Воспринятая громкость акустического сигнала
loudness = acousticLoudness(audioIn,fs,calibrationFactor)
loudness = acousticLoudness(___,Name,Value)Name,Value парные аргументы.
loudness = acousticLoudness(audioIn,fs,'Method','ISO 532-2') возвращает громкость согласно ISO 532-2 (Мур-Глэсберг).[ также возвращает определенную громкость.loudness,specificLoudness] = acousticLoudness(___)
[ также возвращает громкость процентили.loudness,specificLoudness,perc] = acousticLoudness(___,'TimeVarying',true)
[ задает процентили не по умолчанию, чтобы возвратиться.loudness,specificLoudness,perc] = acousticLoudness(___,'TimeVarying',true,'Percentiles',p)
acousticLoudness(___) без выходных аргументов строит определенную громкость и отображает громкость дословно. Если TimeVarying true, и громкость и определенная громкость построены с последним в 3-D.
Измерьте ISO 532-1 стационарная громкость свободного поля. Примите, что уровень записи калибруется таким образом, что тон на 1 кГц указывает как 100 дБ на метре SPL.
[audioIn,fs] = audioread('WashingMachine-16-44p1-stereo-10secs.wav');
loudness = acousticLoudness(audioIn,fs)loudness = 1×2
28.2688 27.7643
Создайте два стационарных сигнала с эквивалентной степенью: розовый шумовой сигнал и сигнал белого шума.
fs = 48e3; dur = 5; pnoise = 2*pinknoise(dur*fs); wnoise = rand(dur*fs,1) - 0.5; wnoise = wnoise*sqrt(var(pnoise)/var(wnoise));
Вызовите acousticLoudness использование ISO 532-1 по умолчанию (Zwicker) метод и никакие выходные аргументы, чтобы построить громкость розового шума. Вызовите acousticLoudness снова, на этот раз с выходными аргументами, чтобы получить определенную громкость.
figure acousticLoudness(pnoise,fs)

[~,pSpecificLoudness] = acousticLoudness(pnoise,fs);
Постройте громкость для белого шума, сигнализируют и затем получают определенные значения громкости.
figure acousticLoudness(wnoise,fs)

[~,wSpecificLoudness] = acousticLoudness(wnoise,fs);
Вызовите acousticSharpness функция, чтобы сравнить резкость розового шумового и белого шума.
pSharpness = acousticSharpness(pSpecificLoudness);
wSharpness = acousticSharpness(wSpecificLoudness);
fprintf('Sharpness of pink noise = %0.2f acum\n',pSharpness)Sharpness of pink noise = 2.00 acum
fprintf('Sharpness of white noise = %0.2f acum\n',wSharpness)Sharpness of white noise = 2.62 acum
Читайте в звуковом файле.
[audioIn,fs] = audioread('JetAirplane-16-11p025-mono-16secs.wav');Постройте изменяющуюся во времени акустическую громкость в соответствии с ISO 532-1 и получите процентили. Слушайте звуковой сигнал.
acousticLoudness(audioIn,fs,'SoundField','diffuse','TimeVarying',true)

