Информация об эффективности классификатора
Чтобы просмотреть связанную с эффективностью информацию классификатора, создайте classperformance объект при помощи classperf функция. Используйте запись через точку, чтобы получить доступ к свойствам объектов, таким как CorrectRate, ErrorRate, Sensitivity, и Specificity.
Label — Имя объекта классификатора'' (значение по умолчанию) | вектор символовИмя классификатора возражает в виде вектора символов. Используйте запись через точку, чтобы установить это свойство.
Пример:
'cp_kfold'
Типы данных: char
Description — Описание объекта'' (значение по умолчанию) | вектор символовОписание объекта в виде вектора символов. Используйте запись через точку, чтобы установить это свойство.
Пример:
'performance_data_kfold'
Типы данных: char
ClassLabels — Уникальный набор истинных метокЭто свойство доступно только для чтения.
Уникальный набор истинных меток от groundTruthВ виде вектора из положительных целых чисел или массива ячеек из символьных векторов. Это свойство эквивалентно выходу, когда вы запускаетесь уникальный (.groundTruth)
Пример:
{'ovarian','liver','normal'}
Типы данных: double | cell
GroundTruth — Истинные метки для всех наблюденийЭто свойство доступно только для чтения.
Истинные метки для всех наблюдений в вашем наборе данных в виде вектора из положительных целых чисел или массива ячеек из символьных векторов.
Пример:
{'ovarian','liver','normal','ovarian','ovarian','liver'}
Типы данных: double | cell
NumberOfObservations — Количество наблюденийЭто свойство доступно только для чтения.
Количество наблюдений в вашем наборе данных в виде положительного целого числа.
Пример:
200
Типы данных: double
ControlClasses — Индексы, чтобы управлять классами от истинных метокИндексы к классам управления от истинных меток (ClassLabels) в виде вектора из положительных целых чисел. Это свойство указывает на управление (или отрицательный) классы в диагностическом тесте. По умолчанию, ControlClasses содержит все классы кроме первого класса, возвращенного grp2idx (.groundTruth)
Можно установить это свойство при помощи записи через точку или 'Negative' аргумент пары "имя-значение" с classperf функция.
Пример 3
Типы данных: double
TargetClasses — Индексы, чтобы предназначаться для классов от истинных меток Индексы к целевым классам от истинных меток (ClassLabels) в виде вектора из положительных целых чисел. Это свойство указывает на цель (или положительный) классы в диагностическом тесте. По умолчанию, TargetClasses содержит первый класс, возвращенный grp2idx (.groundTruth)
Можно установить это свойство при помощи записи через точку или 'Positive' аргумент пары "имя-значение" с classperf функция.
Пример:
[1 2]
Типы данных: double
SampleDistribution — Количество оценок для каждой выборкиЭто свойство доступно только для чтения.
Количество оценок для каждой выборки во время валидации в виде числового вектора. Например, если вы используете перезамену, SampleDistribution вектор из единиц и ValidationCounter = 1. Если у вас есть 10-кратная перекрестная проверка, SampleDistribution также вектор из единиц, но ValidationCounter = 10.
SampleDistribution полезно при выполнении разделов Монте-Карло наборов тестов, и это может помочь определить, тестируется ли каждая выборка равное количество времен.
Пример:
[0 0 2 0]
Типы данных: double
ErrorDistribution — Частота misclassification каждой выборкиЭто свойство доступно только для чтения.
Частота misclassification каждой выборки в виде числового вектора.
Пример:
[0 0 1 0]
Типы данных: double
SampleDistributionByClass — Частота истинных классов во время валидацииЭто свойство доступно только для чтения.
Частота истинных классов во время валидации в виде числового вектора.
Пример:
[10 10 0]
Типы данных: double
ErrorDistributionByClass — Частота ошибок для каждого классаЭто свойство доступно только для чтения.
Частота ошибок для каждого класса во время валидации в виде числового вектора.
