Для эмпирического моделирования механизма в Model Browser сначала загрузите, обработайте и выберите данные для моделирования. Этот пример показывает вам, как использовать Редактор Данных для загрузки данных, создания переменных и создания ограничений для тех данных.
Можно загрузить данные из файлов (Microsoft® Excel® файлы, MATLAB® файлы, текстовые файлы) и от рабочего пространства MATLAB. Можно объединить данные в любой из этих форм с ранее загруженными наборами данных, чтобы произвести новый набор данных. Планы тестирования могут использовать только один набор данных, таким образом, функция слияния позволяет вам комбинировать записи и переменные из различных файлов в одной модели.
Можно задать новые переменные, применить фильтры, чтобы удалить нежелательные данные и применить тестовые примечания к отфильтрованным тестам. Можно сохранить и получить эти пользовательские переменные и фильтры для любого набора данных, и можно сохранить настройки графика. Можно изменить и добавить записи и применить тестовые группировки, и можно совпадать с данными к проектам. Можно также записать собственные функции загрузки данных.
Чтобы начать, выполните эти шаги рабочего процесса.
Шаги рабочего процесса | Описание |
|---|---|
Используйте Редактор Данных отображения, чтобы исследовать ваши данные. | |
Задайте свои собственные новые переменные и фильтры, чтобы удалить нежелательные данные. | |
Сохраните и импортируйте переменные, фильтры, и постройте настройки | Сохраните настройки графика, пользовательские переменные, фильтры, и протестируйте примечания. |
Используйте диалоговое окно Define Test Groupings, чтобы сгруппировать ваши данные. | |
Используйте проект в качестве примера совпадать с экспериментальными данными к проектам. |
Можно разделить представления, чтобы отобразить несколько графиков целиком. Используйте контекстные меню щелчка правой кнопкой, кнопки на панели инструментов или меню View, чтобы разделить представления. Можно выбрать 2D графики, 3-D графики, несколько графиков данных, таблиц данных и вкладок, показывающих сводные данные, статистику, переменные, фильтры, тестовые фильтры, и протестировать примечания. Можно использовать тестовые примечания, чтобы исследовать проблемные данные и решить, удалить ли некоторые точки перед моделированием.
Щелкните правой кнопкой по представлению и выберите Current View> Multiple Data Plot.
Щелкните правой кнопкой по новому представлению и выберите Add Plot.
Диалоговое окно Plot Variables Setup появляется.
Выберите spark и щелкните, чтобы добавить к X Variable поле, затем выберите tq и щелкните, чтобы добавить к Y Variable поле. Нажмите OK, чтобы создать график.
Щелкните в списке Tests, чтобы выбрать тест, чтобы построить (или Shift - нажатие кнопки, Ctrl - нажатие кнопки или перетаскивание, чтобы выбрать несколько тестов).
Выберите Tools> Test Notes.
В Тестовом Редакторе Примечания введите mean(tq)<10 в главном окне редактирования, чтобы задать тесты, которые будут отмечены, и вводят Low torque в окне редактирования Test Note. Оставьте цвет примечания в значении по умолчанию и нажмите OK.
Кликните по вкладке Test Notes, чтобы просмотреть ваше определение примечания.
В Тестовой панели Селектора слева, заметьте, что все тесты, которые удовлетворяют условию mean(tq)<10 покажите Low torque рядом с ними. Кликните по заголовку столбца, чтобы отсортировать тесты, которые удовлетворяют условию примечания к верхней части или нижней части списка.
Теперь создайте больше представлений.
Щелкните правой кнопкой по представлению и выберите Split View> Data Table.
Щелкните правой кнопкой по представлению и выберите Split View> 3D Plot.
В Тестовой панели Селектора кликните по конкретным тестам с Low torque примечание.
Заметьте, что, когда вы выбираете тест здесь, тот же тест построен в нескольких графиках данных, 3D графике данных, и подсвечен в таблице данных. Можно использовать примечания таким образом, чтобы легко идентифицировать проблемные тесты и решить, удалить ли их.
