Симулируйте коэффициенты регрессии и отклонение воздействия Байесовой модели линейной регрессии
[ возвращает случайный вектор из коэффициентов регрессии (BetaSim,sigma2Sim]
= simulate(Mdl)BetaSim) и случайное отклонение воздействия (sigma2Sim) чертивший из Байесовой модели
Mdl линейной регрессии из β и σ2.
[ чертит от крайних апостериорных распределений, произведенных или обновленных путем слияния данных о предикторе BetaSim,sigma2Sim]
= simulate(Mdl,X,y)X и соответствующие данные об ответе y.
Если Mdl объединенная предшествующая модель, затем simulate производит крайние апостериорные распределения путем обновления предшествующей модели с информацией о параметрах, которые это получает из данных.
Если Mdl крайняя следующая модель, затем simulate обновляет последующее поколение с информацией о параметрах, которые она получает из дополнительных данных. Вероятность полных данных состоит из дополнительных данных X и y, и данные, которые создали Mdl.
NaNs в данных указывают на отсутствующие значения, который simulate удаляет при помощи мудрого списком удаления.
[ использование любая из комбинаций входных аргументов в предыдущих синтаксисах и дополнительных опциях задано одним или несколькими аргументами пары "имя-значение". Например, можно задать значение для β или σ2 симулировать от апостериорного распределения conditional одного параметра, учитывая заданное значение другого параметра.BetaSim,sigma2Sim]
= simulate(___,Name,Value)
[ также возвращается, чертит от скрытого распределения режима если BetaSim,sigma2Sim,RegimeSim]
= simulate(___)Mdl Байесова модель линейной регрессии для стохастического поискового выбора переменной (SSVS), то есть, если Mdl mixconjugateblm или mixsemiconjugateblm объект модели.
Рассмотрите модель многофакторной линейной регрессии, которая предсказывает США действительный валовой национальный продукт (GNPR) при помощи линейной комбинации индекса промышленного производства (IPI), общая занятость (E), и действительная заработная плата (WR).
\forall , серия независимых Гауссовых воздействий со средним значением 0 и отклонение .
Примите эти предшествующие распределения:
. 4 1 вектор из средних значений, и масштабированная положительная определенная ковариационная матрица 4 на 4.
. и форма и шкала, соответственно, обратного гамма распределения.
Эти предположения и вероятность данных подразумевают нормальную обратную гамму сопряженная модель.
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для ряда предиктора и ответа.
load Data_NelsonPlosser varNames = {'IPI' 'E' 'WR'}; X = DataTable{:,varNames}; y = DataTable{:,'GNPR'};
Создайте сопряженную предшествующую модель нормальной обратной гаммы для параметров линейной регрессии. Задайте количество предикторов p и имена переменных.
p = 3; PriorMdl = bayeslm(p,'ModelType','conjugate','VarNames',varNames);
PriorMdl conjugateblm Байесов объект модели линейной регрессии, представляющий предшествующее распределение коэффициентов регрессии и отклонения воздействия.
Симулируйте набор коэффициентов регрессии и значение отклонения воздействия от предшествующего распределения.
rng(1); % For reproducibility
[betaSimPrior,sigma2SimPrior] = simulate(PriorMdl)betaSimPrior = 4×1
-33.5917
-49.1445
-37.4492
-25.3632
sigma2SimPrior = 0.1962
betaSimPrior случайным образом чертивший 4 1 вектор из коэффициентов регрессии, соответствующих именам в PriorMdl.VarNames. sigma2SimPrior выход является случайным образом чертившим скалярным отклонением воздействия.
Оцените апостериорное распределение.
PosteriorMdl = estimate(PriorMdl,X,y);
Method: Analytic posterior distributions
Number of observations: 62
Number of predictors: 4
Log marginal likelihood: -259.348
| Mean Std CI95 Positive Distribution
-----------------------------------------------------------------------------------
Intercept | -24.2494 8.7821 [-41.514, -6.985] 0.003 t (-24.25, 8.65^2, 68)
IPI | 4.3913 0.1414 [ 4.113, 4.669] 1.000 t (4.39, 0.14^2, 68)
E | 0.0011 0.0003 [ 0.000, 0.002] 1.000 t (0.00, 0.00^2, 68)
WR | 2.4683 0.3490 [ 1.782, 3.154] 1.000 t (2.47, 0.34^2, 68)
Sigma2 | 44.1347 7.8020 [31.427, 61.855] 1.000 IG(34.00, 0.00069)
PosteriorMdl conjugateblm Байесов объект модели линейной регрессии, представляющий апостериорное распределение коэффициентов регрессии и отклонения воздействия.
