Выполните выбор переменного предиктора для Байесовых моделей линейной регрессии
Чтобы оценить апостериорное распределение стандартной Байесовой модели линейной регрессии, смотрите estimate.
PosteriorMdl = estimate(PriorMdl,X,y)estimate также выполняет выбор переменного предиктора.
PriorMdl задает объединенное предшествующее распределение параметров, структуру модели линейной регрессии и алгоритма выбора переменной. X данные о предикторе и y данные об ответе. PriorMdl и PosteriorMdl не тот же тип объекта.
Произвести PosteriorMdl, estimate обновляет предшествующее распределение с информацией о параметрах, которые это получает из данных.
NaNs в данных указывают на отсутствующие значения, который estimate удаляет использующее мудрое списком удаление.
PosteriorMdl = estimate(PriorMdl,X,y,Name,Value)'Lambda',0.5 указывает, что значением параметров уменьшения для Байесовой регрессии лассо является 0.5 для всех коэффициентов кроме точки пересечения.
Если вы задаете Beta или Sigma2, затем PosteriorMdl и PriorMdl равны.
[ использование любая из комбинаций входных аргументов в предыдущих синтаксисах и также возвращает таблицу, которая включает следующее для каждого параметра: следующие оценки, стандартные погрешности, 95%-е вероятные интервалы и апостериорная вероятность, что параметр больше 0.PosteriorMdl,Summary]
= estimate(___)
Рассмотрите модель многофакторной линейной регрессии, которая предсказывает США действительный валовой национальный продукт (GNPR) использование линейной комбинации индекса промышленного производства (IPI), общая занятость (E), и действительная заработная плата (WR).
\forall , серия независимых Гауссовых воздействий со средним значением 0 и отклонение .
Примите, что предшествующие распределения:
Для k = 0..., 3, имеет распределение Лапласа со средним значением 0 и шкалой , где параметр уменьшения. Коэффициенты условно независимы.
. и форма и шкала, соответственно, обратного гамма распределения.
Создайте предшествующую модель для Байесовой регрессии лассо. Задайте количество предикторов, предшествующего типа модели и имен переменных. Задайте эти уменьшения:
0.01 для точки пересечения
10 для IPI и WR
1e5 для E потому что это имеет шкалу, которая является несколькими порядками величины, больше, чем другие переменные
Порядок уменьшений выполняет приказ заданных имен переменных, но первым элементом является уменьшение точки пересечения.
p = 3; PriorMdl = bayeslm(p,'ModelType','lasso','Lambda',[0.01; 10; 1e5; 10],... 'VarNames',["IPI" "E" "WR"]);
PriorMdl lassoblm Байесов объект модели линейной регрессии, представляющий предшествующее распределение коэффициентов регрессии и отклонения воздействия.
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для ряда предиктора и ответа.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,"GNPR"};
Выполните Байесовую регрессию лассо путем передачи предшествующей модели и данных к estimate, то есть, путем оценки апостериорного распределения и . Байесова регрессия лассо использует Цепь Маркова Монте-Карло (MCMC) для выборки от следующего. Для воспроизводимости установите случайный seed.
rng(1); PosteriorMdl = estimate(PriorMdl,X,y);
Method: lasso MCMC sampling with 10000 draws
Number of observations: 62
Number of predictors: 4
| Mean Std CI95 Positive Distribution
-------------------------------------------------------------------------
Intercept | -1.3472 6.8160 [-15.169, 11.590] 0.427 Empirical
IPI | 4.4755 0.1646 [ 4.157, 4.799] 1.000 Empirical
E | 0.0001 0.0002 [-0.000, 0.000] 0.796 Empirical
WR | 3.1610 0.3136 [ 2.538, 3.760] 1.000 Empirical
Sigma2 | 60.1452 11.1180 [42.319, 85.085] 1.000 Empirical
PosteriorMdl empiricalblm объект модели, из которого хранилища чертят от апостериорных распределений и учитывая данные. estimate отображает сводные данные крайних апостериорных распределений в командной строке MATLAB®. Строки сводных данных соответствуют коэффициентам регрессии и отклонению воздействия, и столбцы соответствуют характеристикам апостериорного распределения. Характеристики включают:
CI95, который содержит 95%-е Байесовы equitailed вероятные интервалы для параметров. Например, апостериорная вероятность, что коэффициент регрессии IPI находится в [4.157, 4.799] 0.95.
