Обучите модель классификации нейронных сетей
Использование fitcnet обучать feedforward, полностью соединенную нейронную сеть для классификации. Первый полносвязный слой нейронной сети имеет связь от сетевого входа (данные о предикторе), и каждый последующий слой имеет связь от предыдущего слоя. Каждый полносвязный слой умножает вход на матрицу веса и затем добавляет вектор смещения. Функция активации следует за каждым полносвязным слоем. Итоговый полносвязный слой и последующая softmax активация функциональный продукт выход сети, а именно, классификационные оценки (апостериорные вероятности) и предсказанные метки. Для получения дополнительной информации смотрите Структуру Нейронной сети.
Mdl = fitcnet(Tbl,ResponseVarName)Mdl классификации нейронных сетей обученное использование предикторов в таблице Tbl и класс помечает в ResponseVarName табличная переменная.
Mdl = fitcnet(___,Name,Value)LayerSizes и Activations аргументы name-value.
Обучите классификатор нейронной сети и оцените эффективность классификатора на наборе тестов.
Считайте файл примера CreditRating_Historical.dat в таблицу. Данные о предикторе состоят из финансовых отношений и информации об отрасли промышленности для списка корпоративных клиентов. Переменная отклика состоит из кредитных рейтингов, присвоенных рейтинговым агентством. Предварительно просмотрите первые несколько строк набора данных.
creditrating = readtable("CreditRating_Historical.dat");
head(creditrating)ans=8×8 table
ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ ______ ______ _______ ________ _____ ________ _______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB' }
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
48631 0.194 0.263 0.062 1.017 0.228 4 {'BBB'}
43768 0.121 0.413 0.057 3.647 0.466 12 {'AAA'}
39255 -0.117 -0.799 0.01 0.179 0.082 4 {'CCC'}
62236 0.087 0.158 0.049 0.816 0.324 2 {'BBB'}
39354 0.005 0.181 0.034 2.597 0.388 7 {'AA' }
Поскольку каждое значение в ID переменная является уникальным идентификатором клиента, то есть, length(unique(creditrating.ID)) равно количеству наблюдений в creditrating, ID переменная является плохим предиктором. Удалите ID переменная из таблицы, и преобразует Industry переменная к categorical переменная.
creditrating = removevars(creditrating,"ID");
creditrating.Industry = categorical(creditrating.Industry);Преобразуйте Rating переменная отклика к порядковому categorical переменная.
creditrating.Rating = categorical(creditrating.Rating, ... ["AAA","AA","A","BBB","BB","B","CCC"],"Ordinal",true);
Разделите данные в наборы обучающих данных и наборы тестов. Используйте приблизительно 80% наблюдений, чтобы обучить модель нейронной сети, и 20% наблюдений проверять производительность обученной модели на новых данных. Используйте cvpartition разделить данные.
rng("default") % For reproducibility of the partition c = cvpartition(creditrating.Rating,"Holdout",0.20); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set creditTrain = creditrating(trainingIndices,:); creditTest = creditrating(testIndices,:);
Обучите классификатор нейронной сети путем передачи обучающих данных creditTrain к fitcnet функция.
Mdl = fitcnet(creditTrain,"Rating")Mdl =
ClassificationNeuralNetwork
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Rating'
CategoricalPredictors: 6
ClassNames: [AAA AA A BBB BB B CCC]
ScoreTransform: 'none'
NumObservations: 3146
LayerSizes: 10
Activations: 'relu'
OutputLayerActivation: 'softmax'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
Mdl обученный ClassificationNeuralNetwork классификатор. Можно использовать запись через точку, чтобы получить доступ к свойствам Mdl. Например, можно задать Mdl.TrainingHistory получить больше информации об учебной истории модели нейронной сети.