Симулируйте набор коэффициентов регрессии и значение отклонения воздействия от апостериорного распределения.
[betaSimPost,sigma2SimPost] = simulate(PosteriorMdl)
betaSimPost = 4×1
-25.9351
4.4379
0.0012
2.4072
sigma2SimPost = 41.9575
betaSimPost и sigma2SimPost имейте те же размерности как betaSimPrior и sigma2SimPrior, соответственно, но чертятся от следующего.
Полагайте, что модель регрессии в Симулирует Значение параметров от Предшествующих и Апостериорных распределений.
Загрузите данные и создайте сопряженную предшествующую модель для коэффициентов регрессии и отклонения воздействия. Затем оцените апостериорное распределение и возвратите сводную таблицу оценки.
load Data_NelsonPlosser varNames = {'IPI' 'E' 'WR'}; X = DataTable{:,varNames}; y = DataTable{:,'GNPR'}; p = 3; PriorMdl = bayeslm(p,'ModelType','conjugate','VarNames',varNames); [PosteriorMdl,Summary] = estimate(PriorMdl,X,y);
Method: Analytic posterior distributions
Number of observations: 62
Number of predictors: 4
Log marginal likelihood: -259.348
| Mean Std CI95 Positive Distribution
-----------------------------------------------------------------------------------
Intercept | -24.2494 8.7821 [-41.514, -6.985] 0.003 t (-24.25, 8.65^2, 68)
IPI | 4.3913 0.1414 [ 4.113, 4.669] 1.000 t (4.39, 0.14^2, 68)
E | 0.0011 0.0003 [ 0.000, 0.002] 1.000 t (0.00, 0.00^2, 68)
WR | 2.4683 0.3490 [ 1.782, 3.154] 1.000 t (2.47, 0.34^2, 68)
Sigma2 | 44.1347 7.8020 [31.427, 61.855] 1.000 IG(34.00, 0.00069)
Summary таблица, содержащая статистику что estimate отображения в командной строке.
Несмотря на то, что крайние и условные апостериорные распределения и аналитически послушны, этот пример особое внимание о том, как реализовать сэмплер Гиббса, чтобы воспроизвести известные результаты.
Оцените модель снова, но используйте сэмплер Гиббса. Альтернатива между выборкой от условных апостериорных распределений параметров. Демонстрационные 10,000 раз и создайте переменные для предварительного выделения. Запустите сэмплер путем рисования от условного выражения, следующего из данный .
m = 1e4; BetaDraws = zeros(p + 1,m); sigma2Draws = zeros(1,m + 1); sigma2Draws(1) = 2; rng(1); % For reproducibility for j = 1:m BetaDraws(:,j) = simulate(PriorMdl,X,y,'Sigma2',sigma2Draws(j)); [~,sigma2Draws(j + 1)] = simulate(PriorMdl,X,y,'Beta',BetaDraws(:,j)); end sigma2Draws = sigma2Draws(2:end); % Remove initial value from MCMC sample
Графики трассировки графика параметров.
figure; for j = 1:(p + 1); subplot(2,2,j); plot(BetaDraws(j,:)) ylabel('MCMC Draw') xlabel('Simulation Index') title(sprintf('Trace Plot — %s',PriorMdl.VarNames{j})); end

figure; plot(sigma2Draws) ylabel('MCMC Draw') xlabel('Simulation Index') title('Trace plot — Sigma2')

Выборки Цепи Маркова Монте-Карло (MCMC), кажется, сходятся и смешиваются хорошо.