sound(audioIn,fs)
Вызовите acousticLoudness снова с теми же входными параметрами и получают процентили. Распечатайте Nmax и процентили N5. Процентиль Nmax является максимальной громкостью, о которой сообщают. Процентиль N5 является громкостью, ниже которой 95% громкости, о которой сообщают.
[~,~,perc] = acousticLoudness(audioIn,fs,'SoundField','diffuse','TimeVarying',true); fprintf('Max loudness = %0.2f sones\n',perc(1))
Max loudness = 89.48 sones
fprintf('N5 loudness = %0.2f sones\n',perc(2))N5 loudness = 81.77 sones
Читайте в звуковом файле.
[audioIn,fs] = audioread('Turbine-16-44p1-mono-22secs.wav');Вызовите acousticLoudness без выходных аргументов, чтобы построить определенную громкость. Примите калибровочный фактор 0,15 и ссылочное давление 21 micropascals. Чтобы определить калибровочный фактор, характерный для вашей аудиосистемы, используйте calibrateMicrophone функция.
calibrationFactor = 0.15;
refPressure = 21e-6;
acousticLoudness(audioIn,fs,calibrationFactor,'PressureReference',refPressure)
acousticLoudness позволяет вам задать промежуточное представление, уровни звукового давления, вместо входа временного интервала. Это позволяет вам снова использовать промежуточные вычисления SPL. Другое преимущество состоит в том, что, если ваш физический метр SPL не сообщает о громкости в соответствии с ISO 532-1 или ISO 531-2, можно использовать сообщаемый 1/3-octave SPLs, чтобы вычислить стандартно-совместимую громкость.
Чтобы вычислить уровни звукового давления от звукового сигнала, сначала создайте splMeter объект. Вызовите splMeter объект с аудиовходом.
spl = splMeter("SampleRate",fs,"Bandwidth","1/3 octave", ... "CalibrationFactor",calibrationFactor,"PressureReference",refPressure, ... "FrequencyWeighting","Z-weighting","OctaveFilterOrder",6); splMeasurement = spl(audioIn);
Вычислите средний уровень SPL, пропустив первые 0,2 секунды. Только сохраните полосы от 25 Гц до 12,5 кГц (первые 28 полос).
SPLIn = mean(splMeasurement(ceil(0.2*fs):end,1:28));
Используя вход SPL, вызовите acousticLoudness без выходных аргументов, чтобы построить определенную громкость.
acousticLoudness(SPLIn)

Настройте эксперимент, как обозначено схемой.

Создайте audioDeviceReader возразите, чтобы читать из микрофона и audioDeviceWriter возразите, чтобы записать в ваш динамик.
fs = 48e3; deviceReader = audioDeviceReader(fs); deviceWriter = audioDeviceWriter(fs);
Создайте audioOscillator объект сгенерировать синусоиду на 1 кГц.
osc = audioOscillator("sine",1e3,"SampleRate",fs);
Создайте dsp.AsyncBuffer возразите, чтобы буферизовать данные, полученные от микрофона.
dur = 5; buff = dsp.AsyncBuffer(dur*fs);
В течение пяти секунд проигрывайте синусоиду через свой динамик и запись с помощью микрофона. В то время как аудиопотоки, отметьте громкость, как сообщается вашим метром SPL. Однажды завершенный, считайте содержимое буферного объекта.
numFrames = dur*(fs/osc.SamplesPerFrame); for ii = 1:numFrames audioOut = osc(); deviceWriter(audioOut); audioIn = deviceReader(); write(buff,audioIn); end SPLreading = 60.4; micRecording = read(buff);
Чтобы вычислить калибровочный фактор для микрофона, используйте calibrateMicrophone функция.
calibrationFactor = calibrateMicrophone(micRecording,deviceReader.SampleRate,SPLreading);
Вызовите acousticLoudness с записью микрофона, частотой дискретизации и калибровочным фактором. О громкости сообщают от acousticLoudness истинное акустическое измерение громкости, как задано 532-1.
loudness = acousticLoudness(micRecording,deviceReader.SampleRate,calibrationFactor)
loudness = 14.7902
Можно теперь использовать калибровочный фактор, вы решили измерять громкость любого звука, который получен через ту же цепь записи микрофона.
Читайте в звуковом сигнале.
[audioIn,fs] = audioread('TrainWhistle-16-44p1-mono-9secs.wav');ISO 532-1
Определите изменяющуюся во времени определенную громкость согласно методу по умолчанию (ISO 532-1).
[~,specificLoudness] = acousticLoudness(audioIn,fs,'TimeVarying',true);ISO 532-1 сообщает об определенной громкости по Коре, где интервалами Коры является 0.1:0.1:24. Преобразуйте интервалы Коры в Гц и затем постройте определенную громкость по Гц через время.
barkBins = 0.1:0.1:24; hzBins = bark2hz(barkBins); t = 0:2e-3:2e-3*(size(specificLoudness,1)-1); surf(t,hzBins,sum(specificLoudness,3).','EdgeColor','interp') set(gca,'YScale','log') view([0 90]) axis tight xlabel('Time (s)') ylabel('Frequency (Hz)') colorbar title('Specific Loudness (sones/Bark)')

