Используйте Пошаговые функции, чтобы помочь вам искать хорошую подгонку модели. Цель пошагового поиска состоит в том, чтобы минимизировать НАЖАТИЕ. Минимизация Предсказанной Ошибочной Суммы квадратов (НАЖАТИЕ) является хорошим методом для работы к модели регрессии, которая предусматривает хорошую прогнозирующую возможность по экспериментальному факторному пробелу. Смотрите статистическую величину НАЖАТИЯ.
Использование НАЖАТИЯ является ключевым показателем прогнозирующего качества модели. Предсказанная ошибка использует предсказания, вычисленные, не используя наблюдаемую величину для того наблюдения. НАЖАТИЕ известно как Delete-1 статистика в продукте Statistics and Machine Learning Toolbox™. См. также Модели 2D Этапа для Механизмов.
Можно выбрать автоматический пошагово во время настройки модели или ручного управления с помощью окна Stepwise.
Используйте меню Stepwise в диалоговых окнах Model Setup, чтобы запуститься пошагово автоматически при создавании линейных моделей.
Откройте окно ступенчатой регрессии через![]() значок панели инструментов, когда вы будете в представлении глобального уровня. Инструмент Stepwise предоставляет много методов выбора терминов модели, которые должны быть включены.
значок панели инструментов, когда вы будете в представлении глобального уровня. Инструмент Stepwise предоставляет много методов выбора терминов модели, которые должны быть включены.
Можно установить Минимизировать НАЖАТИЕ, Вперед, и Обратные стандартные программы выбора запускаться автоматически без потребности ввести пошаговую фигуру.
Можно установить эти опции в диалоговом окне Model Setup, когда вы первоначально настраиваете свой план тестирования, или от глобального уровня можно следующим образом:
Выберите Model> Set Up.
Диалоговое окно Global Model Setup имеет выпадающее меню Stepwise с опциями None, Minimize PRESS, Forward selection, и Backward selection.
Используйте пошаговые кнопки в нижней части окна (также доступный в меню Regression) можно следующим образом:
Нажмите Min. PRESS (пометил 1 в следующем рисунке) автоматически включать или удалить термины, чтобы минимизировать НАЖАТИЕ. Эта процедура предоставляет модели улучшенную прогнозирующую возможность.
Члены в модели Include All (кроме терминов, отмеченных с помощью Status как Never). Эта опция полезна в сочетании с Min. PRESS и обратным выбором. Например, сначала нажмите Include All, затем Min. PRESS. Затем можно нажать Include All снова, затем Backwards, чтобы выдержать сравнение, который дает лучший результат.
Члены в модели Remove All (кроме терминов, отмеченных с помощью Status как Always). Эта опция полезна в сочетании с прямым выбором (нажмите Remove All, затем Forwards).
Выбор Forwards добавляет все термины в модель, которая привела бы к статистически значительным терминам в ![]()
% уровень (см. Шаг 4 для альфы). Сложение терминов повторяется, пока все члены в модели не статистически значительные.

Выбор Backwards удаляет все термины из модели, которые не являются статистически значительными на ![]() уровне %. Удаление терминов повторяется, пока все члены в модели не статистически значительные.
уровне %. Удаление терминов повторяется, пока все члены в модели не статистически значительные.
Условия могут быть также быть вручную включенными или удаленными из модели путем нажатия на Термин, Затем НАЖАТЬ, или содействующая линия значения погрешности (пометил 2 в следующем рисунке).
Доверительные интервалы для всех коэффициентов показывают справа от таблицы. Обратите внимание на то, что интервал для постоянного термина не отображен, когда значение этого коэффициента часто значительно больше, чем другие коэффициенты.
Условия, которые в настоящее время не включены в модель, отображены в красном. См. Пошаговую Таблицу для значения заголовков столбцов.