Пример:
[0 0 0]
Типы данных: double
ValidationCounter — Количество валидацийЭто свойство доступно только для чтения.
Количество валидаций в виде положительного целого числа.
Пример:
10
Типы данных: double
CountingMatrix — Матрица беспорядка классификацииЭто свойство доступно только для чтения.
Матрица беспорядка классификации в виде числового массива. Порядок строк и столбцов в матрице эквивалентен в grp2idx(groundTruth). Столбцы представляют истинные классы, и строки представляют предсказание классификатора. Последняя строка в CountingMatrix резервируется для подсчета неокончательных результатов.
Пример:
[10 0 0;0 10 0; 0 0 0; 0 0 0]
Типы данных: double
CorrectRate — Правильный уровень классификатораЭто свойство доступно только для чтения.
Правильный уровень классификатора в виде положительной скалярной величины. CorrectRate задан как количество правильно классифицированных выборок, разделенных на количество классифицированных выборок. Неокончательные результаты не считаются.
Пример 1
Типы данных: double
ErrorRate — Коэффициент ошибок классификатораЭто свойство доступно только для чтения.
Коэффициент ошибок классификатора в виде положительной скалярной величины. ErrorRate задан как количество неправильно классифицированных выборок, разделенных на количество классифицированных выборок. Неокончательные результаты не считаются.
Пример: 0
Типы данных: double
LastCorrectRate — Правильный уровень классификатора во время последнего запускаЭто свойство доступно только для чтения.
Правильный уровень классификатора во время последней валидации, запущенной в виде положительной скалярной величины. В отличие от CorrectRate, LastCorrectRate только применяется к оцененным выборкам от нового запуска валидации объекта управления классификатора.
Пример 1
Типы данных: double
LastErrorRate — Коэффициент ошибок классификатора во время последней валидацииЭто свойство доступно только для чтения.
Коэффициент ошибок классификатора во время последней валидации, запущенной в виде положительной скалярной величины. В отличие от ErrorRate, LastErrorRate только применяется к оцененным выборкам от нового запуска валидации объекта управления классификатора.
Пример:
0
Типы данных: double
InconclusiveRate — Неокончательный уровень классификатораЭто свойство доступно только для чтения.
Неокончательный уровень классификатора в виде положительной скалярной величины. InconclusiveRate задан как количество незасекреченных (неокончательных) выборок, разделенных на общее количество выборок.
Пример:
0
Типы данных: double
ClassifiedRate — Классифицированный уровень классификатораЭто свойство доступно только для чтения.
Классифицированный уровень классификатора в виде положительной скалярной величины. ClassifiedRate задан как количество классифицированных выборок, разделенных на общее количество выборок.
Пример 1
Типы данных: double
Sensitivity — Чувствительность классификатораЭто свойство доступно только для чтения.
Чувствительность классификатора в виде положительной скалярной величины. Sensitivity задан как количество правильно классифицированных положительных выборок, разделенных на количество истинных положительных выборок.
Неокончательные результаты, которые являются истинными положительными сторонами, считаются как ошибки для вычисления Sensitivity. Другими словами, неокончательные результаты могут уменьшить диагностическое значение теста.
Пример 1
Типы данных: double
Specificity — Специфика классификатораЭто свойство доступно только для чтения.
Специфика классификатора в виде положительной скалярной величины. Specificity задан как количество правильно классифицированных отрицательных выборок, разделенных на количество истинных отрицательных выборок.
Неокончательные результаты, которые являются истинными отрицательными сторонами, считаются как ошибки для вычисления Specificity. Другими словами, неокончательные результаты могут уменьшить диагностическое значение теста.
Пример:
0.8
Типы данных: double
PositivePredictiveValue — Положительное прогнозирующее значение классификатораЭто свойство доступно только для чтения.