ISO 532-2
Определите стационарную определенную громкость согласно методу Мура-Глэсберга (ISO 532-2).
[~,specificLoudness] = acousticLoudness(audioIn,fs,'Method','ISO 532-2');
ISO 532-2 сообщает об определенной громкости по шкале ERB, где интервалами ERB является 1.8:0.1:38.9. Модуль шкалы ERB иногда упоминается как Бегунок. Преобразуйте интервалы ERB в Гц и затем постройте определенную громкость.
erbBins = 1.8:0.1:38.9; hzBins = erb2hz(erbBins); semilogx(hzBins,specificLoudness) xlabel('Frequency (Hz)') ylabel('Loudness (sones)') title('Specific Loudness') grid on

Читайте в звуковом файле.
[x,fs] = audioread('WashingMachine-16-44p1-stereo-10secs.wav');ISO 532-2 позволяет вам задать пользовательский ответ наушника при вычислении громкости. Создайте 30 2 матрица, где первый столбец является частотой, и второй столбец является отклонением наушника от плавного ответа.
tdh = [ 0, 80, 100, 200, 500, 574, 660, 758, 871, 1000, 1149, 1320, 1516, 1741, 2000, ... 2297, 2639, 3031, 3482, 4000, 4500, 5000, 5743, 6598, 7579, 8706, 10000, 12000, 16000, 20000; ... -50, -15.3, -13.8, -8.1, -0.5, 0.4, 0.8, 0.9, 0.5, 0.1, -0.8, -1.5, -2.3, -3.2, -3.9, ... -4.2, -4.3, -4.3, -3.9, -3.2, -2.3, -1.1, -0.3, -2, -5.4, -9, -12.1, -15.2, -30, -50 ].';
Вычислите громкость с помощью ISO 532-2. Задайте SoundField как earphones и ответ наушника как матрица вы только создали.
acousticLoudness(x,fs,'Method','ISO 532-2','SoundField','earphones','EarphoneResponse',tdh)

Создайте dsp.AudioFileReader возразите, чтобы читать в покадровом звуковом сигнале. Задайте длительность системы координат 50 мс. Это будет длительностью системы координат, по которой вы вычисляете стационарную громкость.
fileReader = dsp.AudioFileReader('Engine-16-44p1-stereo-20sec.wav');
frameDur = 0.05;
fileReader.SamplesPerFrame = round(fileReader.SampleRate*frameDur);Создайте audioDeviceWriter возразите, чтобы записать аудио в ваше устройство вывода по умолчанию.
deviceWriter = audioDeviceWriter('SampleRate',fileReader.SampleRate);Создайте timescope возразите, чтобы отображать стационарную громкость в зависимости от времени.
scope = timescope( ... 'SampleRate',1/frameDur, ... 'YLabel','Loudness (sones)', ... 'ShowGrid',true, ... 'PlotType','Stairs', ... 'TimeSpanSource','property', ... 'TimeSpan',20, ... 'AxesScaling','Auto', ... 'ShowLegend',true);
В цикле:
Считайте систему координат из звукового файла.
Вычислите стационарную громкость той системы координат.
Проигрывайте звук через свое устройство вывода.
Запишите громкость в осциллограф.
while ~isDone(fileReader) audioIn = fileReader(); loudness = acousticLoudness(audioIn,fileReader.SampleRate); deviceWriter(audioIn); scope(loudness) end release(fileReader) release(deviceWriter) release(scope)