Применяйтесь электротермотренировка 1 000 чертит, и затем вычислите средние значения и стандартные отклонения выборок MCMC. Сравните их с оценками от estimate.
bp = 1000; postBetaMean = mean(BetaDraws(:,(bp + 1):end),2); postSigma2Mean = mean(sigma2Draws(:,(bp + 1):end)); postBetaStd = std(BetaDraws(:,(bp + 1):end),[],2); postSigma2Std = std(sigma2Draws((bp + 1):end)); [Summary(:,1:2),table([postBetaMean; postSigma2Mean],... [postBetaStd; postSigma2Std],'VariableNames',{'GibbsMean','GibbsStd'})]
ans=5×4 table
Mean Std GibbsMean GibbsStd
_________ __________ _________ __________
Intercept -24.249 8.7821 -24.293 8.748
IPI 4.3913 0.1414 4.3917 0.13941
E 0.0011202 0.00032931 0.0011229 0.00032875
WR 2.4683 0.34895 2.4654 0.34364
Sigma2 44.135 7.802 44.011 7.7816
Оценки очень близки. Изменения MCMC составляют различия.
Полагайте, что модель регрессии в Симулирует Значение параметров от Предшествующих и Апостериорных распределений.
Примите эти предшествующие распределения для = 0,...,3:
, где и независимые, стандартные нормальные случайные переменные. Поэтому коэффициенты имеют Гауссово распределение смеси. Примите, что все коэффициенты условно независимы, априорно, но они зависят от отклонения воздействия.
. и форма и шкала, соответственно, обратного гамма распределения.
и это представляет переменную режима включения случайной переменной дискретным равномерным распределением.
Создайте предшествующую модель для выполнения SSVS. AssumeThat и зависят (сопряженная модель смеси). Задайте количество предикторов p и имена коэффициентов регрессии.
p = 3; PriorMdl = mixconjugateblm(p,'VarNames',["IPI" "E" "WR"]);
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для ряда предиктора и ответа.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,'GNPR'};
Вычислите количество возможных режимов, то есть, количество комбинаций, которые следуют включая и, исключая переменные в модели.
cardRegime = 2^(PriorMdl.Intercept + PriorMdl.NumPredictors)
cardRegime = 16
Симулируйте 10 000 режимов от апостериорного распределения.
rng(1);
[~,~,RegimeSim] = simulate(PriorMdl,X,y,'NumDraws',10000);RegimeSim 4 1000 логическая матрица. Строки соответствуют переменным в Mdl.VarNames, и столбцы соответствуют, чертит от апостериорного распределения.
Постройте гистограмму режимов, которые посещают. Повторно закодируйте режимы так, чтобы они были читаемы. А именно, для каждого режима создайте строку, которая идентифицирует переменные в модели, и разделите переменные точками.
cRegime = num2cell(RegimeSim,1); cRegime = categorical(cellfun(@(c)join(PriorMdl.VarNames(c),"."),cRegime)); cRegime(ismissing(cRegime)) = "NoCoefficients"; histogram(cRegime); title('Variables Included in Models') ylabel('Frequency');

Вычислите крайнюю апостериорную вероятность переменного включения.
table(mean(RegimeSim,2),'RowNames',PriorMdl.VarNames,... 'VariableNames',"Regime")
ans=4×1 table
Regime
______
Intercept 0.8829
IPI 0.4547
E 0.098
WR 0.1692
Рассмотрите Байесовую модель линейной регрессии, содержащую один предиктор, и t распределил отклонение воздействия профилируемым параметром степеней свободы .
.
Эти предположения подразумевают:
вектор из скрытых масштабных коэффициентов, который приписывает низкую точность наблюдениям, далеким от линии регрессии. гиперпараметр, управляющий влиянием на наблюдениях.
Для этой проблемы сэмплер Гиббса хорошо подходит оценивать коэффициенты, потому что можно симулировать параметры Байесовой модели линейной регрессии, обусловленной на , и затем симулируйте от его условного распределения.
Сгенерировать ответы от где и .
rng('default');
n = 100;
x = linspace(0,2,n)';
b0 = 1;
b1 = 2;
sigma = 0.5;
e = randn(n,1);
y = b0 + b1*x + sigma*e;Введите отдаленные ответы путем расширения всех ответов ниже на коэффициент 3.
y(x < 0.25) = y(x < 0.25)*3;
Подбор линейной модели к данным. Отобразите на графике данные и подходящую линию регрессии.
