Функция Statistics and Machine Learning Toolbox™ ecdf производит эмпирические совокупные функции опасности, выживания и совокупного распределения с помощью непараметрического метода Каплана-Мейера. Оценщик Каплана-Мейера для функции выжившего также называется оценщиком предела продукта.
Метод Каплана-Мейера использует данные о выживании, обобщенные в таблицах жизни. Таблицы жизни упорядочивают данные в соответствии с возрастающим временем отказа, но вы не должны вводить время отказа/выживания упорядоченным образом, чтобы использовать ecdf.
Жизненная таблица обычно состоит из:
Время отказа
Количество неудачных элементов за период времени
Количество элементов, подвергнутых цензуре за период времени
Количество элементов риска в начале периода времени/времени
Число подверженных риску - это общее число выживших в начале каждого периода. Число подверженных риску в начале первого периода - все индивидуумы в исследовании на всю жизнь. В начале каждого оставшегося периода число подверженных риску уменьшается на количество отказов плюс индивидуумов, подвергнутые цензуре в конце предыдущего периода.
Эта таблица жизни показывает фиктивные данные о выживании. В начале первого времени отказа существует семь элементы риска. В момент 4 три сбоя. Так что на начало времени 7, есть четыре элементов риска. В момент 7 отказывает только один, поэтому число рисков в начале времени 11 равно трем. Два сбоя в момент 11, поэтому в начале времени 12, число подверженных риску является одним. Оставшийся элемент завершается неуспешно в момент 12.
| Время отказа (t) | Число сбоя | Число подверженных риску |
|---|---|---|
| 4 | 3 | 7 |
| 7 | 1 | 4 |
| 11 | 2 | 3 |
| 12 | 1 | 1 |
Можно оценить опасность, совокупную опасность, выживание и совокупное распределение функций с помощью таблиц жизни, как описано далее.
Совокупный коэффициент опасности (частота отказов)
Уровень опасности в каждом периоде - это количество отказов в данном периоде, разделенное на число выживших индивидуумов в начале периода (число лиц, подвергающихся риску).
| Время отказа (t) | Уровень опасности (h (t)) | Кумулятивный коэффициент опасности |
|---|---|---|
| 0 | 0 | 0 |
| <reservedrangesplaceholder0> 1 | <reservedrangesplaceholder1> 1 / <reservedrangesplaceholder0> 1 | <reservedrangesplaceholder1> 1 / <reservedrangesplaceholder0> 1 |
| <reservedrangesplaceholder0> 2 | <reservedrangesplaceholder1> 2 / <reservedrangesplaceholder0> 2 | h (t 1) + <reservedrangesplaceholder1> 2 / <reservedrangesplaceholder0> 2 |
| ... | ... | ... |
| <reservedrangesplaceholder1> <reservedrangesplaceholder0> | <reservedrangesplaceholder3> <reservedrangesplaceholder2> / <reservedrangesplaceholder1> <reservedrangesplaceholder0> | h (t n – 1) + <reservedrangesplaceholder3> <reservedrangesplaceholder2> / <reservedrangesplaceholder1> <reservedrangesplaceholder0> |
Вероятность выживания
Для каждого периода вероятность выживания является продуктом дополнения коэффициентов опасности. Начальная вероятность выживания в начале первого временного периода равна 1. Если коэффициент опасности для каждого периода равен h (t i), то вероятность выживания такая, как показано.
| Время (t) | Вероятность выживания (S (t)) |
|---|---|
| 0 | 1 |
| <reservedrangesplaceholder0> 1 | 1* (1 – h (t 1)) |
| <reservedrangesplaceholder0> 2 | S (t 1) * (1 – h (t 2)) |
| ... | ... |
| <reservedrangesplaceholder1> <reservedrangesplaceholder0> | S (t n – 1) * (1 – h (t n)) |
Кумулятивная функция распределения
Поскольку совокупная функция распределения (cdf) и функция выжившего являются дополнениями друг к другу, можно найти cdf из таблиц жизни с помощью F (t) = 1 - S (t).
Можно вычислить совокупную степень опасности, выживаемость и совокупную функцию распределения для моделируемых данных в первой таблице на этой странице следующим образом.
| t | Число сбоя (d) | Число подверженных риску (r) | Коэффициент опасности | Вероятность выживания | Кумулятивная функция распределения |
|---|---|---|---|---|---|
| 4 | 3 | 7 | 3/7 | 1 – 3/7 = 4/7 = 0.5714 | 0.4286 |
| 7 | 1 | 4 | 1/4 | 4/7*(1 – 1/4) = 3/7 = .4286 | 0.5714 |
| 11 | 2 | 3 | 2/3 | 3/7*(1 – 2/3) = 1/7 = 0.1429 | 0.8571 |
| 12 | 1 | 1 | 1/1 | 1/7*(1 – 1) = 0 | 1 |
Эти скорости в этом примере основаны на дискретных временах отказа, и, следовательно, вычисления не обязательно следуют определению, основанному на производной, в «Что такое анализ выживания?»