Оцените эффективность классификатора на наборе тестов путем вычисления ошибки классификации наборов тестов. Визуализируйте результаты при помощи матрицы беспорядка.
testAccuracy = 1 - loss(Mdl,creditTest,"Rating", ... "LossFun","classiferror")
testAccuracy = 0.8003
confusionchart(creditTest.Rating,predict(Mdl,creditTest))

Задайте структуру классификатора нейронной сети, включая размер полносвязных слоев.
Загрузите ionosphere набор данных, который включает радарные данные сигнала. X содержит данные о предикторе и Y переменная отклика, значения которой представляют или хороший ("g") или плохие ("b") радарные сигналы.
load ionosphereРазделите данные на обучающие данные (XTrain и YTrain) и тестовые данные (XTest и YTest) при помощи стратифицированного раздела затяжки. Зарезервируйте приблизительно 30% наблюдений для тестирования и используйте остальную часть наблюдений для обучения.
rng("default") % For reproducibility of the partition cvp = cvpartition(Y,"Holdout",0.3); XTrain = X(training(cvp),:); YTrain = Y(training(cvp)); XTest = X(test(cvp),:); YTest = Y(test(cvp));
Обучите классификатор нейронной сети. Задайте, чтобы иметь 35 выходных параметров в первом полносвязном слое и 20 выходных параметров во втором полносвязном слое. По умолчанию оба слоя используют исправленный линейный модуль (ReLU) функция активации. Можно изменить функции активации для полносвязных слоев при помощи Activations аргумент значения имени.
Mdl = fitcnet(XTrain,YTrain, ... "LayerSizes",[35 20])
Mdl =
ClassificationNeuralNetwork
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 246
LayerSizes: [35 20]
Activations: 'relu'
OutputLayerActivation: 'softmax'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [47×7 table]
Properties, Methods
Доступ к весам и смещениям для полносвязных слоев обученного классификатора при помощи LayerWeights и LayerBiases свойства Mdl. Первые два элемента каждого свойства соответствуют значениям для первых двух полносвязных слоев, и третий элемент соответствует значениям для итогового полносвязного слоя с softmax функцией активации для классификации. Например, отобразите веса и смещения для второго полносвязного слоя.
Mdl.LayerWeights{2}ans = 20×35
0.0481 0.2501 -0.1535 -0.0934 0.0760 -0.0579 -0.2465 1.0411 0.3712 -1.2007 1.1162 0.4296 0.4045 0.5005 0.8839 0.4624 -0.3154 0.3454 -0.0487 0.2648 0.0732 0.5773 0.4286 0.0881 0.9468 0.2981 0.5534 1.0518 -0.0224 0.6894 0.5527 0.7045 -0.6124 0.2145 -0.0790
-0.9489 -1.8343 0.5510 -0.5751 -0.8726 0.8815 0.0203 -1.6379 2.0315 1.7599 -1.4153 -1.4335 -1.1638 -0.1715 1.1439 -0.7661 1.1230 -1.1982 -0.5409 -0.5821 -0.0627 -0.7038 -0.0817 -1.5773 -1.4671 0.2053 -0.7931 -1.6201 -0.1737 -0.7762 -0.3063 -0.8771 1.5134 -0.4611 -0.0649
