном окне.
Нажмите кнопку New Fit в верхней части главного окна, чтобы открыть диалоговое окно New Fit. Если вы создали набор данных My data, оно появляется в поле Data.
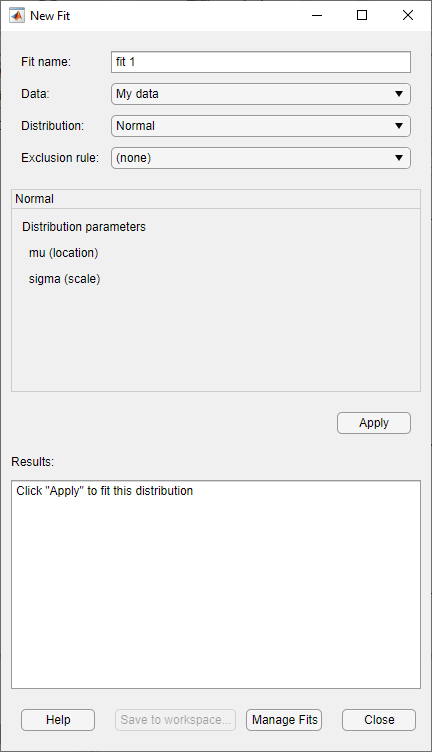
| Имя поля | Описание |
|---|---|
| Имя подгонки | Введите имя для подгонки. |
| Данные | Выберите из выпадающего списка набор данных, к которому требуется подгонять распределение. |
| Распределение | Выберите тип распределения для подгонки из выпадающего списка Distribution. В поле Distribution отображаются только распределения, применяемые к значениям выбранного набора данных. Например, когда данные включают значения, которые являются нулем или отрицательными, положительные распределения не отображаются. Можно задать или параметрическое, или непараметрическое распределение. При выборе параметрического распределения из выпадающего списка появляется описание его параметров. Distribution Fitter оценивает эти параметры в соответствии с распределением к набору данных. Если вы выбираете биномиальное распределение или обобщенное экстремальное распределение значений, необходимо задать фиксированное значение для одного из параметров. Панель содержит текстовое поле, в которое можно задать этот параметр. Когда вы выбираете |
| Правило исключения | Задайте правило, чтобы исключить некоторые данные. Создайте правило исключения, нажав Exclude в приложении Distribution Fitter. Для получения дополнительной информации смотрите Исключить данные. |
Щелкните Apply, чтобы соответствовать распределению. Для параметрической подгонки на панели Results отображаются значения предполагаемых параметров. Для непараметрической подгонки на панели Results отображается информация о подгонке.
При нажатии кнопки Apply приложение Distribution Fitter отображает график распределения и соответствующие данные.
Примечание
При нажатии кнопки Apply заголовок диалогового окна изменяется на «Редактировать подгонку». Теперь можно вносить изменения в только что созданную подгонку и снова кликнуть Apply, чтобы сохранить их. После закрытия диалогового окна Править подгонку (Edit Fit) его можно снова открыть из диалогового окна Диспетчер подгонки (Fit Manager) в любое время, чтобы отредактировать подгонку.
После применения подгонки можно сохранить информацию в рабочей области с помощью объектов распределения вероятностей, нажав Save to workspace.
Все распределения, доступные в приложении Distribution Fitter, поддерживаются в других разделах программного обеспечения Statistics and Machine Learning Toolbox™. Вы можете использовать fitdist функция для соответствия любому из распределений, поддерживаемых приложением. многие распределения также имеют специальные функции аппроксимации. Эти функции вычисляют большинство подгонок в приложении Distribution Fitter и указаны в следующем списке. Другие подгонки вычисляются с помощью функций, внутренних для приложения Distribution Fitter.
Не все перечисленные распределения доступны для всех наборов данных. Приложение Distribution Fitter определяет степень данных (неотрицательная, единичный интервал и т.д.) и отображает соответствующие распределения в выпадающем списке Distribution. Области значений данных распределения приведены в скобках в следующем списке.
Бета-версия (модули интервалов) распределения, подгонка с помощью функции betafit.
Биномиальное (неотрицательные целые значения) распределение, подгонка с помощью функции binopdf.
Распределение Бирнбаум-Сондерса (положительные значения).
Распределение Burr Type XII (положительные значения).
Экспоненциальное (неотрицательные значения) распределение, подгонка с помощью функции expfit.