Кликните по точке на представлении Multiple Data Plots.
Точка обрисована в общих чертах в красном на графике и подсвечена в таблице данных. Можно удалить точки, которые вы выбрали как выбросы путем выбора Tools> Remove Data (или используйте горячую клавишу Ctrl +A). Выберите Tools> Restore Data (или используйте горячую клавишу Ctrl +Z) открыть диалоговое окно, где можно принять решение восстановить любые удаленные точки.
Можно удалить отдельные точки как выбросы, или можно удалить записи или целые тесты с фильтрами.
Например, после исследования всего Low torque отмеченные тесты, вы могли решить фильтровать их.
Выберите Tools> Test Filters.
В Тестовом Редакторе Фильтра введите mean(tq)>10 сохранить все тесты, где средний крутящий момент больше 10 и нажимает OK.
Кликните по вкладке Test Filters и заметьте, что новые тестовые результаты фильтра показывают, что она успешно применяется, и количество записей удалено.
Чтобы просмотреть удаленные данные в табличном представлении, щелкните правой кнопкой и выберите Allow Editing. Удаленные записи являются красными. Чтобы просмотреть удаленные данные в 2D и Нескольких Графиках данных, выберите Properties и выберите поле Show removed data.
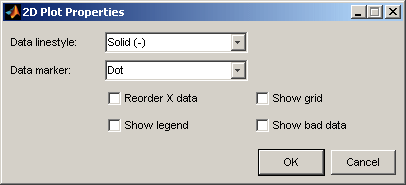
Чтобы изменить отображение, щелкните правой кнопкой по 2D графику и выберите Properties. Можно изменить сетку и построить настройки включая графики, чтобы соединить точки данных.
Reorder X Data в диалоговом окне Plot Properties может быть полезным, когда порядок записи не продолжает разумную линию, соединяющую точки данных. Для рисунка этого:
Убедитесь, что вы отображаете 2D график. Можно щелкнуть правой кнопкой по любому графику и выбрать Current Plot> 2-D Plot, или использовать команды разделения контекстного меню, чтобы добавить новые представления.
Щелкните правой кнопкой по 2D графику и выберите Properties и выберите solid от Data Linestyle выпадающее меню. Нажмите OK.
Выберите afr для оси Y.
Выберите Load для оси X.
Выберите тест 590. Используйте тестовые средства управления, содержавшие в рамках 2D графика. Панель Tests слева применяется к другим представлениям: таблицы и 3-D и несколько графиков данных.

Щелкните правой кнопкой и выберите Properties и выберите Reorder X Data. Нажмите OK.
Эта команда повторно строит линию слева направо вместо в порядке записей, как показано.
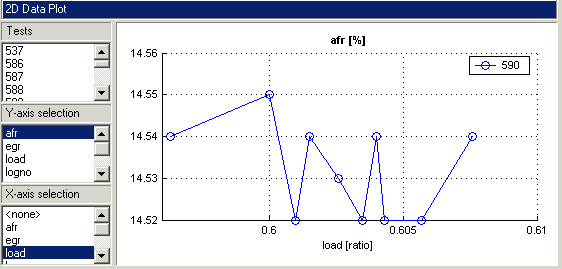
Щелкните правой кнопкой и выберите Split Plot> Data Table, чтобы разделить в настоящее время выбранное представление и добавить табличное представление. Можно выбрать конкретные тестовые числа в панели Tests слева от Редактора Данных. Можно щелкнуть правой кнопкой, чтобы выбрать Allow Editing, и затем можно дважды кликнуть ячейки, чтобы отредактировать их.
Можно добавить новые переменные в набор данных.
Выберите Tools> Variables или нажмите кнопку на панели инструментов.
В Редакторе переменных можно задать новые переменные в терминах существующих переменных. Задайте новую переменную путем записи уравнения в окне редактирования наверху.
