В сценарии обучения с подкреплением, где вы обучаете агента выполнять задачу, среда моделирует динамику, с которой взаимодействует агент. Как показано на следующей схеме, среда:
Получает действия от агента.
Формирует выходные наблюдения в ответ на действия.
Генерирует вознаграждение, измеряющее, насколько хорошо действие способствует достижению задачи.
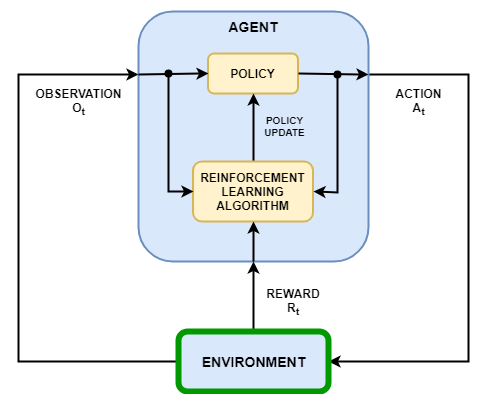
Создание модели среды включает определение следующего:
Сигналы действия и наблюдения, которые агент использует для взаимодействия со средой.
Сигнал вознаграждения, который использует для измерения измерения своего успеха агент. Для получения дополнительной информации смотрите, Задают Сигналы вознаграждения.
Динамическое поведение среды.
Когда вы создаете объект среды, необходимо задать сигналы действия и наблюдения, которые использует для взаимодействия со средой агент. Можно создать и дискретный и непрерывные пространства действий. Для получения дополнительной информации смотрите rlNumericSpec и rlFiniteSetSpec, соответственно.
Сигналы, которые вы выбираете в качестве действия и наблюдения, зависят от вашего приложения. Например, для приложений системы управления, интегралы (и иногда производные) сигналов ошибки являются часто полезными наблюдениями. Кроме того, для приложений отслеживания уставки полезно иметь изменяющуюся во времени уставку в качестве наблюдения.
Когда вы задаете свои сигналы наблюдения, гарантируйте, что все состояния системы наблюдаемы. Например, наблюдение изображений за качающимся маятником имеет информацию о положении, но не имеет достаточной информации для определения скорости маятника. В этом случае можно задать скорость маятника как отдельное наблюдение.
Пакет Reinforcement Learning Toolbox™ обеспечивает, предопределил Simulink® среды, для которых уже заданы действия, наблюдения, вознаграждения и динамика. Можно использовать эти окружения для:
Изучения концепций обучения с подкреплением.
Ознакомления с особенностями пакета Reinforcement Learning Toolbox.
Тестирования своих агентов обучения с подкреплением.
Для получения дополнительной информации смотрите Загрузку Предопределенные окружения Simulink.
Чтобы задать вашу собственную среду обучения с подкреплением, создайте модель Simulink с блоком RL Agent. В этой модели соедините сигналы действия, наблюдения и вознаграждения с блоком RL Agent. Для примера см. Модель Среды Обучения с подкреплением для бака с водой.
Для сигналов действия и наблюдения необходимо создать использование объектов спецификации rlNumericSpec для непрерывных сигналов и rlFiniteSetSpec для дискретных сигналов. Для сигналов шины создайте использование технических требований bus2RLSpec.
Для сигнала вознаграждения создайте скалярный сигнал в модели и соедините этот сигнал с блоком RL Agent. Для получения дополнительной информации смотрите, Задают Сигналы вознаграждения.
После конфигурирования модели Simulink создайте объект среды для модели с помощью rlSimulinkEnv функция.
Если у вас есть образец модели с соответствующим входным портом сигнала действия, выходным портом сигнала наблюдения и скалярным выходным портом сигнала вознаграждения, можно автоматически создать модель Simulink, которая включает этот образец модели и блок RL Agent. Для получения дополнительной информации смотрите createIntegratedEnv. Эта функция возвращает объект среды, спецификации действия и спецификации наблюдений для модели.
Ваша среда может включать стороннюю функциональность. Для получения дополнительной информации смотрите, Объединяются с Существующей Симуляцией или Средой (Simulink).
rlPredefinedEnv | rlSimulinkEnv | createIntegratedEnv