Громкость и уровень громкости являются перцепционными атрибутами звука. Из-за различий среди людей, измерения уровня громкости и громкости должны быть рассмотрены статистическими средствами оценки. Ряд ISO 532 задает процедуры для оценки громкости и уровня громкости, как воспринято людьми с онтологическим образом нормальным слушанием при определенных условиях слушания.
ISO 532-1 и ISO 532-2 задают два различных метода для вычисления громкости, но предоставляют пользователю право выбирать соответствующий метод для данной ситуации.
ISO, 532-1:2017 (E), описывает методы для вычисления акустической громкости стационарных и изменяющихся во времени сигналов.
Этот метод основан на DIN 45631:1991. Алгоритм отличается от ISO 532:1975, метод B, путем определения коррекций для низких частот.

Схема и шаги предоставляют общий обзор последовательности метода. Для получения дополнительной информации см. [1].
Уровень сигнала временной области настроен согласно CalibrationFactor. Следующие шаги алгоритма принимают истинный известный уровень сигнала.
Сигнал преобразовывается к 1/3 представлению SPL октавы с помощью дробной фильтрации полосы октавы. Набор фильтров состоит из 28 фильтров между от 25 Гц до 12,5 кГц. Выход от этого этапа находится в дБ и нормирован на ссылочное давление.
Низкая частота 1/3 полосы октавы преуменьшена роль согласно фиксированной таблице взвешивания. Некоторые низкочастотные полосы объединены, чтобы сформировать в общей сложности 20 критических полос.
Уровни критических полос корректируются для полосы пропускания фильтра и критического уровня полосы в пороге тихих, и затем преобразовываются к базовой громкости.
Базовая громкость сопоставлена с интервалами Коры.
Распространение частоты вычисляется с помощью таблицы уровня - и зависимые частотой наклоны.
Громкость вычисляется как интеграл определенной громкости, учитывая распространяющие частоту наклоны.
Этот метод основан на DIN 45631/A1:2010 и спроектирован, чтобы правильно симулировать зависимое длительностью поведение восприятия громкости для коротких импульсов. Метод для изменяющихся во времени звуков является обобщением подхода Zwicker к стационарным сигналам. Если обобщенная версия применяется к стационарным звукам, она дает те же значения громкости как необобщенную форму для стационарных сигналов.