Задайте новую переменную под названием POWER это задано как продукт двух существующих переменных, tq и n, путем ввода POWER=tq*n, как замечено в примере после. Можно также дважды кликнуть имена переменных и операторы, чтобы добавить их, которые могут быть полезными, чтобы не вводить ошибки в именах переменных, которые должны быть точными включая случай.
Нажмите OK, чтобы добавить эту переменную в текущий набор данных.
Просмотрите новую переменную в Редакторе Данных во вкладке Variables наверху. Можно также теперь видеть 7 + 1 variables в итоговой вкладке.
Фильтр является ограничением на набор данных, который можно использовать, чтобы исключить некоторые записи. Вы используете Редактор Фильтра, чтобы создать фильтры.
Выберите Tools> Filters или нажмите кнопку на панели инструментов.
В Редакторе Фильтра задайте фильтр с помощью логических операторов на существующих переменных.
Ведите весь учет со скоростью (n) больше, чем 1 000. Введите n (или дважды кликните переменную n), затем введите >1000.
Нажмите OK, чтобы наложить этот фильтр на текущий набор данных.
Просмотрите новый фильтр в Редакторе Данных во вкладке Filters наверху. Здесь вы видите список своих пользовательских фильтров и сколько записей новый фильтр удаляет. Можно также теперь видеть 141/270 records в итоговой вкладке и красном разделе в панели, иллюстрирующей записи, удален фильтром.
Можно изменить порядок пользовательских переменных в списке Редакторов переменных с помощью кнопок стрелки вверх и вниз.
Выберите Tools> Variables.
Пример:
Задайте две новых переменные, New1 и New2. Можно использовать кнопки, чтобы добавить или удалить элемент списка, чтобы создать или удалить переменные в этом представлении. Нажмите кнопку к тому, 'Добавьте элемент', чтобы добавить переменную и введите показанные определения.
Заметьте, что New2 задан в терминах New1. Новые переменные добавляются к данным в свою очередь и следовательно New1 должен появиться в списке перед New2, в противном случае New2 не четко определено.
Измените порядок путем нажатия на стрелку вниз в Редакторе переменных, чтобы произвести эту ошибочную ситуацию. Нажмите OK, чтобы возвратиться к Редактору Данных, и во вкладке Variables вы видите сообщение об ошибке, что существует проблема с переменной.
Используйте стрелы, чтобы заказать пользовательские переменные в законной последовательности.
Можно удалить пользовательские переменные и фильтры.
Пример:
Удалить добавленную переменную New1, выберите его во вкладке Variables и нажмите клавишу Delete.
Можно также удалить переменные в Редакторе переменных путем нажатия кнопки Remove Item.
Точно так же можно удалить фильтры путем выбора нежелательного фильтра во вкладке Filters и использования ключа Delete.
Можно сохранить и импортировать настройки графика, пользовательские переменные, фильтры, и протестировать примечания, таким образом, они могут быть применены к другим наборам данных, загруженным позднее на сеансе, и к другим сеансам.
Выберите Tools> Import Expressions
Нажмите кнопку на панели инструментов ![]()
Редактор Данных помнит ваши настройки типа графика и когда вновь открытые отображения те же типы представлений. Можно также сохранить размещения графика, чтобы сохранить детали Нескольких Графиков данных.
В Переменных Импорта Фильтры и диалоговое окно Editor Layout, используют кнопки на панели инструментов, чтобы импортировать переменные, фильтры и размещения графика. Импортируйте из других наборов данных в текущем проекте, или из файлов проекта MBC, или из файлов, экспортируемых из Редактора Данных.
Чтобы использовать импортированные выражения в вашем текущем проекте, выберите элементы в списках и нажмите кнопку на панели инструментов, чтобы применяться в редакторе данных.
Чтобы сохранить выражения в файле, в Редакторе Данных, выбирают Tools> Export Expressions и выбирают имя файла.