Распределение экстремальных значений (всех значений), подгонка с помощью функции evfit.
Гамма (положительные значения) распределение, подгонка с помощью функции gamfit.
Обобщенное распределение экстремальных значений (всех значений), подгонка с помощью функции gevfit.
Обобщенное распределение Парето (все значения), подгонка с помощью функции gpfit.
Обратное распределение Гауссова (положительные значения).
Логистическое (все значения) распределение.
Логистическое (положительные значения) распределение.
Lognormal (положительные значения) распределение, подгонка с помощью функции lognfit.
Распределение Накагами (положительные значения).
Отрицательное биномиальное (неотрицательные целые значения) распределение, подгонка с помощью функции nbinpdf.
Непараметрическое (все значения) распределение, подгонка с помощью функции ksdensity.
Нормальное (все значения) распределение, подгонка с помощью функции normfit.
Распределение Пуассона (неотрицательные целочисленные значения), подгонка с помощью функции poisspdf.
Распределение Релея (положительных значений) с помощью функции raylfit.
Распределение Райса (положительные значения).
t распределение шкалы местоположения (все значения).
Распределение Вейбула (положительных значений) с помощью функции wblfit.
Когда вы выбираете Non-parametric в Distribution поле на панели Non-parametric появляется набор опций, как показано на следующем рисунке.
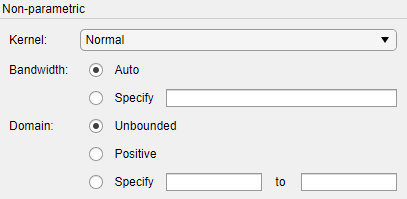
Опции для непараметрических распределений:
Kernel - Тип функции ядра для использования.
Normal
Box
Triangle
Epanechnikov
Bandwidth - Пропускная способность окна сглаживания ядра. Выберите Auto для значения по умолчанию, которое оптимально для оценки нормальных плотностей. После нажатия кнопки Apply это значение появится на панели Fit results. Выберите Specify и введите меньшее значение, чтобы показать функции, такие как несколько режимов или большее значение, чтобы сделать подгонку более сглаженной.
Domain - допустимые значения x для плотности.
Unbounded - Плотность простирается по всей действительной линии.
Positive - плотность ограничена положительными значениями.
Specify - введите нижнюю и верхнюю границы области плотности.
Когда вы выбираете Positive или Specify, непараметрическая подгонка имеет нулевую вероятность вне заданной области.
В окне приложения Distribution Fitter отображаются графики:
Наборы данных, для которых вы выбираете Plot в диалоговом окне Данные (Data).
Подгонка, для которой вы выбираете Plot в диалоговом окне Fit Manager.
Доверительные границы для:
Наборы данных, для которых вы выбираете Bounds в диалоговом окне Данные (Data).
Подгонка, для которой вы выбираете Bounds в диалоговом окне Fit Manager.
Доступны следующие поля.
Укажите тип графика для отображения с помощью поля Display Type в главном окне приложения. Каждый тип соответствует функции вероятности, для примера, функции плотности вероятностей. Можно выбрать один из следующих видов отображения:
Density (PDF) - отображение графика функции плотности вероятностей (PDF) для установленного распределения. В главном окне отображаются наборы данных с помощью гистограммы вероятностей, в которой высота каждого прямоугольника является частью точек данных, которые находятся в интервале, разделенном на ширину интервала. Это делает сумму площадей прямоугольников равной 1.
Cumulative probability (CDF) - отображение совокупного графика вероятностей данных. В главном окне отображаются наборы данных с помощью функции совокупного шага вероятности. Высота каждого шага является совокупной суммой высот прямоугольников в гистограмме вероятностей.
Quantile (inverse CDF) - отображение квантильного (обратного CDF) графика.
Probability plot - Отобразите график вероятности данных. Укажите тип распределения, используемого для построения графика вероятностей в поле Distribution. Это поле доступно только при выборе Probability plot. Для распределения доступны следующие варианты:
Exponential
Extreme value
Logistic
Log-Logistic
Lognormal
Normal
Rayleigh
Weibull
Можно также создать график вероятности относительно параметрической подгонки, который вы создаете на панели New Fit. Когда вы создаете эти модели, они добавляются в нижней части раскрывающегося списка Distribution.
Survivor function - Отобразите график функций выжившего из данных.
