При создании creditscorecard объект, таблица используется для входа data аргумент или задает или не задает наблюдательные веса. Если data не использует веса, затем "количества" для Good, Bad, и Odds используются функциями карты кредитного рейтинга. Однако, если дополнительный WeightsVar аргумент задан при создании creditscorecard объект, затем "количества" для Good, Bad, и Odds сумма весов.
Например, вот отрывок входной таблицы, которая не задает наблюдательные веса:
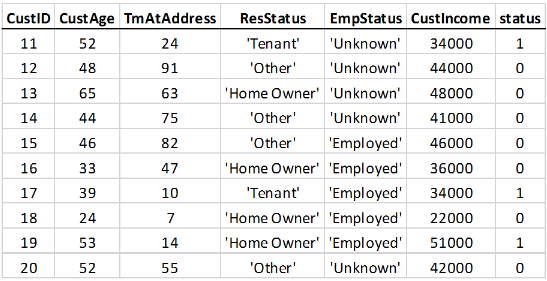
Если вы интервал потребительские данные о предикторе возраста, с клиентами до 45 лет в одном интервале, и 46 и в другом интервале, вы получаете эти статистические данные:
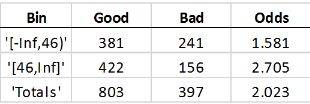
Good означает общее количество строк с 0 значение в status переменная отклика. Bad количество 1в status столбец. Odds отношение Good к Bad. Good, Bad, и Odds сообщается для каждого интервала. Это означает, что существует 381 человек в выборке, которые 45 лет и под тем, кто заплатил их кредиты, 241 в том же возрастном диапазоне, кто принял значение по умолчанию, и поэтому, разногласия того, чтобы быть хорошим для того возрастного диапазона 1.581.
Предположим, что средство моделирования думает, что люди 45 и моложе недостаточно представлены в этой выборке. Средство моделирования хочет дать все строки с возрастами до 45 более высокий вес. Примите, что средство моделирования думает, что у 45 возрастных групп должно быть на 50% больше веса, чем строки с возрастами 46 и. Табличные данные расширены, чтобы включать веса наблюдения. Weight столбец добавляется к таблице, где все строки с возрастами 45 и под имеют вес 1.5, и все другие строки вес 1. Существуют другие причины использовать веса, например, недавним точкам данных можно дать более высокие веса, чем более старые точки данных.
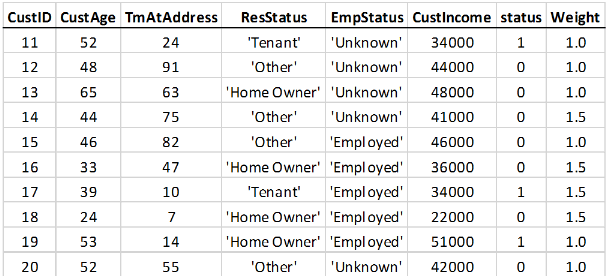
Если вы интервал взвешенные данные на основе возраста (45 и под, по сравнению с 46 и) ожидание состоит в том, что каждая строка с возрастом 45 и под должна рассчитать как 1,5 наблюдения, и поэтому Good и Bad “количества” увеличены на 50%:
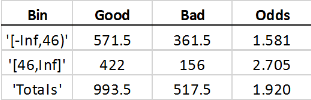
“Количества” являются теперь “взвешенными частотами” и являются более не целочисленными значениями. Odds не изменяйтесь для первого интервала. Конкретные веса, данные в этом примере, оказывают влияние масштабирования общего Good и Bad количества в первом интервале тем же масштабным коэффициентом, поэтому их отношение не изменяется. Однако Odds значение общей выборки действительно изменяется; первый интервал теперь несет более высокий вес, и потому что разногласия в том интервале ниже, общий Odds теперь ниже, также. Другая статистика протокола результатов кредита, не показанная здесь, такая как WOE и Information Value затронуты похожим способом.
В общем случае эффект весов не состоит в том, чтобы просто масштабировать частоты в конкретном интервале, потому что у членов того интервала будут различные веса. Цель этого примера состоит в том, чтобы продемонстрировать концепцию переключения от количеств до суммы весов.
creditscorecard | autobinning | bininfo | fitmodel | validatemodel