Диалоговое окно Define Test Groupings собирает записи текущего объекта данных в группы. Эти группы упоминаются как тесты.
К диалоговому окну получают доступ из Редактора Данных любым из этих способов:
Используя меню Tools> Test Groups
Используя кнопку на панели инструментов ![]()
При вводе диалоговое окно с помощью holliday данные, график отображен как переменная logno автоматически выбран для группировки тестов.
Выберите другую переменную, чтобы использовать в определении групп в данных.
Выберите n в списке Variables.
Нажмите ![]() кнопку, чтобы добавить переменную (или дважды кликать
кнопку, чтобы добавить переменную (или дважды кликать n).
Переменная n появляется в представлении списка слева. Можно теперь использовать эту переменную, чтобы задать группы в данных. Максимальные и минимальные значения n отображены. Tolerance используется, чтобы задать группы: при прочтении данных, когда значение n изменения больше, чем допуск, новая группа задана. Вы изменяете Tolerance путем ввода непосредственно в окне редактирования.
Можно задать дополнительные группы путем выбора другой переменной и выбора допуска. Записи данных сгруппированы n или этим дополнительным изменением переменной вне их допусков.
Очистите поле Group by для logno. Заметьте, что переменные могут быть построены, не используясь задавать группы.
Добавьте load к списку путем выбора его справа и нажатию ![]() .
.
Измените load допуск к 0,01 и смотрит тестовое изменение группировки в графике.
Снимите флажок Group By для load. Теперь эта переменная построена, не используясь задавать группы.
График показывает масштабированные значения всех переменных в представлении списка (цвет текста допуска соответствует цвету точек данных в графике). Вертикальные розовые панели показывают тесты (группы). Можно масштабировать график Shift - перетаскивание нажатия кнопки или перетаскивание щелчка средней кнопкой мышь; уменьшите масштаб снова путем двойного клика.
Выберите load в представлении списка (это становится подсвеченным в синем) и удаляют его из списка путем нажатия ![]() кнопки.
кнопки.
Дважды кликните, чтобы добавить spark к списку, и снимают флажок Group By. Выберите logno как единственная сгруппированная переменная.
Может быть полезно построить переменную локальной модели (в этой искре случая), чтобы проверять, что у вас есть правильные тестовые группировки. График показывает развертки значений искры в каждом тесте, в то время как скорость (n) сохранена постоянной. Скорость только изменяется между тестами, таким образом, это - глобальная переменная. Попытайтесь увеличить масштаб графика смотреть тестовые группы; дважды кликните, чтобы сбросить.
One-stage data задает один тест на запись, независимо от любой другой группировки. Это требуется, если данные должны использоваться в создании одноэтапных моделей.
Sort records before grouping позволяет вам переупорядочивать записи в наборе данных. В противном случае группы заданы с помощью порядка записей в исходном объекте данных.
Show original test groups отображает исходные тестовые группировки, если кто-либо был задан.
Test number variable содержит список всех переменных в текущем наборе данных. Любой из них мог быть выбран, чтобы пронумеровать тесты.
убедитесь тот logno выбран для Test number variable.
Это изменяется, как тесты отображены в остальной части Model Browser. Тестовый номер может быть полезной переменной для идентификации отдельных тестов в Редакторе Model Browser и Данных представления (вместо 1,2,3...), если данные были взяты в пронумерованных тестах, и вы хотите получить доступ к той информации во время моделирования.
Если вы выбрали none из списка Test number variable тесты были бы пронумерованы 1,2,3, и так далее, в порядке, в котором записи появляются в файле данных. С logno выбранный, вы видите тесты в Редакторе Данных, перечисленном как 586, 587 и т.д.
Каждая запись в тесте должна совместно использовать тот же тестовый номер, чтобы идентифицировать его, поэтому когда вы используете переменную, чтобы пронумеровать тесты, значение той переменной принято в первой записи в каждом тесте.