Positive, который содержит апостериорную вероятность, что параметр больше 0. Например, вероятностью, что точка пересечения больше 0, является 0.427.
Постройте апостериорные распределения.
plot(PosteriorMdl)

Учитывая уменьшения, распределение E является довольно плотным приблизительно 0. Поэтому E не может быть важный предиктор.
По умолчанию, estimate чертит и отбрасывает выборку выжигания дефектов размера 5000. Однако хорошая практика должна смотреть график трассировки ничьих для соответствующего смешивания и отсутствия быстротечности. Постройте график трассировки ничьих для каждого параметра. Можно получить доступ к ничьим, которые составляют распределение (свойства BetaDraws и Sigma2Draws) использование записи через точку.
figure; for j = 1:(p + 1) subplot(2,2,j); plot(PosteriorMdl.BetaDraws(j,:)); title(sprintf('%s',PosteriorMdl.VarNames{j})); end

figure;
plot(PosteriorMdl.Sigma2Draws);
title('Sigma2');
Графики трассировки показывают, что ничьи, кажется, смешиваются хорошо. Графики не показывают обнаруживаемой быстротечности или последовательной корреляции, и ничьи не переходят между состояниями.
Полагайте, что модель регрессии в Выбирает Variables Using Bayesian Lasso Regression.
Создайте предшествующую модель для выполнения стохастического поискового выбора переменной (SSVS). AssumeThat и зависят (сопряженная модель смеси). Задайте количество предикторов p и имена коэффициентов регрессии.
p = 3; PriorMdl = mixconjugateblm(p,'VarNames',["IPI" "E" "WR"]);
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для ряда предиктора и ответа.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,'GNPR'};
Реализуйте SSVS путем оценки крайних апостериорных распределений и . Поскольку SSVS использует Цепь Маркова Монте-Карло для оценки, установите seed случайных чисел воспроизводить результаты.
rng(1); PosteriorMdl = estimate(PriorMdl,X,y);
Method: MCMC sampling with 10000 draws
Number of observations: 62
Number of predictors: 4
| Mean Std CI95 Positive Distribution Regime
----------------------------------------------------------------------------------
Intercept | -18.8333 10.1851 [-36.965, 0.716] 0.037 Empirical 0.8806
IPI | 4.4554 0.1543 [ 4.165, 4.764] 1.000 Empirical 0.4545
E | 0.0010 0.0004 [ 0.000, 0.002] 0.997 Empirical 0.0925
WR | 2.4686 0.3615 [ 1.766, 3.197] 1.000 Empirical 0.1734
Sigma2 | 47.7557 8.6551 [33.858, 66.875] 1.000 Empirical NaN
PosteriorMdl empiricalblm объект модели, из которого хранилища чертят от апостериорных распределений и учитывая данные. estimate отображает сводные данные крайних апостериорных распределений в командной строке. Строки сводных данных соответствуют коэффициентам регрессии и отклонению воздействия, и столбцы соответствуют характеристикам апостериорного распределения. Характеристики включают:
CI95, который содержит 95%-е Байесовы equitailed вероятные интервалы для параметров. Например, апостериорная вероятность, что коэффициент регрессии E (стандартизированный) находится в [0.000, 0.0.002] 0.95.
Regime, который содержит крайнюю апостериорную вероятность переменного включения ( для переменной). Например, апостериорная вероятность E это должно быть включено в модель, 0.0925.
Принятие этого переменные с Regime <0.1 должен быть удален из модели, результаты предполагают, что можно исключить уровень безработицы из модели.
По умолчанию, estimate чертит и отбрасывает выборку выжигания дефектов размера 5000. Однако хорошая практика должна смотреть график трассировки ничьих для соответствующего смешивания и отсутствия быстротечности. Постройте график трассировки ничьих для каждого параметра. Можно получить доступ к ничьим, которые составляют распределение (свойства BetaDraws и Sigma2Draws) использование записи через точку.
figure; for j = 1:(p + 1) subplot(2,2,j); plot(PosteriorMdl.BetaDraws(j,:)); title(sprintf('%s',PosteriorMdl.VarNames{j})); end

figure;
plot(PosteriorMdl.Sigma2Draws);
title('Sigma2');
Графики трассировки показывают, что ничьи, кажется, смешиваются хорошо. Графики не показывают обнаруживаемой быстротечности или последовательной корреляции, и ничьи не переходят между состояниями.