Cumulative hazard - отображение совокупного графика опасности данных.
Примечание
Если нанесенные на график данные включают 0 или отрицательные значения, некоторые распределения недоступны.
Можно отобразить доверительные границы для наборов данных и моделей, когда вы задаете Display Type Cumulative probability (CDF), Survivor function, Cumulative hazard, или, только для подгонки Quantile (inverse CDF).
Чтобы отобразить границы для набора данных, выберите Bounds рядом с набором данных на панели Data sets диалогового окна Данные.
Чтобы отобразить границы для подгонки, выберите Bounds рядом с подгонкой в диалоговом окне Fit Manager. Доверительные границы доступны не для всех типов подгонки.
Чтобы задать уровень доверия для границ, выберите Confidence Level из View меню в главном окне и выберите из опций.
Нажмите кнопку Manage Fits, чтобы открыть диалоговое окно Fit Manager.
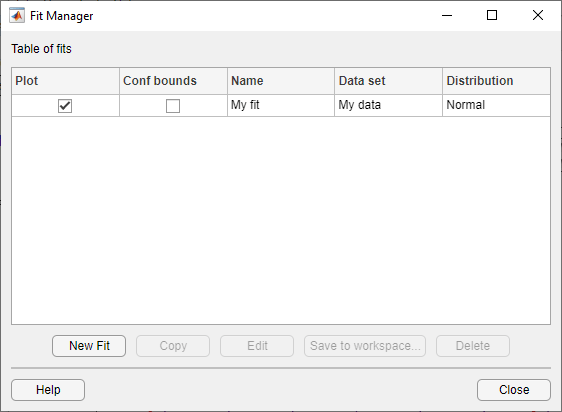
В Table of fits отображается список создаваемых подгонок со следующими опциями:
Plot - отображает график подгонки в главном окне приложения Distribution Fitter. Когда вы создаете новую подгонку, Plot выбирается по умолчанию. Снятие флажка Plot удаляет подгонку с графика в главном окне.
Bounds - Если вы выбираете Plot, можно также выбрать Bounds, чтобы отобразить доверительные границы на графике. Границы отображаются при установке Display Type в главном окне одного из следующих значений:
Cumulative probability (CDF)
Quantile (inverse CDF)
Survivor function
Cumulative hazard
Приложение Distribution Fitter не может отображать доверительные границы плотности (PDF) или вероятностных графиков. Ограничения не поддерживаются для непараметрических подгонок и некоторых параметрических подгонок.
Снятие флажка Bounds удаляет доверительные интервалы из графика в главном окне.
При выборе подгонки в Table of fits под таблицей включаются следующие кнопки:
New Fit - Открытие окна New Fit.
Copy - создайте копию выбранной подгонки.
Edit - Откройте диалоговое окно Править подгонку (Edit Fit), чтобы отредактировать подгонку.
Примечание
Редактировать можно только текущую выбранную подгонку в диалоговом окне «Редактирование подгонки». Чтобы отредактировать другую подгонку, выберите ее в Table of fits и нажмите кнопку Edit, чтобы открыть другое диалоговое окно Править подгонку (Edit Fit).
Save to workspace - Сохраните выбранную подгонку как объект распределения.
Delete - Удалить выбранную подгонку.
Используйте диалоговое окно Evaluate, чтобы оценить установленное распределение в любых выбранных точках данных. Чтобы открыть диалоговое окно, нажмите кнопку Evaluate.
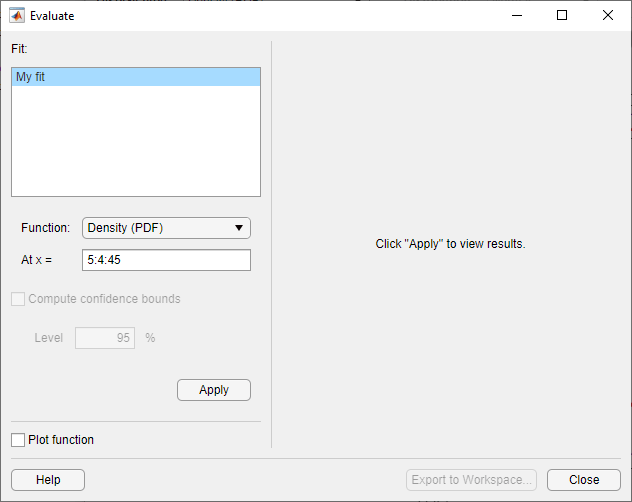
В диалоговом окне Evaluate выберите один из следующих элементов:
Fit панель - Отображать имена существующих подгонок. Выберите одну или несколько подгонки, которые необходимо оценить. Используя специфическую для вашей платформы функциональность, можно выбрать несколько подгонок.