Вот как можно ввести данные и вычислить эти измерения с помощью ecdf. Данные не обязательно должны быть в порядке возрастания. Предположим, что время отказа сохранено в массиве y.
y = [4 7 11 12];
freq = [3 1 2 1];
[f,x] = ecdf(y,'frequency',freq)f =
0
0.4286
0.5714
0.8571
1.0000
x =
4
4
7
11
12Когда вы подвергли цензуре данные, таблица жизни может выглядеть следующим образом:
| Время (t) | Число сбоя (d) | Цензурирование | Число подверженных риску (r) | Коэффициент опасности | Вероятность выживания | Кумулятивная функция распределения |
|---|---|---|---|---|---|---|
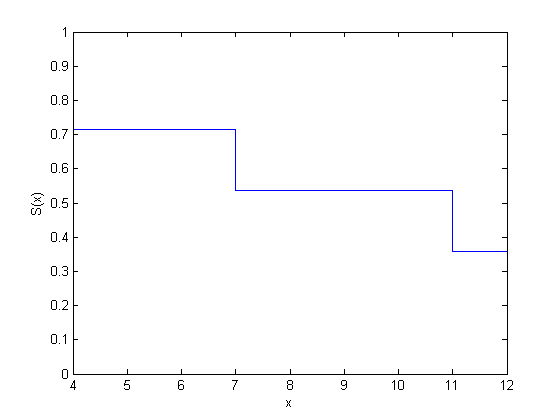
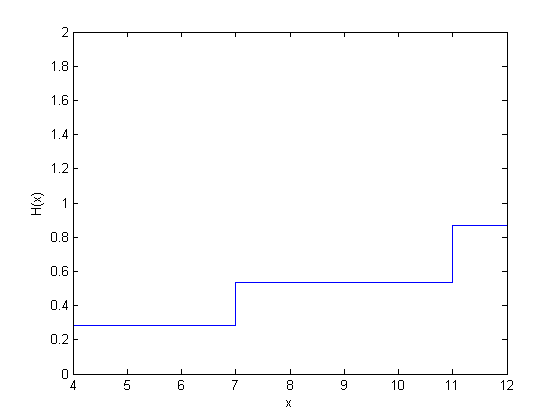
| 4 | 2 | 1 | 7 | 2/7 | 1 – 2/7 = 0.7143 | 0.2857 |
| 7 | 1 | 0 | 4 | 1/4 | 0.7143*(1 – 1/4) = 0.5357 | 0.4643 |
| 11 | 1 | 1 | 3 | 2/3 | 0.5357*(1 – 1/3) = 0.3571 | 0.6429 |
| 12 | 1 | 0 | 1 | 1/1 | 0.3571*(1 – 1) = 0 | 1.0000 |
В любой момент времени элементы, подвергнутые цензуре, также учитываются в общем числе подверженных риску, и формула коэффициента опасности основана на числе неудачных и общем числе подверженных риску. При обновлении числа лиц, подвергающихся риску в начале каждого периода, общее число лиц, которые потерпели неудачу и подверглись цензуре в предыдущий период, уменьшается по сравнению с числом лиц, подвергающихся риску в начале этого периода.
При использовании ecdfнеобходимо также ввести информацию цензуры с помощью массива двоичных переменных. Введите 1 для цензурных данных и 0 для точного времени отказа.
y = [4 4 4 7 11 11 12];
cens = [0 1 0 0 1 0 0];
[f,x] = ecdf(y,'censoring',cens)f =
0
0.2857
0.4643
0.6429
1.0000
x =
4
4
7
11
12ecdfпо умолчанию создает совокупные значения функции распределения. Вы должны задать функцию выжившего или функцию опасности с помощью необязательных аргументов пары "имя-значение". Можно также построить график результатов следующим образом.
figure() ecdf(y,'censoring',cens,'function','survivor');
figure() ecdf(y,'censoring',cens,'function','cumulative hazard');
[1] Кокс, Д. Р. и Д. Окс. Анализ данных о выживании. Лондон: Chapman & Hall, 1984.
[2] Lawless, J. F. Статистические модели и методы для пожизненных данных. Hoboken, NJ: Wiley-Interscience, 2002.
[3] Клейнбаум, Д. Г., и М. Клейн. Анализ выживания. Статистика по биологии и здоровью. 2-е издание. Спрингер, 2005.
