В этом примере показано, как обучить логистическую регрессионую модель с помощью Classification Learner app. затем, в командной строке, инициализируйте и обучите инкрементальную модель для двоичной классификации, используя информацию, полученную из обучения в приложении.
Загрузите набор данных о деятельности человека. Случайным образом перетасуйте данные.
load humanactivity rng(1); % For reproducibility n = numel(actid); idx = randsample(n,n); X = feat(idx,:); actid = actid(idx);
Для получения дополнительной информации о наборе данных введите Description в командной строке.
Ответы могут быть одним из пяти классов: Сидя, Стоя, Ходьба, Бег, или Танцы. Дихотомизируйте ответ путем создания категориального массива, который идентифицирует, движется ли субъект (actid > 2).
moveidx = actid > 2; Y = repmat("NotMoving",n,1); Y(moveidx) = "Moving"; Y = categorical(Y);
Рассмотрите обучение логистической регрессионной модели приблизительно 1% данных и резервирование остальных данных для инкрементного обучения.
Случайным образом разбейте данные на подмножества 1% и 99% путем вызова cvpartition и определение доли выборок удержания (теста) 0.99. Создайте переменные для разделов 1% и 99%.
cvp = cvpartition(n,'HoldOut',0.99);
idxtt = cvp.training;
idxil = cvp.test;
Xtt = X(idxtt,:);
Xil = X(idxil,:);
Ytt = Y(idxtt);
Yil = Y(idxil);
Откройте Classification Learner путем ввода classificationLearner в командной строке.
classificationLearner
Кроме того, на вкладке Apps щелкните стрелу Show more, чтобы открыть галерею Apps. В разделе Machine Learning and Deep Learning щелкните значок приложения.
Выберите набор обучающих данных и переменные.
На вкладке Classification Learner, в разделе File, выберите New Session > From Workspace.
В диалоговом окне New Session from Workspace, в разделе Переменная набора данных, выберите Xtt переменной предиктора.
В разделе Response нажмите From workspace; Обратите внимание, что Ytt выбирается автоматически.
В разделе Validation нажмите Resubstitution Validation.
Нажмите Start Session.
Обучите логистическую регрессионую модель.
На вкладке Classification Learner, в разделе Model Type, щелкните стрелу Show more, чтобы открыть галерею моделей. В Logistic Regression Classifiers разделе нажмите Logistic Regression.
На вкладке Classification Learner, в разделе Training, нажмите Train.
Когда приложение закончит обучение модели, постройте матрицу неточностей. На вкладке Classification Learner, в разделе Plots, нажмите Confusion Matrix и выберите Validation Data.
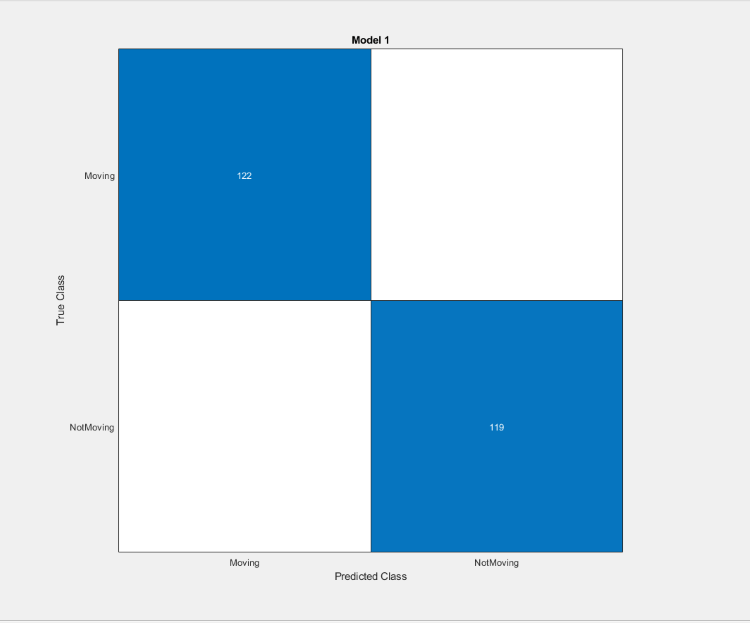
Матрица неточностей предполагает, что модель хорошо классифицирует наблюдения в выборке.
Экспорт обученной модели логистической регрессии.
На вкладке Classification Learner, в разделе Export, выберите Export Model > Export Model.
В диалоговом окне Export Model нажмите OK.
Приложение передает обученную модель, помимо других переменных, в массиве структур trainedModel в рабочую область. Закройте Classification Learner .
