Ошибка классификации
L = loss(tree,TBL,ResponseVarName)tree классифицирует данные на TBL, когда TBL.ResponseVarName содержит истинные классификации.
При вычислении потери, loss нормирует вероятности класса в Y к вероятностям класса, используемым для обучения, сохраненного в Prior свойство tree.
L = loss(___,Name,Value)Name,Value парные аргументы, с помощью любого из предыдущих синтаксисов. Например, можно задать веса наблюдения или функция потерь.
Вычислите повторно подставленную ошибку классификации для ionosphere набор данных.
load ionosphere
tree = fitctree(X,Y);
L = loss(tree,X,Y)L = 0.0114
Несокращенные деревья решений имеют тенденцию сверхсоответствовать. Один способ сбалансировать сложность модели и эффективность из выборки состоит в том, чтобы сократить дерево (или ограничить его рост) так, чтобы эффективность из выборки и в выборке была удовлетворительной.
Загрузите ирисовый набор данных Фишера. Разделите данные в обучение (50%) и валидацию (50%-е) наборы.
load fisheriris n = size(meas,1); rng(1) % For reproducibility idxTrn = false(n,1); idxTrn(randsample(n,round(0.5*n))) = true; % Training set logical indices idxVal = idxTrn == false; % Validation set logical indices
Вырастите дерево классификации использование набора обучающих данных.
Mdl = fitctree(meas(idxTrn,:),species(idxTrn));
Просмотрите дерево классификации.
view(Mdl,'Mode','graph');

Дерево классификации имеет четыре уровня сокращения. Уровень 0 является полным, несокращенным деревом (как отображено). Уровень 3 является только корневым узлом (i.e., никакие разделения).
Исследуйте ошибку классификации обучающих выборок на каждое поддерево (или уровень сокращения), исключая высший уровень.
m = max(Mdl.PruneList) - 1;
trnLoss = resubLoss(Mdl,'SubTrees',0:m)trnLoss = 3×1
0.0267
0.0533
0.3067
Полное, несокращенное дерево неправильно классифицирует приблизительно 2,7% учебных наблюдений.
Дерево, сокращенное к уровню 1, неправильно классифицирует приблизительно 5,3% учебных наблюдений.
Дерево сокращено к уровню 2 (i.e., пень), неправильно классифицирует приблизительно 30,6% учебных наблюдений.
Исследуйте ошибку классификации выборок валидации на каждом уровне, исключая высший уровень.
valLoss = loss(Mdl,meas(idxVal,:),species(idxVal),'SubTrees',0:m)valLoss = 3×1
0.0369
0.0237
0.3067
Полное, несокращенное дерево неправильно классифицирует приблизительно 3,7% наблюдений валидации.
Дерево, сокращенное к уровню 1, неправильно классифицирует приблизительно 2,4% наблюдений валидации.
Дерево сокращено к уровню 2 (i.e., пень), неправильно классифицирует приблизительно 30,7% наблюдений валидации.
Чтобы сбалансировать сложность модели и эффективность из выборки, считайте сокращение Mdl к уровню 1.
pruneMdl = prune(Mdl,'Level',1); view(pruneMdl,'Mode','graph')

