Подгонка модели латентного распределения Дирихле (LDA)
Модель латентного распределения Дирихле (LDA) является тематической моделью, которая обнаруживает базовые темы в наборе документов и выводит вероятности слов в темах. Если модель подгонялась с помощью модели bag-of-n-gams, то программа рассматривает n-gams как отдельные слова.
mdl = fitlda(___,Name,Value)
Чтобы воспроизвести результаты в этом примере, установите rng на 'default'.
rng('default')Загрузите данные примера. Файл sonnetsPreprocessed.txt содержит предварительно обработанные версии сонетов Шекспира. Файл содержит по одному сонету на линию со словами, разделенными пространством. Извлеките текст из sonnetsPreprocessed.txtразделите текст на документы в символах новой строки, а затем пометьте его токеном.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Создайте модель мешка слов с помощью bagOfWords.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154x3092 double]
Vocabulary: [1x3092 string]
NumWords: 3092
NumDocuments: 154
Подгонка модели LDA с четырьмя темами.
numTopics = 4; mdl = fitlda(bag,numTopics)
Initial topic assignments sampled in 0.077325 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.36 | | 1.215e+03 | 1.000 | 0 | | 1 | 0.01 | 1.0482e-02 | 1.128e+03 | 1.000 | 0 | | 2 | 0.01 | 1.7190e-03 | 1.115e+03 | 1.000 | 0 | | 3 | 0.01 | 4.3796e-04 | 1.118e+03 | 1.000 | 0 | | 4 | 0.01 | 9.4193e-04 | 1.111e+03 | 1.000 | 0 | | 5 | 0.01 | 3.7079e-04 | 1.108e+03 | 1.000 | 0 | | 6 | 0.01 | 9.5777e-05 | 1.107e+03 | 1.000 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 4
WordConcentration: 1
TopicConcentration: 1
CorpusTopicProbabilities: [0.2500 0.2500 0.2500 0.2500]
DocumentTopicProbabilities: [154x4 double]
TopicWordProbabilities: [3092x4 double]
Vocabulary: [1x3092 string]
TopicOrder: 'initial-fit-probability'
FitInfo: [1x1 struct]
Визуализируйте темы с помощью облаков слов.
figure for topicIdx = 1:4 subplot(2,2,topicIdx) wordcloud(mdl,topicIdx); title("Topic: " + topicIdx) end

Подбор модели LDA к набору документов, представленных матрицей count слов.
Чтобы воспроизвести результаты этого примера, установите rng на 'default'.
rng('default')Загрузите данные примера. sonnetsCounts.mat содержит матрицу отсчётов слов и соответствующий словарь предварительно обработанных версий сонетов Шекспира. Значение counts(i,j) соответствует количеству раз, сколько jВторое слово словаря появляется в iI документ.
load sonnetsCounts.mat
size(counts)ans = 1×2
154 3092
Подгонка модели LDA с 7 темами. Чтобы подавить подробный выход, установите 'Verbose' в 0.
numTopics = 7;
mdl = fitlda(counts,numTopics,'Verbose',0);Визуализация нескольких тематических смесей с помощью сложенных столбчатых диаграмм. Визуализация тематических смесей первых трех входных документов.
topicMixtures = transform(mdl,counts(1:3,:)); figure barh(topicMixtures,'stacked') xlim([0 1]) title("Topic Mixtures") xlabel("Topic Probability") ylabel("Document") legend("Topic "+ string(1:numTopics),'Location','northeastoutside')

Чтобы воспроизвести результаты в этом примере, установите rng на 'default'.
rng('default')Загрузите данные примера. Файл sonnetsPreprocessed.txt содержит предварительно обработанные версии сонетов Шекспира. Файл содержит по одному сонету на линию со словами, разделенными пространством. Извлеките текст из sonnetsPreprocessed.txtразделите текст на документы в символах новой строки, а затем пометьте его токеном.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Создайте модель мешка слов с помощью bagOfWords.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154x3092 double]
Vocabulary: [1x3092 string]
NumWords: 3092
NumDocuments: 154
Подгонка модели LDA с 20 темами.
numTopics = 20; mdl = fitlda(bag,numTopics)
Initial topic assignments sampled in 0.029643 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.39 | | 1.159e+03 | 5.000 | 0 | | 1 | 0.13 | 5.4884e-02 | 8.028e+02 | 5.000 | 0 | | 2 | 0.11 | 4.7400e-03 | 7.778e+02 | 5.000 | 0 | | 3 | 0.11 | 3.4597e-03 | 7.602e+02 | 5.000 | 0 | | 4 | 0.14 | 3.4662e-03 | 7.430e+02 | 5.000 | 0 | | 5 | 0.11 | 2.9259e-03 | 7.288e+02 | 5.000 | 0 | | 6 | 0.14 | 6.4180e-05 | 7.291e+02 | 5.000 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [1x20 double]
DocumentTopicProbabilities: [154x20 double]
TopicWordProbabilities: [3092x20 double]
Vocabulary: [1x3092 string]
TopicOrder: 'initial-fit-probability'
FitInfo: [1x1 struct]
Спрогнозируйте верхние темы для массива новых документов.
newDocuments = tokenizedDocument([
"what's in a name? a rose by any other name would smell as sweet."
"if music be the food of love, play on."]);
topicIdx = predict(mdl,newDocuments)topicIdx = 2×1
19
8
Визуализируйте предсказанные темы с помощью облаков слов.
figure subplot(1,2,1) wordcloud(mdl,topicIdx(1)); title("Topic " + topicIdx(1)) subplot(1,2,2) wordcloud(mdl,topicIdx(2)); title("Topic " + topicIdx(2))