В командной строке извлеките обученную модель логистической регрессии и имена классов из trainedModel. Модель является GeneralizedLinearModel объект. Поскольку имена классов должны совпадать с типом данных переменной отклика, преобразуйте сохраненное значение в categorical.
Mdl = trainedModel.GeneralizedLinearModel; ClassNames = categorical(trainedModel.ClassNames);
Извлеките из модели точку пересечения и коэффициенты. Точка пересечения является первым коэффициентом.
Bias = Mdl.Coefficients.Estimate(1); Beta = Mdl.Coefficients.Estimate(2:end);
Вы не можете преобразовать GeneralizedLinearModel объект к инкрементной модели непосредственно. Однако можно инициализировать инкрементальную модель для двоичной классификации, передав информацию, полученную из приложения, такую как оценочные коэффициенты и имена классов.
Создайте инкрементальную модель для двоичной классификации непосредственно. Задайте ученика, точку пересечения, оценки коэффициентов и имена классов, полученные из Classification Learner. Поскольку хорошие начальные значения коэффициентов существуют, и все имена классов известны, задайте период разогрева метрики длины 0.
IncrementalMdl = incrementalClassificationLinear('Learner','logistic',... 'Beta',Beta,'Bias',Bias,'ClassNames',ClassNames,... 'MetricsWarmupPeriod',0)
IncrementalMdl =
incrementalClassificationLinear
IsWarm: 0
Metrics: [1×2 table]
ClassNames: [Moving NotMoving]
ScoreTransform: 'logit'
Beta: [60×1 double]
Bias: -471.7873
Learner: 'logistic'
Properties, MethodsIncrementalMdl является incrementalClassificationLinear моделируют объект для инкрементного обучения с использованием логистической регрессионой модели. Поскольку коэффициенты и все имена классов заданы, можно предсказать ответы путем передачи IncrementalMdl и данные для predict.
Выполните инкрементальное обучение для раздела данных 99% при помощи updateMetricsAndFit функция. Симулируйте поток данных путем обработки 50 наблюдений за раз. При каждой итерации:
Функции updateMetricsAndFit обновить совокупную и оконную ошибку классификации модели с учетом входящего фрагмента наблюдений. Перезаписайте предыдущую инкрементальную модель, чтобы обновить потери в Metrics свойство. Обратите внимание, что функция не подгоняет модель к фрагменту данных - фрагмент является «новыми» данными для модели.
Сохраните потери и оценочный коэффициент β 14.
% Preallocation nil = sum(idxil); numObsPerChunk = 50; nchunk = floor(nil/numObsPerChunk); ce = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); beta14 = [IncrementalMdl.Beta(14); zeros(nchunk,1)]; % Incremental learning for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; IncrementalMdl = updateMetricsAndFit(IncrementalMdl,Xil(idx,:),Yil(idx)); ce{j,:} = IncrementalMdl.Metrics{"ClassificationError",:}; beta14(j + 1) = IncrementalMdl.Beta(14); end
IncrementalMdl является incrementalClassificationLinear объект модели обучен на всех данных в потоке.
Постройте график трассировки метрик эффективности и β 14.
figure; subplot(2,1,1) h = plot(ce.Variables); xlim([0 nchunk]); ylabel('Classification Error') legend(h,ce.Properties.VariableNames) subplot(2,1,2) plot(beta14) ylabel('\beta_{14}') xlim([0 nchunk]); xlabel('Iteration')
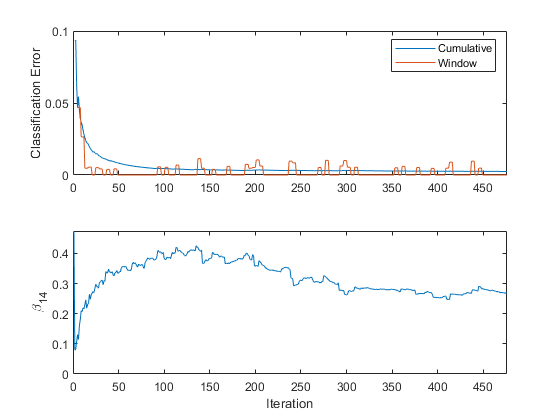
Совокупные потери постепенно изменяются с каждой итерацией (фрагмент 50 наблюдений), в то время как потери окна скачут. Потому что окно метрики 200 по умолчанию и updateMetricsAndFit измеряет эффективность каждые четыре итерации.
β 14 адаптируется к данным какupdateMetricsAndFit обрабатывает фрагменты наблюдений.