Функции Classification loss измеряют прогнозирующую погрешность моделей классификации. Когда вы сравниваете тот же тип потери среди многих моделей, более низкая потеря указывает на лучшую прогнозную модель.
Рассмотрите следующий сценарий.
L является средневзвешенной потерей классификации.
n является объемом выборки.
Для бинарной классификации:
yj является наблюдаемой меткой класса. Программные коды это как –1 или 1, указывая на отрицательный или положительный класс (или первый или второй класс в ClassNames свойство), соответственно.
f (Xj) является классификационной оценкой положительного класса для наблюдения (строка) j данных о предикторе X.
mj = yj f (Xj) является классификационной оценкой для классификации наблюдения j в класс, соответствующий yj. Положительные значения mj указывают на правильную классификацию и не способствуют очень средней потере. Отрицательные величины mj указывают на неправильную классификацию и значительно способствуют средней потере.
Для алгоритмов, которые поддерживают классификацию мультиклассов (то есть, K ≥ 3):
yj* вектор из K – 1 нуль, с 1 в положении, соответствующем истинному, наблюдаемому классу yj. Например, если истинный класс второго наблюдения является третьим классом и K = 4, то y 2* = [0 0 1 0] ′. Порядок классов соответствует порядку в ClassNames свойство входной модели.
f (Xj) является длиной вектор K из музыки класса к наблюдению j данных о предикторе X. Порядок баллов соответствует порядку классов в ClassNames свойство входной модели.
mj = yj*′f (Xj). Поэтому mj является скалярной классификационной оценкой, которую модель предсказывает для истинного, наблюдаемого класса.
Весом для наблюдения j является wj. Программное обеспечение нормирует веса наблюдения так, чтобы они суммировали к соответствующей предшествующей вероятности класса. Программное обеспечение также нормирует априорные вероятности, таким образом, они суммируют к 1. Поэтому
Учитывая этот сценарий, следующая таблица описывает поддерживаемые функции потерь, которые можно задать при помощи 'LossFun' аргумент пары "имя-значение".
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | 'binodeviance' | |
| Неправильно классифицированный уровень в десятичном числе | 'classiferror' | метка класса, соответствующая классу с максимальным счетом. I {·} является функцией индикатора. |
| Потеря перекрестной энтропии | 'crossentropy' |
Взвешенная потеря перекрестной энтропии где веса нормированы, чтобы суммировать к n вместо 1. |
| Экспоненциальная потеря | 'exponential' | |
| Потеря стержня | 'hinge' | |
| Потеря логита | 'logit' | |
| Минимальный ожидал стоимость misclassification | 'mincost' |
Программное обеспечение вычисляет взвешенную минимальную ожидаемую стоимость классификации с помощью этой процедуры для наблюдений j = 1..., n.
Взвешенное среднее минимального ожидало, что потеря стоимости misclassification Если вы используете матрицу стоимости по умолчанию (чье значение элемента 0 для правильной классификации и 1 для неправильной классификации), то |
| Квадратичная потеря | 'quadratic' |
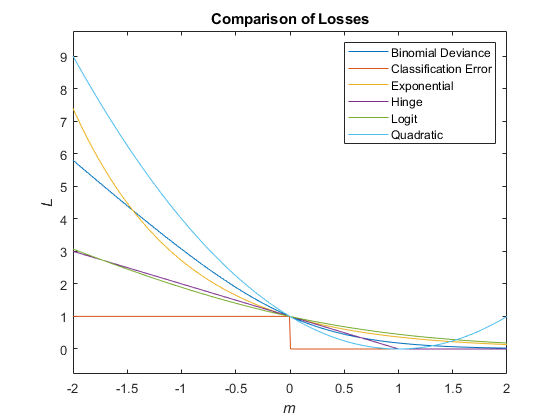
Этот рисунок сравнивает функции потерь (кроме 'crossentropy' и 'mincost') по счету m для одного наблюдения. Некоторые функции нормированы, чтобы пройти через точку (0,1).
Для деревьев score классификации вершины является апостериорной вероятностью классификации в том узле. Апостериорная вероятность классификации в узле является количеством обучающих последовательностей, которые приводят к тому узлу с классификацией, разделенной на количество обучающих последовательностей, которые приводят к тому узлу.
Например, считайте классификацию предиктора X как true когда X< 0.15 или X> 0.95 , и X является ложным в противном случае.
Сгенерируйте 100 случайных точек и классифицируйте их:
rng(0,'twister') % for reproducibility X = rand(100,1); Y = (abs(X - .55) > .4); tree = fitctree(X,Y); view(tree,'Mode','Graph')

Сократите дерево:
tree1 = prune(tree,'Level',1); view(tree1,'Mode','Graph')

Сокращенное дерево правильно классифицирует наблюдения, которые меньше 0.15 как true. Это также правильно классифицирует наблюдения от.15 до.94 как false. Однако это неправильно классифицирует наблюдения, которые больше.94 как false. Поэтому счет к наблюдениям, которые больше.15, должен быть о.05/.85 =. 06 для true, и о.8/.85 =. 94 для false.
Вычислите музыку предсказания к первым 10 строкам X:
[~,score] = predict(tree1,X(1:10)); [score X(1:10,:)]
ans = 10×3
0.9059 0.0941 0.8147
0.9059 0.0941 0.9058
0 1.0000 0.1270
0.9059 0.0941 0.9134
0.9059 0.0941 0.6324
0 1.0000 0.0975
0.9059 0.0941 0.2785
0.9059 0.0941 0.5469
0.9059 0.0941 0.9575
0.9059 0.0941 0.9649
Действительно, каждое значение X (крайний правый столбец), который меньше 0.15, сопоставил баллы (левые и центральные столбцы) 0 и 1, в то время как другие значения X сопоставили множество 0.91 и 0.09. Различие (выигрывают 0.09 вместо ожидаемого .06) происходит из-за статистического колебания: существует 8 наблюдения в X в области значений (.95,1) вместо ожидаемого 5 наблюдения.