Тестовые числа должны быть уникальными, поэтому если какие-либо значения в выбранной переменной являются тем же самым, им присваивают новые тестовые номера в целях моделирования (это не изменяет базовые данные, которые сохраняют правильный тестовый номер или другую переменную).
Нажмите OK, чтобы принять тестовые заданные группировки и закрыть диалоговое окно.
В Редакторе Данных итоговая вкладка просмотрите количество тестов.
Количество записей показывает количество оставленных значений (после фильтрации) каждой переменной в этом наборе данных, сопровождаемом исходным количеством записей. Цвет закодировал панели, также отображают количество записей, удаленных как пропорция общего количества. Значения собраны в несколько тестов; этот номер также отображен. Переменные показывают исходное количество переменных плюс пользовательские переменные.
Можно использовать проект в качестве примера проиллюстрировать процесс соответствия с экспериментальными данными к проектам.
Экспериментальные данные вряд ли будут идентичны желаемым точкам проекта. Можно использовать представление Design Match в Редакторе Данных, чтобы сравнить фактические данные, собранные с точками экспериментального плана. Здесь можно выбрать данные для моделирования. Если вы интересуетесь сбором большего количества данных, можно обновить экспериментальный план путем соответствия с данными, чтобы спроектировать точки, чтобы отразить фактические собранные данные. Можно затем оптимально увеличить проект (использующий Design Editor), чтобы решить, какие точки данных было бы самым полезным собрать, на основе данных, полученных до сих пор.
Можно использовать итеративный процесс: сделайте проект, соберите некоторые данные, соответствие, что данные с вашими точками проекта, измените свой проект соответственно, затем соберите больше данных и так далее. Можно использовать этот процесс, чтобы оптимизировать процесс сбора данных, чтобы получить большинство устойчивых моделей, возможных с минимальным количеством данных.
Чтобы видеть, что данные совпадают с функциями в Model Browser, выбирают File> Open Project и обзор к файлу Data_Matching.mat в matlab\toolbox\mbc\mbctraining папка.
Нажмите Spark Sweeps узел в дереве модели, чтобы превратиться в представление плана тестирования.
Здесь вы видите план тестирования 2D этапа с типами модели и настроенными входными параметрами. Глобальная модель имеет связанный экспериментальный план (который вы могли просмотреть в Design Editor). Вы собираетесь использовать Редактор Данных, чтобы исследовать, как тесно данные, собранные до сих пор, соответствуют к экспериментальному плану.
Нажмите Edit Data button ( ![]() ) на панели инструментов.
) на панели инструментов.
Редактор Данных появляется.
Вам нужно представление Design Match, чтобы исследовать проект и точки данных. Щелкните правой кнопкой по представлению по Редактору Данных и выберите Current View> Design Match.
В Соответствии Проекта вы видите, что цветные области содержат точки. Это “кластеры”, где соответствующий алгоритм выбирает тесно соответствие с проектом и точками данных.
Значения допуска (выведенный первоначально из пропорции областей значений переменных) используются, чтобы определить, лежат ли какие-либо точки данных в допуске каждой точки проекта. Точки данных, которые лежат в допуске любой точки проекта, являются соответствующими к тому кластеру. Точки данных, которые падают в допуске больше чем одной точки проекта, формируют один кластер, содержащий все, что те проектируют и точки данных. Если никакие точки данных не лежат в допуске точки проекта, это остается несопоставленным, и никакой кластер не построен.
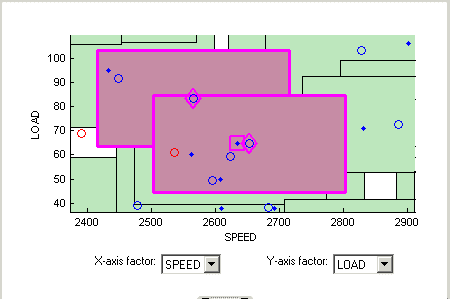
Заметьте форму, сформированную перекрывающимися кластерами. Примером, показанным обрисованным в общих чертах в розовом, является один кластер, сформированный, где точка данных находится в допуске двух точек проекта.