Function - Выберите тип функции вероятности, которую вы хотите вычислить для подгонки. Доступными функциями являются:
Density (PDF) - Вычисляет функцию плотности вероятностей.
Cumulative probability (CDF) - Вычисляет совокупную функцию вероятности.
Quantile (inverse CDF) - Вычисляет квантильную (обратную CDF) функцию.
Survivor function - Вычисляет функцию выживания.
Cumulative hazard - Вычисляет совокупную функцию опасности.
Hazard rate - Вычисляет уровень опасности.
At x = - введите вектор точек или имя переменной рабочей области, содержащей вектор точек, в которых вы хотите вычислить функцию распределения. Если вы измените Function на Quantile (inverse CDF)имя поля изменяется на At p =, и вы вводите вектор значений вероятностей.
Compute confidence bounds - Установите этот флажок, чтобы вычислить доверительные границы для выбранных подгонок. Флажок включен только в том случае, если для Function задано одно из следующих значений:
Cumulative probability (CDF)
Quantile (inverse CDF)
Survivor function
Cumulative hazard
Приложение Distribution Fitter не может вычислить доверительные границы для непараметрических подгонок и для некоторых параметрических подгонок. В этих случаях возвращается NaN для границ.
Level - Установите уровень для доверительных границ.
Plot function - Установите этот флажок, чтобы отобразить график функции распределения, рассчитанный в точках, которые вы вводите в поле At x =, в новом окне.
Примечание
Настройки для Compute confidence bounds, Level и Plot function не влияют на графики, которые отображаются в главном окне приложения Distribution Fitter. Настройки применяются только к созданным вами графикам, нажав Plot function в окне Evaluate.
Чтобы применить эти параметры оценки к выбранной подгонке, нажмите кнопку Apply. Следующий рисунок показывает результаты оценки функции совокупной плотности для My fit подгонки в точках вектора 5:4:45.
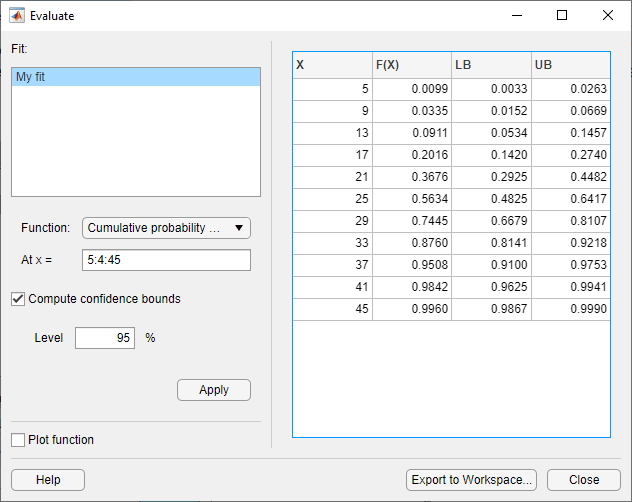
В столбцах таблицы справа от панели Fit отображаются следующие значения:
X - Значения вектора, которые вы вводите в At x = поле.
F (X) - соответствующие значения CDF в записях X.
LB - нижние границы для интервала доверия, если вы выбираете Compute confidence bounds.
UB - верхние границы для интервала доверия, если вы выбираете Compute confidence bounds.
Чтобы сохранить данные, отображенные в таблице, в матрицу в рабочем пространстве MATLAB, нажмите Export to Workspace.
Чтобы исключить значения из подгонки, откройте Exclude окно, нажав кнопку Exclude. В Exclude окне можно создать правила исключения заданных значений данных. Когда вы создаете новую подгонку в New Fit окне, можно использовать эти правила, чтобы исключить данные из подгонки.