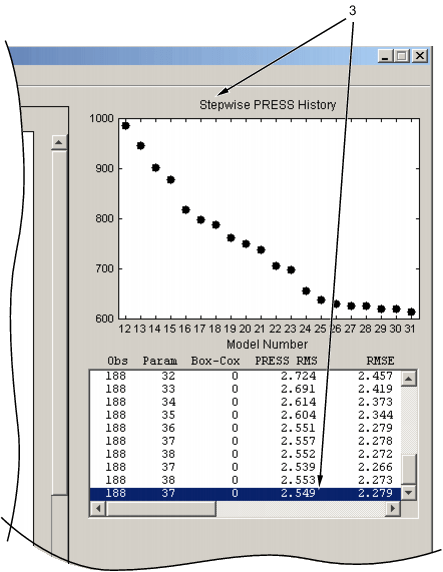
Историю НАЖАТИЯ и итоговой статистики показывают справа от пошаговой фигуры. Можно возвратиться к предыдущей модели путем нажатия на элемент в поле списка, или точка на Пошаговом НАЖИМАЮТ, график History (пометил 3 в следующем рисунке).
Критические значения для тестирования, отличается ли коэффициент статистически от нуля в ![]()
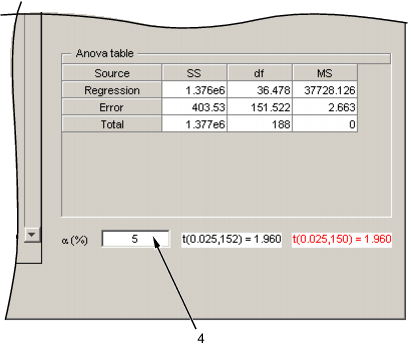
% уровень отображен в правой нижней стороне пошаговой фигуры. Можно войти, значение![]() в окне редактирования (пометил 4 в следующем рисунке) слева от критических значений. Значение по умолчанию составляет 5%. Таблицу ANOVA показывают для текущей модели.
в окне редактирования (пометил 4 в следующем рисунке) слева от критических значений. Значение по умолчанию составляет 5%. Таблицу ANOVA показывают для текущей модели.
Любые изменения, внесенные в пошаговой фигуре автоматически, обновляют диагностические графики в Model Browser.
Можно вернуться к стартовой модели при закрытии окна Stepwise. Когда вы выходите из окна Stepwise, диалоговое окно Confirm Stepwise Exit спрашивает Do you want to update regression results? Можно нажать Yes (значение по умолчанию), No (чтобы вернуться к стартовой модели), или Cancel (чтобы возвратиться к окну Stepwise).
Пошаговая таблица
| Термин | Пометьте для коэффициента |
|---|---|
Состояние | Всегда. Пошагово не удаляет этот термин. Никогда. Пошагово не добавляет этот термин. Шаг. Пошагово рассматривает этот член для сложения или удаления. |
B | Значение коэффициента. То, когда термин не находится в модели значение коэффициента, если это добавляется к модели, отображено в красном. |
stdB | Стандартная погрешность коэффициента. |
t | t значение, чтобы протестировать, отличается ли коэффициент статистически от нуля. T значение подсвечено в синем, если это меньше критического значения, заданного в |
Затем НАЖМИТЕ | Значение НАЖАТИЯ, если включение или исключение этого термина изменяются в следующей итерации. Желтая выделенная ячейка указывает на следующий рекомендуемый термин, чтобы измениться. Включая или, исключая подсвеченный термин (в зависимости от его текущего состояния) приведет к самому большому сокращению значения НАЖАТИЯ. Если нет никакого желтого выделения, что это означает, что значение НАЖАТИЯ уже минимизировано. Если существует желтая ячейка, заголовок столбца является также желтым, чтобы предупредить вас, что вы могли внести изменение, чтобы достигнуть меньшего значения НАЖАТИЯ. Заголовок столбца подсвечен, потому что вы, возможно, должны прокрутить, чтобы найти желтую ячейку. |
Предыдущая таблица описывает значения заголовков столбцов в окне Stepwise Regression.