На этом графике вы видите другие очищенные точки, которые, кажется, содержатся в этом кластере. Вы отслеживаете точки через другие факторные размерности с помощью средств управления осью, чтобы видеть, где точки разделяются вне допуска.
Чтобы отредактировать значения допуска, выберите Tolerances в контекстном меню.
Редактор Допуска появляется. Здесь можно изменить размер кластеров в каждой размерности. Заметьте что LOAD значение допуска равняется 100. Это составляет удлиненную форму (в LOAD размерность) кластеров в текущем графике, потому что это значение допуска является высоким процентом общей области значений этой переменной.
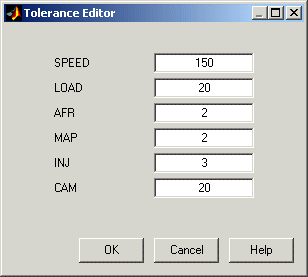
Кликните по окну редактирования LOAD и введите 20, как показано. Нажмите OK.
Заметьте изменение в форме кластеров в представлении Design Match.
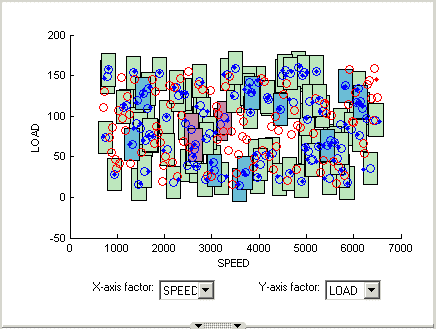
Щелкните при нажатой клавише Shift (центральное нажатие кнопки) и перетащите, чтобы увеличить масштаб области графика, как показано. Можно дважды кликнуть, чтобы возвратиться к полноразмерному графику.
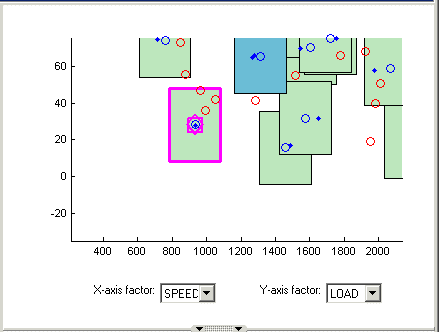
Кликните по кластеру, чтобы выбрать его. Выбранные точки или кластеры обрисованы в общих чертах в розовом. Если вы кликаете и содержите, можно смотреть значения глобальных переменных в выбранных точках (или для всех данных и спроектировать точки, если вы кликаете по кластеру). Можно использовать эту информацию, чтобы помочь вам выбрать подходящие значения допуска, если вы пробуете к матч-пойнтам.
Заметьте, что список Cluster Information показывает детали всех данных и точек проекта, содержавшихся в выбранном кластере. Вы используете флажки здесь, чтобы выбрать или исключить точки проекта или данные. Кликните по различным кластерам, чтобы видеть различные точки. Список показывает значения глобальных переменных в каждой точке, и какие данные и точки проекта в допуске друг друга. Ваши выборы здесь определяют, какие данные использовать для моделирования, и которые проектируют точки, заменяются фактическими точками данных.
Если вы не интересуетесь сбором большего количества данных, то нет никакой потребности убедиться, что проект изменяется, чтобы отразить фактические данные.
Однако, если вы хотите свой новый проект (названный Actual Design) чтобы точно отразиться, какие данные были получены до сих пор, например, чтобы собрать больше данных, затем кластер, соответствующий, важен. Все точки данных с установленным флажком добавляются к новому Actual Design, кроме тех в красных кластерах. Цвет кластеров указывает на то, какую пропорцию выбранных точек он содержит можно следующим образом:
Зеленые кластеры имеют равные количества выбранного проекта и выбранных точек данных. Точки данных заменят точки проекта в Actual Design.