Mdl = fitlm(x,y)
Mdl =
Linear regression model:
y ~ 1 + x1
Estimated Coefficients:
Estimate SE tStat pValue
________ _______ ______ __________
(Intercept) 2.6814 0.28433 9.4304 2.0859e-15
x1 0.78974 0.24562 3.2153 0.0017653
Number of observations: 100, Error degrees of freedom: 98
Root Mean Squared Error: 1.43
R-squared: 0.0954, Adjusted R-Squared: 0.0862
F-statistic vs. constant model: 10.3, p-value = 0.00177
figure;
plot(Mdl);
hl = legend;
hold on;
Симулированные выбросы, кажется, влияют на подходящую линию регрессии.
Реализуйте этот сэмплер Гиббса:
Чертите параметры от апостериорного распределения . Выкачайте наблюдения , создайте рассеянную предшествующую модель с двумя коэффициентами регрессии и чертите набор параметров от следующего. Первый коэффициент регрессии соответствует точке пересечения, поэтому задайте тот bayeslm не включают точку пересечения.
Вычислите остаточные значения.
Чертите значения от условного выражения, следующего из .
Запустите сэмплер Гиббса для 20 000 итераций и примените электротермотренировку 5 000. Задать , предварительно выделите для следующих ничьих и инициализируйте к вектору из единиц.
m = 20000; nu = 1; burnin = 5000; lambda = ones(n,m + 1); estBeta = zeros(2,m + 1); estSigma2 = zeros(1,m + 1); for j = 1:m yDef = y./sqrt(lambda(:,j)); xDef = [ones(n,1) x]./sqrt(lambda(:,j)); PriorMdl = bayeslm(2,'Model','diffuse','Intercept',false); [estBeta(:,j + 1),estSigma2(1,j + 1)] = simulate(PriorMdl,xDef,yDef); ep = y - [ones(n,1) x]*estBeta(:,j + 1); sp = (nu + 1)/2; sc = 2./(nu + ep.^2/estSigma2(1,j + 1)); lambda(:,j + 1) = 1./gamrnd(sp,sc); end
Хорошая практика должна диагностировать сэмплер MCMC путем исследования графиков трассировки. Для краткости этот пример пропускает эту задачу.
Вычислите среднее значение ничьих от следующих из коэффициентов регрессии. Удалите электротермотренировку, чертит.
postEstBeta = mean(estBeta(:,(burnin + 1):end),2)
postEstBeta = 2×1
1.3971
1.7051
Оценка точки пересечения ниже, и наклон выше, чем оценки, возвращенные fitlm.
Постройте устойчивую линию регрессии с линией регрессии, адаптированной наименьшими квадратами.
h = gca; xlim = h.XLim'; plotY = [ones(2,1) xlim]*postEstBeta; plot(xlim,plotY,'LineWidth',2); hl.String{4} = 'Robust Bayes';

Подгонка линии регрессии использование устойчивой Байесовой регрессии, кажется, лучшая подгонка.
Максимум по опыту вероятность (MAP), оценка является следующим режимом, то есть, значение параметров, которое дает к максимуму следующей PDF. Если следующее аналитически тяжело, то можно использовать выборку Монте-Карло, чтобы оценить MAP.
Полагайте, что модель линейной регрессии в Симулирует Значение параметров от Предшествующих и Апостериорных распределений.
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для ряда предиктора и ответа.
load Data_NelsonPlosser varNames = {'IPI' 'E' 'WR'}; X = DataTable{:,varNames}; y = DataTable{:,'GNPR'};
Создайте сопряженную предшествующую модель нормальной обратной гаммы для параметров линейной регрессии. Задайте количество предикторов p и имена переменных.
p = 3; PriorMdl = bayeslm(p,'ModelType','conjugate','VarNames',varNames)
PriorMdl =
conjugateblm with properties:
NumPredictors: 3
Intercept: 1
VarNames: {4x1 cell}
Mu: [4x1 double]
V: [4x4 double]
A: 3
B: 1
| Mean Std CI95 Positive Distribution
-----------------------------------------------------------------------------------
Intercept | 0 70.7107 [-141.273, 141.273] 0.500 t (0.00, 57.74^2, 6)
IPI | 0 70.7107 [-141.273, 141.273] 0.500 t (0.00, 57.74^2, 6)
E | 0 70.7107 [-141.273, 141.273] 0.500 t (0.00, 57.74^2, 6)
WR | 0 70.7107 [-141.273, 141.273] 0.500 t (0.00, 57.74^2, 6)
Sigma2 | 0.5000 0.5000 [ 0.138, 1.616] 1.000 IG(3.00, 1)
Оцените крайние апостериорные распределения и .