Схема и шаги предоставляют общий обзор последовательности метода. Для получения дополнительной информации см. [1].
Уровень сигнала временной области настроен согласно CalibrationFactor. Следующие шаги алгоритма принимают истинный известный уровень сигнала.
Сигнал преобразовывается к 1/3 представлению SPL октавы с помощью дробной фильтрации полосы октавы. Набор фильтров состоит из 28 фильтров между от 25 Гц до 12,5 кГц. Выход от этого этапа находится в дБ и нормирован на ссылочное давление.
Полосы SPL сглаживаются вдоль времени согласно зависимым полосой фильтрам.
Низкая частота 1/3 полосы октавы преуменьшена роль согласно фиксированной таблице взвешивания. Некоторые низкочастотные полосы объединены, чтобы сформировать в общей сложности 20 критических полос.
Уровни критических полос корректируются для полосы пропускания фильтра и критического уровня полосы в пороге тихих, и затем преобразовываются к базовой громкости.
Нелинейное временное затухание симулировано с помощью диодной конденсаторной резисторной схемы. Это моделирует крутое перцепционное отбрасывание после коротких сигналов когда по сравнению с длинными сигналами.
Базовая громкость сопоставлена с интервалами Коры.
Распространение частоты вычисляется с помощью таблицы уровня - и зависимые частотой наклоны.
Временное взвешивание применяется, чтобы симулировать зависимость длительности восприятия громкости.
Громкость вычисляется как интеграл определенной громкости, учитывая распространяющие частоту наклоны.
ISO, 532-2:2017 (E), описывает бинауральную модель для вычисления акустической громкости стационарных сигналов. Метод в ISO 523-2 отличается от тех по ISO 532:1975: это улучшает расчетную громкость в низкочастотной области значений, и бинауральная модель допускает различные звуки для каждого уха. ISO 532-2 предоставляет хорошее соответствие равным контурам уровня громкости, заданным в ISO 226:2003 и пороге слышимости, заданном в 389-7:2005 ISO.
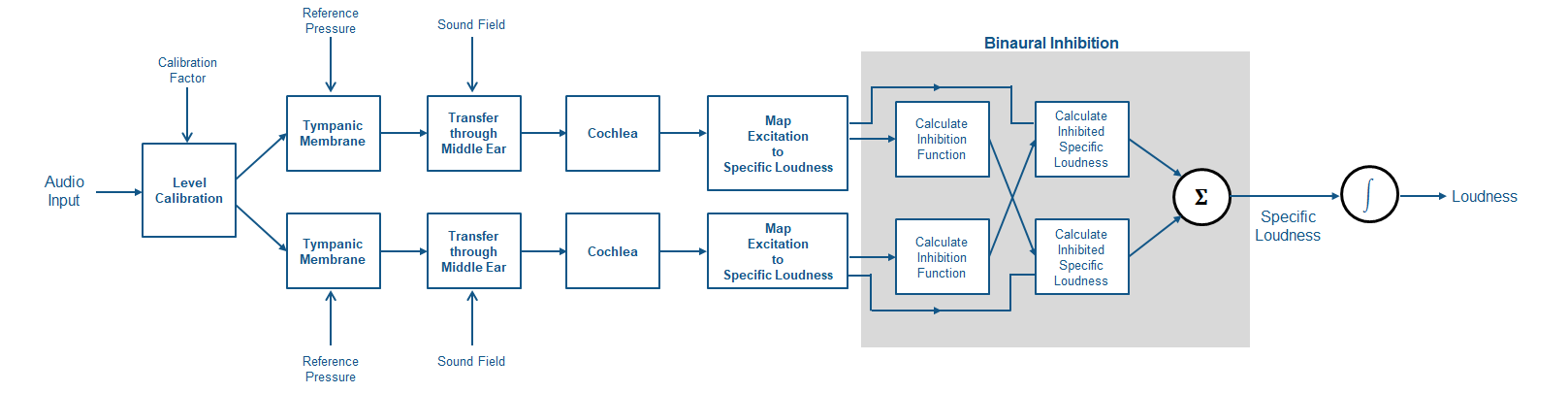
Схема и шаги предоставляют общий обзор последовательности метода. Для получения дополнительной информации см. [2].
Уровень сигнала временной области настроен согласно CalibrationFactor. Следующие шаги алгоритма принимают истинный известный уровень сигнала.
Сигнал преобразовывается к спектральному представлению. Спектральное представление преобразовывается согласно фиксированным фильтрам, представляющим передачу звука через tympanic мембрану (барабанная перепонка). Спектр масштабируется согласно ссылочному давлению.
Сигнал преобразовывается с помощью модели внутреннего уха. Снова, передаточная функция дана фиксированным фильтром, заданным в стандарте. Выбор фильтра зависит от заданного звукового поля.
Сигнал преобразовывается от звукового спектра до шаблона возбуждения в основной мембране. Преобразование выполняется с помощью ряда распространения фильтров округленного экспоненциала по шкале ERB.
Шаблон возбуждения преобразован в определенную громкость.
Определенная громкость передается через модель бинарного ингибирования, где сигнал в одном ухе запрещает громкость, вызванную сигналом в другом ухе. Выход от этого этапа является определенной громкостью в sones/ERB.
Определенная громкость интегрирована по шкале ERB, чтобы дать громкость в сонах.
[1] ISO, 532-1:2017 (E). "Акустика – Методы для вычисления громкости – Часть 1: метод Zwicker". Международная организация по стандартизации.
[2] ISO, 532-2:2017 (E). "Акустика – Методы для вычисления громкости – Часть 2: метод Мура-Глэсберга. Международная организация по стандартизации.
splMeter | acousticSharpness | calibrateMicrophone | sone2phon | phon2sone | acousticFluctuation | acousticRoughness