Если вы настроили модель, необходимо создать несколько альтернативных моделей, использовать Пошаговые функции и исследовать диагностическую статистику, чтобы искать хорошую подгонку модели. Для каждой функции ответа,
Начните путем проведения пошагового поиска.
Можно сделать это автоматически или при помощи окна Stepwise.
Цель пошагового поиска состоит в том, чтобы минимизировать НАЖАТИЕ. Обычно не одна но несколько моделей кандидата на функции ответа возникают, каждый с очень похожим НАЖИМАЕТ R2. Прогнозирующая поддержка модели с НАЖАТЬ R2 из 0,91 не может быть принят выше ни в каком значимом техническом смысле к модели с НАЖАТЬ R2 из 0,909. Далее, природа процесса построения моделей - то, что “улучшение” НАЖИМАЕТ R2 предлагаемый последними несколькими терминами часто очень мал. Следовательно, несколько моделей кандидата могут возникнуть. Вы можете сохранить каждую из моделей кандидата и сопоставили диагностическую информацию отдельно для последующего анализа. Сделайте это путем делания выбора дочерних узлов для функции ответа.
Однако опыт показал что модель с НАЖАТЬ R2 из меньше чем 0,8, скажем, мало полезно как прогнозирующий инструмент для целей отображения механизма. Этот критерий должен быть просмотрен с осторожностью. Низко НАЖМИТЕ R2 значения могут следовать из плохого выбора исходных факторов, но также и от присутствия отдаленных или влиятельных точек в наборе данных. Вместо доверия НАЖИМАЮТ R2 один, более безопасная стратегия состоит в том, чтобы изучить диагностическую информацию модели, чтобы различить природу любых основных проблем и затем принять соответствующие меры по ликвидации последствий.
Если пошаговый процесс завершен, диагностические данные должны быть рассмотрены для каждой модели кандидата.
Может случиться так, что одни только эти данные достаточны обеспечить средние значения выбора одной модели. Это имело бы место, если бы одна модель ясно предоставила более идеальное поведение, чем другие. Помните, что интерпретация диагностических графиков субъективна.
Необходимо также удалить отдаленные данные на данном этапе. Можно установить критерии обнаружения отдаленных данных. Критерий по умолчанию является любым случаем, где абсолютное значение внешней studentized невязки больше 3.
После удаления отдаленных данных продолжите процесс построения моделей в попытке удалить дальнейшие термины.
Старшие термины могут быть сохранены в модели в попытке следовать за отдаленными данными. Даже после удаления отдаленных данных, нет никакой гарантии, что диагностические данные предположат, что подходящая модель кандидата была найдена. При этих обстоятельствах,
Преобразование функции ответа может оказаться выгодным.
Полезный набор преобразований обеспечивается Полем и семейством Cox, смотрите Преобразование Cox Поля. Обратите внимание на то, что алгоритм Cox Поля является моделью, зависимой, и как таковой всегда выполняется с помощью матрицы регрессии (Nxq) X.
После того, как вы выбираете преобразование, необходимо повторить, что пошаговое НАЖАТИЕ ищет и выбирает подходящее подмножество моделей кандидата.
После этого необходимо анализировать соответствующие диагностические данные для каждой модели.
Не может быть очевидно, почему исходный пошаговый поиск был выполнен в естественной метрике. Почему бы не переходить непосредственно к взятию преобразования? Это кажется разумным, когда ценится, что алгоритм Cox Поля часто, но не всегда, предлагает, чтобы применялось сжимающееся преобразование, такое как квадратный корень или журнал. Существует две главных причины для этого:
Основная причина выбора функций ответа - то, что они обладают естественной технической интерпретацией. Маловероятно, что поведение преобразованной версии функции ответа как интуитивно легко понять.
Отдаленные данные могут строго влиять на тип выбранного преобразования. Применение преобразования, чтобы позволить модели соответствовать неправильным данным хорошо не походит на благоразумную стратегию. “Плохими” данными это принято, что данные действительно аварийные, и причина была обнаружена относительно того, почему данные являются отдаленными; например, “Эмиссия, которой производил чистку анализатор, в то время как результаты были взяты”.