Рассмотрите регрессию и предшествующее распределение, модели в Выбирает Variables Using Bayesian Lasso Regression.
Создайте Байесовую регрессию лассо предшествующая модель для 3 предикторов и задайте имена переменных. Задайте значения уменьшения 0.01, 10, 1e5, и 10 для точки пересечения и коэффициентов IPIE, и WR.
p = 3; PriorMdl = bayeslm(p,'ModelType','lasso','VarNames',["IPI" "E" "WR"],... 'Lambda',[0.01; 10; 1e5; 10]);
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для ряда предиктора и ответа.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,"GNPR"};
Оцените условное апостериорное распределение учитывая данные и это , и возвратите сводную таблицу оценки, чтобы получить доступ к оценкам.
rng(1); % For reproducibility [Mdl,SummaryBeta] = estimate(PriorMdl,X,y,'Sigma2',10);
Method: lasso MCMC sampling with 10000 draws
Conditional variable: Sigma2 fixed at 10
Number of observations: 62
Number of predictors: 4
| Mean Std CI95 Positive Distribution
------------------------------------------------------------------------
Intercept | -8.0643 4.1992 [-16.384, 0.018] 0.025 Empirical
IPI | 4.4454 0.0679 [ 4.312, 4.578] 1.000 Empirical
E | 0.0004 0.0002 [ 0.000, 0.001] 0.999 Empirical
WR | 2.9792 0.1672 [ 2.651, 3.305] 1.000 Empirical
Sigma2 | 10 0 [10.000, 10.000] 1.000 Empirical
estimate отображает сводные данные условного апостериорного распределения . Поскольку фиксируется в 10 во время оценки, выводы на ней тривиальны.
Отобразите Mdl.
Mdl
Mdl =
lassoblm with properties:
NumPredictors: 3
Intercept: 1
VarNames: {4x1 cell}
Lambda: [4x1 double]
A: 3
B: 1
| Mean Std CI95 Positive Distribution
---------------------------------------------------------------------------
Intercept | 0 100 [-200.000, 200.000] 0.500 Scale mixture
IPI | 0 0.1000 [-0.200, 0.200] 0.500 Scale mixture
E | 0 0.0000 [-0.000, 0.000] 0.500 Scale mixture
WR | 0 0.1000 [-0.200, 0.200] 0.500 Scale mixture
Sigma2 | 0.5000 0.5000 [ 0.138, 1.616] 1.000 IG(3.00, 1)
Поскольку estimate вычисляет условное апостериорное распределение, оно возвращает вход PriorMdl модели, не следующее условное выражение, в первом положении списка выходных аргументов.
Отобразите сводную таблицу оценки.
SummaryBeta
SummaryBeta=5×6 table
Mean Std CI95 Positive Distribution Covariances
__________ __________ ________________________ ________ _____________ _______________________________________________________________________
Intercept -8.0643 4.1992 -16.384 0.01837 0.0254 {'Empirical'} 17.633 0.17621 -0.00053724 0.11705 0
IPI 4.4454 0.067949 4.312 4.5783 1 {'Empirical'} 0.17621 0.0046171 -1.4103e-06 -0.0068855 0
E 0.00039896 0.00015673 9.4925e-05 0.00070697 0.9987 {'Empirical'} -0.00053724 -1.4103e-06 2.4564e-08 -1.8168e-05 0
WR 2.9792 0.16716 2.6506 3.3046 1 {'Empirical'} 0.11705 -0.0068855 -1.8168e-05 0.027943 0
Sigma2 10 0 10 10 1 {'Empirical'} 0 0 0 0 0
SummaryBeta содержит условные следующие оценки.