Положительное прогнозирующее значение классификатора в виде положительной скалярной величины. PositivePredictiveValue задан как количество правильно классифицированных положительных выборок, разделенных на количество положительных классифицированных выборок.
Неокончательные результаты классифицируются как отрицательные при вычислении PositivePredictiveValue.
Пример 1
Типы данных: double
NegativePredictiveValue — Отрицательное прогнозирующее значение классификатораЭто свойство доступно только для чтения.
Отрицательное прогнозирующее значение классификатора в виде положительной скалярной величины. NegativePredictiveValue задан как количество правильно классифицированных отрицательных выборок, разделенных на количество отрицательных классифицированных выборок.
Неокончательные результаты классифицируются как положительные при вычислении NegativePredictiveValue.
Пример 1
Типы данных: double
PositiveLikelihood — Положительная вероятность классификатораЭто свойство доступно только для чтения.
Положительная вероятность классификатора в виде положительной скалярной величины. PositiveLikelihood задан как Sensitivity / (1 - Specificity)
Пример 5
Типы данных: double
NegativeLikelihood — Отрицательная вероятность классификатораЭто свойство доступно только для чтения.
Отрицательная вероятность классификатора в виде положительной скалярной величины. NegativeLikelihood задан как (1 - .Sensitivity)/Specificity
Пример: 0
Типы данных: double
Prevalence — Распространенность классификатораЭто свойство доступно только для чтения.
Распространенность классификатора в виде положительной скалярной величины. Prevalence задан как количество истинных положительных выборок, разделенных на общее количество выборок.
Пример 1
Типы данных: double
DiagnosticTable — Диагностическая таблицаЭто свойство доступно только для чтения.
Диагностическая таблица в виде two-two числового массива. Первая строка указывает на количество отсчетов, классифицированное как положительное с количеством истинных положительных сторон в первом столбце и количеством ложных положительных сторон во втором столбце. Вторая строка указывает на количество отсчетов, классифицированное как отрицательное с количеством ложных отрицательных сторон в первом столбце и количеством истинных отрицательных сторон во втором столбце.
Правильные классификации появляются в диагональных элементах, и ошибки появляются в недиагональных элементах. Неокончательные результаты рассматриваются ошибками и считаются в недиагональных элементах. Для примера смотрите Диагностический Табличный Пример.
Пример:
[20 0;0 0]
Типы данных: double
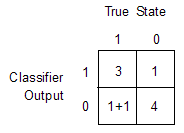
Предположим, что изучение рака 10 пациентов приводит к этим результатам.
| Пациент | Классификатор Выход | Имеет рак |
|---|---|---|
| 1 | Положительный | Да |
| 2 | Положительный | Да |
| 3 | Положительный | Да |
| 4 | Положительный | Нет |
| 5 | Отрицательный | Да |
| 6 | Отрицательный | Нет |
| 7 | Отрицательный | Нет |
| 8 | Отрицательный | Нет |
| 9 | Отрицательный | Нет |
| 10 | Неокончательный | Да |
Используя эти результаты, функция вычисляет DiagnosticTable можно следующим образом:
classperf | crossvalind | classify | grp2idx
1. Если смысл перевода понятен, то лучше оставьте как есть и не придирайтесь к словам, синонимам и тому подобному. О вкусах не спорим.
2. Не дополняйте перевод комментариями “от себя”. В исправлении не должно появляться дополнительных смыслов и комментариев, отсутствующих в оригинале. Такие правки не получится интегрировать в алгоритме автоматического перевода.
3. Сохраняйте структуру оригинального текста - например, не разбивайте одно предложение на два.
4. Не имеет смысла однотипное исправление перевода какого-то термина во всех предложениях. Исправляйте только в одном месте. Когда Вашу правку одобрят, это исправление будет алгоритмически распространено и на другие части документации.
5. По иным вопросам, например если надо исправить заблокированное для перевода слово, обратитесь к редакторам через форму технической поддержки.