rng(1); % For reproducibility
PosteriorMdl = estimate(PriorMdl,X,y);Method: Analytic posterior distributions
Number of observations: 62
Number of predictors: 4
Log marginal likelihood: -259.348
| Mean Std CI95 Positive Distribution
-----------------------------------------------------------------------------------
Intercept | -24.2494 8.7821 [-41.514, -6.985] 0.003 t (-24.25, 8.65^2, 68)
IPI | 4.3913 0.1414 [ 4.113, 4.669] 1.000 t (4.39, 0.14^2, 68)
E | 0.0011 0.0003 [ 0.000, 0.002] 1.000 t (0.00, 0.00^2, 68)
WR | 2.4683 0.3490 [ 1.782, 3.154] 1.000 t (2.47, 0.34^2, 68)
Sigma2 | 44.1347 7.8020 [31.427, 61.855] 1.000 IG(34.00, 0.00069)
Отображение включает крайнюю статистику апостериорного распределения.
Извлеките следующее среднее значение из следующей модели и извлечения следующая ковариация из сводных данных оценки, возвращенных summarize.
estBetaMean = PosteriorMdl.Mu;
Summary = summarize(PosteriorMdl);
EstBetaCov = Summary.Covariances{1:(end - 1),1:(end - 1)};estBetaMean 4 1 вектор, представляющий среднее значение крайнего следующего из . EstBetaCov матрица 4 на 4, представляющая ковариационную матрицу следующего из .
Чертите 10 000 значений параметров от апостериорного распределения.
rng(1); % For reproducibility [BetaSim,sigma2Sim] = simulate(PosteriorMdl,'NumDraws',1e5);
BetaSim 4 10,000 матрица случайным образом чертивших коэффициентов регрессии. sigma2Sim 1 10,000 вектор из случайным образом чертивших отклонений воздействия.
Транспонируйте и стандартизируйте матрицу коэффициентов регрессии. Вычислите корреляционную матрицу коэффициентов регрессии.
estBetaStd = sqrt(diag(EstBetaCov)');
BetaSim = BetaSim';
BetaSimStd = (BetaSim - estBetaMean')./estBetaStd;
BetaCorr = corrcov(EstBetaCov);
BetaCorr = (BetaCorr + BetaCorr')/2; % Enforce symmetryПоскольку крайние апостериорные распределения известны, оценивают следующую PDF во всех симулированных значениях.
betaPDF = mvtpdf(BetaSimStd,BetaCorr,68); a = 34; b = 0.00069; igPDF = @(x,ap,bp)1./(gamma(ap).*bp.^ap).*x.^(-ap-1).*exp(-1./(x.*bp));... % Inverse gamma pdf sigma2PDF = igPDF(sigma2Sim,a,b);
Найдите симулированные значения, которые максимизируют соответствующий pdfs, то есть, следующие режимы.
[~,idxMAPBeta] = max(betaPDF); [~,idxMAPSigma2] = max(sigma2PDF); betaMAP = BetaSim(idxMAPBeta,:); sigma2MAP = sigma2Sim(idxMAPSigma2);
betaMAP и sigma2MAP оценки MAP.
Поскольку следующий из является симметричным и одномодовым, следующее среднее значение и MAP должны быть тем же самым. Сравните оценку MAP с его следующим средним значением.
table(betaMAP',PosteriorMdl.Mu,'VariableNames',{'MAP','Mean'},... 'RowNames',PriorMdl.VarNames)
ans=4×2 table
MAP Mean
_________ _________
Intercept -24.559 -24.249
IPI 4.3964 4.3913
E 0.0011389 0.0011202
WR 2.4473 2.4683
Оценки справедливо друг близко к другу.
Оцените аналитический режим следующего из . Сравните его с предполагаемым MAP .
igMode = 1/(b*(a+1))
igMode = 41.4079
sigma2MAP
sigma2MAP = 41.4075
Эти оценки также довольно близки.
simulate не может чертить значения от improper distribution, то есть, распределение, плотность которого не объединяется к 1.
Если Mdl empiricalblm объект модели, затем вы не можете задать Beta или Sigma2. Вы не можете симулировать от условных апостериорных распределений при помощи эмпирического распределения.