Оцените условные апостериорные распределения учитывая, что условное следующее среднее значение (сохраненный в SummaryBeta.Mean(1:(end – 1))). Возвратите сводную таблицу оценки.
condPostMeanBeta = SummaryBeta.Mean(1:(end - 1));
[~,SummarySigma2] = estimate(PriorMdl,X,y,'Beta',condPostMeanBeta);Method: lasso MCMC sampling with 10000 draws
Conditional variable: Beta fixed at -8.0643 4.4454 0.00039896 2.9792
Number of observations: 62
Number of predictors: 4
| Mean Std CI95 Positive Distribution
------------------------------------------------------------------------
Intercept | -8.0643 0.0000 [-8.064, -8.064] 0.000 Empirical
IPI | 4.4454 0.0000 [ 4.445, 4.445] 1.000 Empirical
E | 0.0004 0.0000 [ 0.000, 0.000] 1.000 Empirical
WR | 2.9792 0.0000 [ 2.979, 2.979] 1.000 Empirical
Sigma2 | 56.8314 10.2921 [39.947, 79.731] 1.000 Empirical
estimate отображает сводные данные оценки условного апостериорного распределения учитывая данные и это condPostMeanBeta. В отображении, выводах на тривиальны.
Полагайте, что модель регрессии в Выбирает Variables Using Bayesian Lasso Regression.
Создайте предшествующую модель для выполнения SSVS. AssumeThat и зависят (сопряженная модель смеси). Задайте количество предикторов p и имена коэффициентов регрессии.
p = 3; PriorMdl = mixconjugateblm(p,'VarNames',["IPI" "E" "WR"]);
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для ряда предиктора и ответа.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,'GNPR'};
Реализуйте SSVS путем оценки крайних апостериорных распределений и . Поскольку SSVS использует Цепь Маркова Монте-Карло для оценки, установите seed случайных чисел воспроизводить результаты. Подавите отображение оценки, но возвратите сводную таблицу оценки.
rng(1);
[PosteriorMdl,Summary] = estimate(PriorMdl,X,y,'Display',false);PosteriorMdl empiricalblm объект модели, из которого хранилища чертят от апостериорных распределений и учитывая данные. Summary таблица со столбцами, соответствующими следующим характеристикам и строкам, соответствующим коэффициентам (PosteriorMdl.VarNames) и отклонение воздействия (Sigma2).
Отобразите предполагаемую ковариационную матрицу параметра (Covariances) и пропорция времен алгоритм включает каждый предиктор (Regime).
Covariances = Summary(:,"Covariances")Covariances=5×1 table
Covariances
______________________________________________________________________
Intercept 103.74 1.0486 -0.0031629 0.6791 7.3916
IPI 1.0486 0.023815 -1.3637e-05 -0.030387 0.06611
E -0.0031629 -1.3637e-05 1.3481e-07 -8.8792e-05 -0.00025044
WR 0.6791 -0.030387 -8.8792e-05 0.13066 0.089039
Sigma2 7.3916 0.06611 -0.00025044 0.089039 74.911
Regime = Summary(:,"Regime")Regime=5×1 table
Regime
______
Intercept 0.8806
IPI 0.4545
E 0.0925
WR 0.1734
Sigma2 NaN
Regime содержит крайнюю апостериорную вероятность переменного включения ( для переменной). Например, апостериорная вероятность, что E должен быть включен в модель, 0.0925.
Принятие этого переменные с Regime <0.1 должен быть удален из модели, результаты предполагают, что можно исключить уровень безработицы из модели.
Симуляция Монте-Карло подвергается изменению. Если estimate симуляция Монте-Карло использования, затем оценивает, и выводы могут варьироваться, когда вы вызываете estimate многократно при на вид эквивалентных условиях. Воспроизвести результаты оценки, перед вызовом estimate, установите seed случайных чисел при помощи rng.
Этот рисунок показывает как estimate уменьшает выборку Монте-Карло использование значений NumDraws, Thin, и BurnIn.
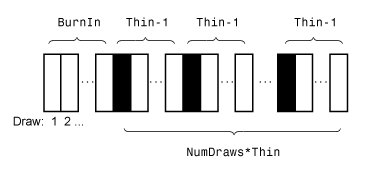
Прямоугольники представляют последовательные ничьи от распределения. estimate удаляет белые прямоугольники из выборки Монте-Карло. Остающийся NumDraws черные прямоугольники составляют выборку Монте-Карло.