Наконец, если вы не можете найти подходящую модель кандидата на завершении пошагового поиска с преобразованной метрикой, затем серьезная проблема существует или с данными или с текущим уровнем технического знания системы. Увеличение модели или альтернативная экспериментальная или моделирующая стратегия должны быть применены при этих обстоятельствах.
После этих шагов является самым полезным подтвердить вашу модель против других данных (если кто-либо доступен). Смотрите Окно Оценки Модели.
См. также эти страницы инструкции со ссылками на информацию о каждом из шагов, вовлеченных в создание того, и 2D подготовьте модели и затем поиск лучшей подгонки:
Рекомендуемый полный пошаговый процесс лучше всего просматривается графически, как показано в следующей блок-схеме.

Обратите внимание на то, что процесс, изображенный в предыдущей схеме, должен быть выполнен для каждого члена набора функций ответа, сопоставленных с данным ответом, и затем повторился для остающихся ответов.
С запусками n в наборе данных уравнение модели адаптировано к запускам n-1 и предсказанию, взятому из этой модели для остающейся. Различие между записанным значением данных и значением, данным моделью (в значении не использованного запуска), называется невязкой предсказания. НАЖАТИЕ является суммой квадратов остаточных значений предсказания. Квадратный корень из PRESS/n, НАЖИМАЮТ RMSE (среднеквадратичная ошибка предсказания).
Обратите внимание на то, что невязка предсказания отличается от обычной невязки, которая является различием между записанным значением и значением модели, когда адаптировано к целому набору данных.
Статистическая величина НАЖАТИЯ дает хорошую индикацию относительно предсказательной силы вашей модели, которая является, почему минимизация НАЖАТИЯ желательна. Полезно выдержать сравнение, НАЖИМАЮТ RMSE with RMSE, когда это может указать на проблемы со сверхподбором кривой. RMSE минимизирован, когда модель добирается очень близко к каждой точке данных; 'преследование' данных поэтому улучшит RMSE. Однако преследование данных может иногда приводить к сильным колебаниям в модели между точками данных; это поведение может дать хорошие значения RMSE, но не является представительным для данных и не даст надежные значения предсказания, где у вас уже нет данных. НАЖАТЬ статистическая величина RMSE принимает меры против этого путем тестирования, как хорошо текущая модель предсказала бы каждую из точек в наборе данных (в свою очередь), если бы они не были включены в регрессию. Чтобы получить маленькое НАЖИМАЮТ, RMSE обычно указывает, что модель не чрезмерно чувствительна ни к какой одной точке данных.
Для получения дополнительной информации см. Инструкции для Выбора Best Model Fit, Stepwise Regression и Toolbox Terms и Statistics Definitions.
Обратите внимание на то, что вычисление ТРЕБУЕТ модели 2D этапа, применяет тот же принцип (подбирающий модель к запускам n-1 и берущий предсказание из этой модели для остающейся), но в этом случае ожидаемые значения сначала найдены для функций ответа вместо точек данных. Ожидаемое значение, не используя каждый тест в свою очередь, для каждой функции ответа оценивается. Предсказанные функции ответа затем используются, чтобы восстановить локальную кривую для теста, и эта кривая используется, чтобы получить предсказания 2D этапа. Это применяется можно следующим образом:
Вычислить два НАЖАТИЯ этапа:
Для каждого теста, S, делают следующие шаги:
Для каждой из функций ответа вычислите то, чем предсказания функции ответа были бы для S (с функциями ответа S, удаленного из вычисления).
Это дает локальную кривую предсказания C на основе всех тестов кроме S.
Для каждой точки данных в тесте вычислите разность между наблюдаемой величиной и значением, предсказанным C.
Повторитесь для всех тестов.
Суммируйте квадрат всех найденных различий и разделитесь на общее количество точек данных.