Пропорция выбранных точек определяет цвет; исключенные точки (со снятыми флажками) не оказывают влияния. Ваши выборы флажка могут изменить кластерный цвет.
Синие кластеры имеют больше точек данных, чем точки проекта. Все точки данных заменят точки проекта в Actual Design.
Красные кластеры имеют больше точек проекта, чем точки данных. Эти точки данных не будут добавлены к вашему проекту, когда алгоритм не может выбрать, какой проект указывает на замену, таким образом, необходимо вручную сделать выборы, чтобы иметь дело с красными кластерами, если вы хотите использовать эти точки данных в своем проекте.
Если вы не заботитесь о Actual Design (например, если вы не намереваетесь собрать больше данных), и вы только выбираете данные для моделирования, затем можно проигнорировать красные кластеры. Точки данных в красных кластерах выбраны для моделирования.
Щелкните правой кнопкой по Design Match и выберите Select Unmatched Data. Заметьте, что остающиеся несопоставленные точки данных появляются в списке. Здесь можно использовать флажки, чтобы выбрать или исключить несопоставленные данные таким же образом как точки в кластерах.
Выберите кластер, затем используйте выпадающее меню, чтобы изменить Y-Axis factor в INJ. Наблюдайте выбранный кластер, теперь построенный в новых факторных размерностях SPEED и INJ.
Можно использовать этот метод, чтобы отследить точки и кластеры через размерности. Это может дать вам хорошую идею который допуски измениться, чтобы заработать очки соответствующее. Помните, что указывает, что не формируются, кластерная сила, кажется, являются отлично соответствующими, когда просматривается в одной паре размерностей; необходимо просмотреть их в других размерностях, чтобы узнать, где они разделяются вне значения допуска. Можно использовать этот процесс отслеживания, чтобы решить, хотите ли вы, чтобы конкретные пары точек были соответствующими, и затем изменили допуски, пока они не являются частью кластера.
Снимите флажок Equal Data and Design в представлении Design Match. Вы управляете тем, что построено с помощью этих флажков.
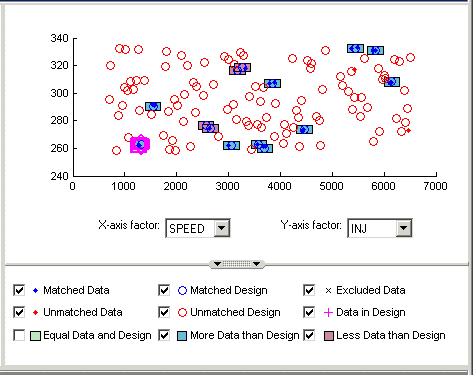
Это удаляет зеленые кластеры из представления, как показано. Эти кластеры являются соответствующими; вы, более вероятно, будете интересоваться несопоставленными точками и кластерами с неровными количествами данных и проектировать точки. Удаление зеленых кластеров позволяет вам фокусироваться на этих интересных местах. Если вы хотите свой новый Actual Design чтобы точно отразить ваши текущие данные, ваша цель состоит в том, чтобы получить как можно больше точек данных, подошедших, чтобы спроектировать точки; то есть, как можно меньше красных кластеров.
Снимите флажок для More Data than Design. Вы можете также решить проигнорировать синие кластеры, которые содержат больше точек данных, чем точки проекта. Эти точки проекта заменяются всеми точками данных в кластере. Избыток точек данных вряд ли будет беспокойством.
Однако синие кластеры могут указать, что была проблема со сбором данных в той точке, и вы можете хотеть заняться расследованиями, почему, чем ожидалось было собрано больше точек.