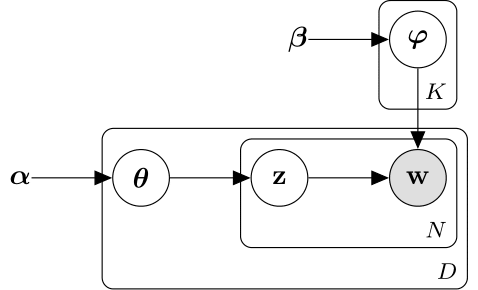
Модель латентного распределения Дирихле (LDA) является моделью темы документа, которая обнаруживает базовые темы в наборе документов и выводит вероятности слов в темах. LDA моделирует набор D документов как тематические смеси , над K темами, характеризующимися векторами вероятностей слова . Модель принимает, что тематические смеси , и темы следуйте распределению Дирихле с параметрами концентрации и соответственно.
Тематические смеси являются векторами вероятностей длины K, где K - количество тем. Вход - вероятность появления i темы в d-м документе. Тематические смеси соответствуют строкам DocumentTopicProbabilities свойство ldaModel объект.
Темы являются векторами вероятностей длины V, где V - количество слов в словаре. Вход соответствует вероятности появления v-го слова словаря в i-й теме. Темы соответствуют столбцам TopicWordProbabilities свойство ldaModel объект.
Учитывая темы и Дирихлет априорный что касается тематических смесей, то LDA предполагает следующий генеративный процесс для документа:
Образец тематической смеси . Случайная переменная является вектором вероятностей длины K, где K - количество тем.
Для каждого слова в документе:
Пример индекса темы . z случайной переменной является целым числом от 1 до K, где K - количество тем.
Пример слова . Случайная переменная w является целым числом от 1 до V, где V - количество слов в словаре, и представляет соответствующее слово в словаре.
В рамках этого генеративного процесса совместное распределение документа со словами , с тематической смесью , и с индексами тем дается
где N - количество слов в документе. Суммирование распределения соединений по z и последующая интеграция приводит к маргинальному распределению документа w:
Следующая схема иллюстрирует модель LDA как вероятностную графическую модель. Затененные узлы являются наблюдаемыми переменными, незаштрихованные узлы являются скрытыми переменными, узлы без контуров являются параметрами модели. Стрелы подсвечивают зависимости между случайными переменными, а пластины указывают на повторные узлы.
[1] Фолдс, Джеймс, Леви Бойлз, Кристофер Дюбуа, Падраик Смит и Max Веллинг. Стохастический свернутый вариационный байесовский вывод для латентного распределения Дирихле. В Трудах 19-й международной конференции ACM SIGKDD по открытию знаний и майнингу данных, стр. 446-454. ACM, 2013.
[2] Хоффман, Мэтью Д., Дэвид М. Блей, Чонг Ван и Джон Пейсли. «Стохастический вариационный вывод». The Journal of Машинное Обучение Research 14, № 1 (2013): 1303-1347.
[3] Гриффитс, Томас Л. и Марк Стейверс. «Поиск научных тем». Труды Национальной академии наук 101, нет. суппл 1 (2004): 5228-5235.
[4] Asuncion, Arthur, Max Welling, Padhraic Smyth, and Yee Whye Teh. «О сглаживании и выводе для тематических моделей». В трудах двадцать пятой Конференции по неопределенности в искусственном интеллекте, стр. 27-34. AUAI Press, 2009.
[5] Teh, Yee W., David Newman, and Max Welling. «Свернутый вариационный алгоритм вывода Байеса для латентного распределения Дирихле». В «Усовершенствования в системах нейронной обработки информации», стр. 1353-1360. 2007.
bagOfNgrams | bagOfWords | fitlsa | ldaModel | logp | lsaModel | predict | resume | topkwords | transform | wordcloud