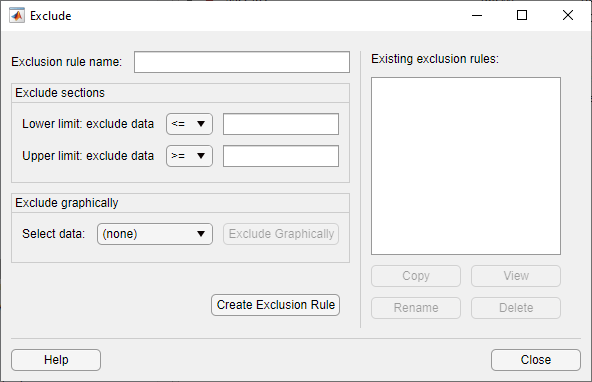
Чтобы создать правило исключения:
Exclusion Rule Name - введите имя правила исключения.
Exclude Sections - Задайте границы для исключенных данных:
В раскрывающемся списке Lower limit: exclude data выберите <= или < и введите скалярное значение в поле справа. В зависимости от того, какой оператор вы выберете, приложение исключает из подгонки любые значения данных, которые меньше или равны скалярному значению или меньше, чем скалярное значение, соответственно.
В раскрывающемся списке Upper limit: exclude data выберите >= или > и введите скалярное значение в поле справа. В зависимости от того, какой оператор вы выберете, приложение исключает из подгонки любые значения данных, которые больше или равны скалярному значению или больше скалярного значения, соответственно.
ИЛИ
Нажмите кнопку Exclude Graphically, чтобы определить правило исключения путем отображения графика значений в наборе данных и выбора границ для исключенных данных. Для примера, если вы создали набор данных My data как описано в разделе «Создание и управление наборами данных», выберите его из раскрывающегося списка рядом с Exclude graphically и нажмите кнопку Exclude graphically. Приложение отображает значения в My data в новом окне.
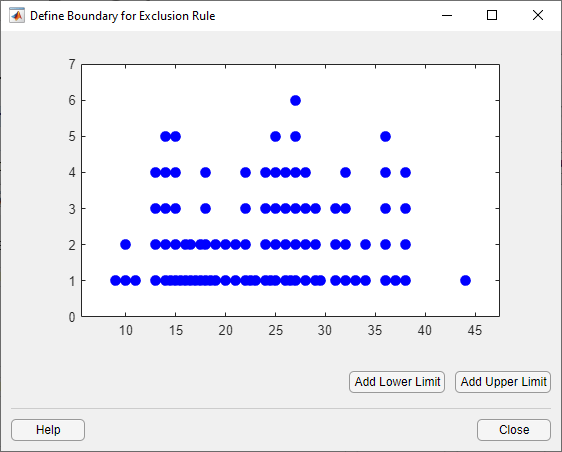
Чтобы задать нижний предел для контура исключенной области, нажмите Add Lower Limit. Приложение отображает вертикальную линию в левой части окна графика. Переместите линию в точку, где требуется нижний предел, как показано на следующем рисунке.
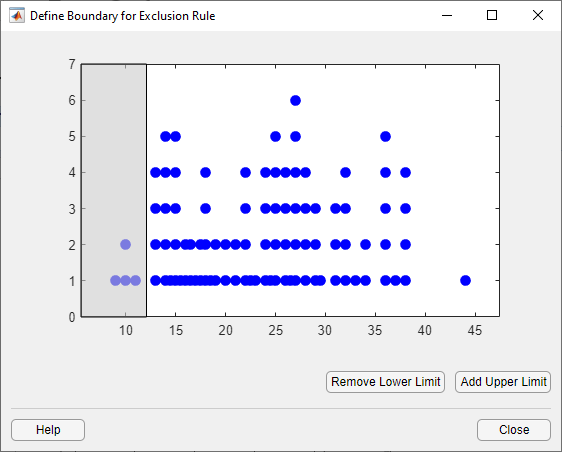
Переместите вертикальную линию, чтобы изменить значение, отображаемое в Lower limit: exclude data поле в Exclude окне.
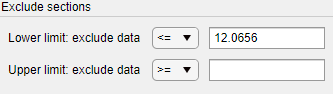
Отображаемое значение соответствует x-координате вертикальной линии.
Точно так же можно задать верхний предел для контура исключенной области, щелкнув Add Upper Limit, а затем перемещая вертикальную линию, которая появляется в правой части окна графика. После установки нижнего и верхнего пределов нажмите кнопку Close и вернитесь в окно Исключить.
Create Exclusion Rule - После установки нижнего и верхнего пределов для контура исключенных данных нажмите Create Exclusion Rule, чтобы создать новое правило. Имя нового правила появится на панели Existing exclusion rules.