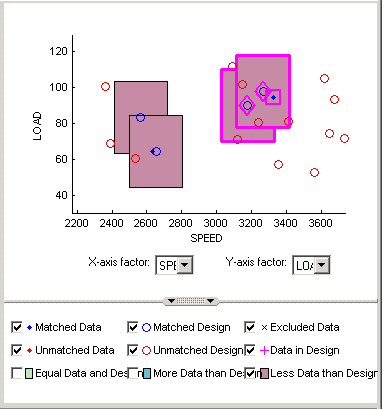
Выберите один из остающихся красных кластеров. Оба из них имеют две точки проекта в допуске одной точки данных.
Выберите один из проекта указывает, чтобы соответствовать к точке данных, затем снять флажок другой точки проекта. Очищенная точка проекта остается неизменной в проекте. Выбранная точка проекта заменяется точкой согласованных данных.
Заметьте, что красный кластер исчезает. Это вызвано тем, что ваши результаты выбора в кластере с равным количеством выбранных данных и точек проекта (зеленый кластер) и ваш текущий график не отображают зеленые кластеры.
Повторитесь для другого красного кластера.
Теперь все кластеры являются зелеными или синими. Существует две остающихся несопоставленных точки данных.
Снимите флажок Unmatched Design, чтобы определить местоположение несопоставленных точек данных. Установите флажок Unmatched Design снова — чтобы видеть, что проект указывает, чтобы решить, достаточно ли кто-либо близок к точкам данных.
Найдите и увеличьте масштаб несопоставленной точки данных. Выберите несопоставленную точку данных и соседнюю точку проекта путем нажатия, затем используйте ось выпадающие меню, чтобы отследить пару кандидата через размерности. Решите, достаточно ли какие-либо точки проекта близки, чтобы гарантировать изменение значений допуска, чтобы совпадать с точкой с точкой проекта.
Вспомните, что можно щелкнуть правой кнопкой по Design Match и выбрать Select Unmatched Data, чтобы отобразить остающиеся несопоставленные точки данных в списке Cluster Information. Здесь можно использовать флажки, чтобы выбрать или исключить эти точки. Если вы оставляете их выбранными, они добавляются к Actual Design.
Эти шаги иллюстрируют процесс соответствия с данными к проектам, чтобы выбрать данные о моделировании и увеличить ваш проект на основе фактических полученных данных. Некоторый метод проб и ошибок необходим, чтобы найти полезные значения допуска. Можно выбрать точки и изменить размерности графика, чтобы помочь вам найти подходящие значения. Если вы хотите свой новый Actual Design чтобы точно отразить ваши экспериментальные данные, необходимо сделать выбор, чтобы иметь дело с красными кластерами. Выберите, какой проект указывает в красных кластерах, которые вы хотите заменить на точки данных. Если вы не сделаете, то эти точки данных не будут добавлены к новому проекту.
Когда вам удовлетворяют, что вы выбрали все данные, вы хотите для моделирования, закрываете Редактор Данных. На данном этапе ваш выбор в представлении Design Match применяется к набору данных и новому проекту под названием Actual Design создается.
Все точки данных с установленным флажком выбраны для моделирования. Точки данных со снятыми флажками исключены из набора данных. Изменения внесены в существующий проект, чтобы произвести новый Actual Design. Все выбранные данные добавляются к вашему новому проекту, кроме тех в красных кластерах. Выбранные точки данных, которые были соответствующими, чтобы спроектировать точки (в зеленых и синих кластерах) заменяют те точки проекта.
Все эти выбранные точки данных становятся фиксированными точками проекта (красный в Design Editor) и появляются как Data in Design (розовые кресты), когда вы вновь открыли Редактор Данных.
Это означает, что эти точки не будут включены в кластеры при соответствии снова. Эти фиксированные точки не будут также изменены в Design Editor, когда вы добавите точки, хотя можно разблокировать фиксированные точки, если вы хотите. Это может быть полезно, если вы хотите оптимально увеличить проект, учитывая данные вы уже получили.