Каждый раз, когда simulate должен оценить апостериорное распределение (например, когда Mdl представляет предшествующее распределение, и вы предоставляете X и y) и следующее аналитически послушно, simulate симулирует непосредственно от следующего. В противном случае, simulate обращения к симуляции Монте-Карло, чтобы оценить следующее. Для получения дополнительной информации смотрите Следующую Оценку и Вывод.
Если Mdl объединенная следующая модель, затем simulate симулирует данные из него по-другому по сравнению с когда Mdl объединенная предшествующая модель, и вы предоставляете X и y. Поэтому, если вы устанавливаете тот же случайный seed и генерируете случайные значения оба пути, затем вы не можете получить те же значения. Однако соответствующие эмпирические распределения на основе достаточного числа ничьих эффективно эквивалентны.
Этот рисунок показывает как simulate уменьшает выборку при помощи значений NumDraws, Thin, и BurnIn.
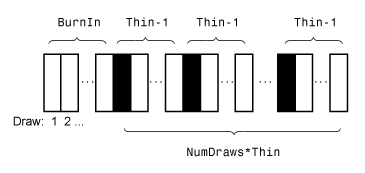
Прямоугольники представляют последовательные ничьи от распределения. simulate удаляет белые прямоугольники из выборки. Остающийся NumDraws черные прямоугольники составляют выборку.
Если Mdl semiconjugateblm объект модели, затем simulate выборки от апостериорного распределения путем применения сэмплера Гиббса.
simulate использует значение по умолчанию Sigma2Start для σ2 и чертит значение β от π (β |σ2x, y .
simulate чертит значение σ2 от π (σ2|β, X, y) при помощи ранее сгенерированного значения β.
Функция повторяет шаги 1 и 2 до сходимости. Чтобы оценить сходимость, постройте график трассировки выборки.
Если вы задаете BetaStartто simulate чертит значение σ2 от π (σ2|β, X, y), чтобы запустить сэмплер Гиббса. simulate не возвращает это сгенерированное значение σ2.
Если Mdl empiricalblm объект модели и вы не предоставляете X и yто simulate чертит от Mdl.BetaDraws и Mdl.Sigma2Draws. Если NumDraws меньше чем или равно numel(Mdl.Sigma2Draws)то simulate возвращает первый NumDraws элементы Mdl.BetaDraws и Mdl.Sigma2Draws как случайные ничьи для соответствующего параметра. В противном случае, simulate случайным образом передискретизирует NumDraws элементы от Mdl.BetaDraws и Mdl.Sigma2Draws.
Если Mdl customblm объект модели, затем simulate использует сэмплер MCMC, чтобы чертить от апостериорного распределения. В каждой итерации программное обеспечение конкатенирует текущие значения коэффициентов регрессии и отклонения воздействия в (Mdl.Intercept + Mdl.NumPredictors + 1) вектор-by-1 и передачи это к Mdl.LogPDF. Значение отклонения воздействия является последним элементом этого вектора.
Сэмплер HMC требует и логарифмической плотности и ее градиента. Градиентом должен быть (NumPredictors+Intercept+1)- 1 вектор. Если производные определенных параметров затрудняют, чтобы вычислить, то, в соответствующих местоположениях градиента, NaN предоставления значения вместо этого. simulate замены NaN значения с числовыми производными.
Если Mdl lassoblm, mixconjugateblm, или mixsemiconjugateblm объект модели и вы предоставляете X и yто simulate выборки от апостериорного распределения путем применения сэмплера Гиббса. Если вы не снабжаете данными, то simulate выборки от аналитических, безусловных предшествующих распределений.
simulate не возвращает начальные значения по умолчанию, которые это генерирует.
Если Mdl mixconjugateblm или mixsemiconjugateblmто simulate чертит от распределения режима сначала, учитывая текущее состояние цепи (значения RegimeStart, BetaStart, и Sigma2Start). Если вы чертите одну выборку и не задаете значения для RegimeStart, BetaStart, и Sigma2Startто simulate использует значения по умолчанию и выдает предупреждение.
conjugateblm | customblm | empiricalblm | semiconjugateblm | diffuseblm | mixconjugateblm | mixsemiconjugateblm | lassoblm