Выбор правила исключения на панели Existing exclusion rules включает следующие кнопки:
Copy - создает копию правила, которую можно затем изменить. Чтобы сохранить измененное правило под другим именем, нажмите кнопку Create Exclusion Rule.
View - открывает новое окно, в котором можно увидеть точки данных, исключенные правилом. Следующий рисунок показывает типичный пример.
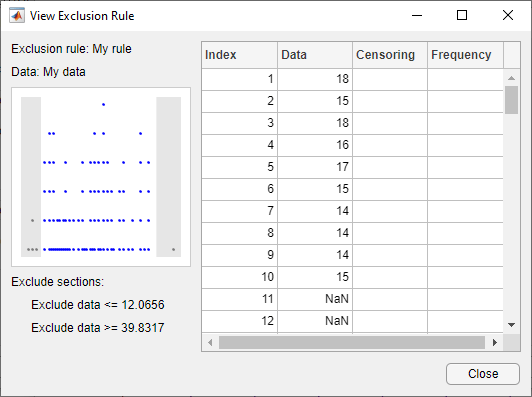
Затененные области на графике графически отображают, какие точки данных исключены. В таблице справа перечислены все точки данных. Затененные строки указывают на исключенные точки.
Rename - Переименовать правило.
Delete - Удалить правило.
После того, как вы определите правило исключения, вы можете использовать его, когда вы подгоняете распределение к вашим данным. Правило не исключает точки из отображения набора данных.
Сохраните работу в текущем сеансе, а затем загрузите ее в последующий сеанс, чтобы можно было продолжить работу там, где вы остановились.
Чтобы сохранить текущий сеанс, из меню File в главном окне выберите Save Session. Откроется диалоговое окно с приглашением ввести имя файла, например my_session.dfit. Щелкните Save, чтобы сохранить следующие элементы, созданные в текущем сеансе:
Наборы данных
Подгонка
Правила исключения
Настройки графика
Правила ширины интервала
Чтобы загрузить ранее сохраненный сеанс, из меню File в главном окне выберите Load Session. Введите имя ранее сохраненного сеанса. Щелкните Open, чтобы восстановить информацию из сохраненного сеанса в текущий сеанс.
Используйте Generate Code опция в File, чтобы создать файл, который:
Подходит для распределений в текущем сеансе к любому вектору данных в рабочем пространстве MATLAB.
Строит графики данных и подгонки.
После завершения текущего сеанса можно использовать файл для создания графиков в стандартном графическом окне MATLAB, не открывая приложение Distribution Fitter.
В качестве примера, если вы создали подгонку, описанную в разделе Создать новую подгонку (Create a New Fit), выполните следующие шаги:
В File меню выберите Generate Code.
В окне РЕДАКТОР MATLAB выберите File > Save as. Сохраните файл следующим normal_fit.m в папке по пути MATLAB.
Затем можно применить функцию normal_fit к любому вектору данных в рабочем пространстве MATLAB. Для примера выполните следующие команды:
new_data = normrnd(4.1, 12.5, 100, 1); newfit = normal_fit(new_data) legend('New Data', 'My fit')
сгенерировать newfit, установленное нормальное распределение данных. Команды также генерируют график данных и подгонки.
newfit =
NormalDistribution
Normal distribution
mu = 5.63857 [2.7555, 8.52163]
sigma = 14.53 [12.7574, 16.8791]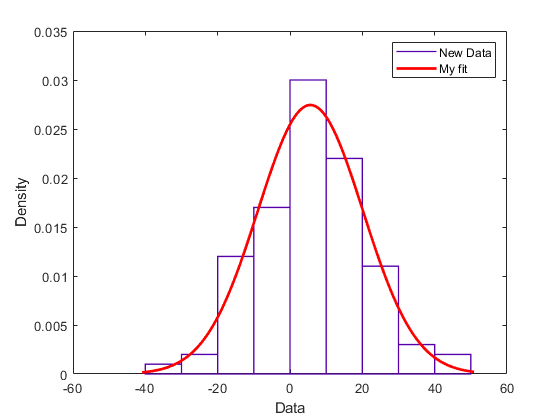
Примечание
По умолчанию файл помечает данные легенды, используя то же имя, что и набор данных в приложении Distribution Fitter. Изменить метку можно с помощью legend команда, как проиллюстрировано в предыдущем примере.