-0.1910 0.0246 -0.3511 0.0097 0.3160 -0.0693 0.2270 -0.0783 -0.1626 -0.3478 0.2765 0.4179 0.0727 -0.0314 -0.1798 -0.0583 0.1375 -0.1876 0.2518 0.2137 0.1497 0.0395 0.2859 -0.0905 0.4325 -0.2012 0.0388 -0.1441 -0.1431 -0.0249 -0.2200 0.0860 -0.2076 0.0132 0.1737
-0.0415 -0.0059 -0.0753 -0.1477 -0.1621 -0.1762 0.2164 0.1710 -0.0610 -0.1402 0.1452 0.2890 0.2872 -0.2616 -0.4204 -0.2831 -0.1901 0.0036 0.0781 -0.0826 0.1588 -0.2782 0.2510 -0.1069 -0.2692 0.2306 0.2521 0.0306 0.2524 -0.4218 0.2478 0.2343 -0.1031 0.1037 0.1598
1.1848 1.6142 -0.1352 0.5774 0.5491 0.0103 0.0209 0.7219 -0.8643 -0.5578 1.3595 1.5385 1.0015 0.7416 -0.4342 0.2279 0.5667 1.1589 0.7100 0.1823 0.4171 0.7051 0.0794 1.3267 1.2659 0.3197 0.3947 0.3436 -0.1415 0.6607 1.0071 0.7726 -0.2840 0.8801 0.0848
0.2486 -0.2920 -0.0004 0.2806 0.2987 -0.2709 0.1473 -0.2580 -0.0499 -0.0755 0.2000 0.1535 -0.0285 -0.0520 -0.2523 -0.2505 -0.0437 -0.2323 0.2023 0.2061 -0.1365 0.0744 0.0344 -0.2891 0.2341 -0.1556 0.1459 0.2533 -0.0583 0.0243 -0.2949 -0.1530 0.1546 -0.0340 -0.1562
-0.0516 0.0640 0.1824 -0.0675 -0.2065 -0.0052 -0.1682 -0.1520 0.0060 0.0450 0.0813 -0.0234 0.0657 0.3219 -0.1871 0.0658 -0.2103 0.0060 -0.2831 -0.1811 -0.0988 0.2378 -0.0761 0.1714 -0.1596 -0.0011 0.0609 0.4003 0.3687 -0.2879 0.0910 0.0604 -0.2222 -0.2735 -0.1155
-0.6192 -0.7804 -0.0506 -0.4205 -0.2584 -0.2020 -0.0008 0.0534 1.0185 -0.0307 -0.0539 -0.2020 0.0368 -0.1847 0.0886 -0.4086 -0.4648 -0.3785 0.1542 -0.5176 -0.3207 0.1893 -0.0313 -0.5297 -0.1261 -0.2749 -0.6152 -0.5914 -0.3089 0.2432 -0.3955 -0.1711 0.1710 -0.4477 0.0718
0.5049 -0.1362 -0.2218 0.1637 -0.1282 -0.1008 0.1445 0.4527 -0.4887 0.0503 0.1453 0.1316 -0.3311 -0.1081 -0.7699 0.4062 -0.1105 -0.0855 0.0630 -0.1469 -0.2533 0.3976 0.0418 0.5294 0.3982 0.1027 -0.0973 -0.1282 0.2491 0.0425 0.0533 0.1578 -0.8403 -0.0535 -0.0048
1.1109 -0.0466 0.4044 0.6366 0.1863 0.5660 0.2839 0.8793 -0.5497 0.0057 0.3468 0.0980 0.3364 0.4669 0.1466 0.7883 -0.1743 0.4444 0.4535 0.1521 0.7476 0.2246 0.4473 0.2829 0.8881 0.4666 0.6334 0.3105 0.9571 0.2808 0.6483 0.1180 -0.4558 1.2486 0.2453
⋮
Mdl.LayerBiases{2}ans = 20×1
0.6147
0.1891
-0.2767
-0.2977
1.3655
0.0347
0.1509
-0.4839
-0.3960
0.9248
⋮
Итоговый полносвязный слой имеет два выходных параметров, один для каждого класса в переменной отклика. Количество слоя выходные параметры соответствует первой размерности весов слоя и смещений слоя.
size(Mdl.LayerWeights{end})ans = 1×2
2 20
size(Mdl.LayerBiases{end})ans = 1×2
2 1
Чтобы оценить эффективность обученного классификатора, вычислите ошибку классификации наборов тестов для Mdl.
testError = loss(Mdl,XTest,YTest, ... "LossFun","classiferror")
testError = 0.0774
accuracy = 1 - testError
accuracy = 0.9226
Mdl точно классифицирует приблизительно 92% наблюдений в наборе тестов.
В каждой итерации учебного процесса вычислите потерю валидации нейронной сети. Остановите учебный процесс рано, если потеря валидации достигает разумного минимума.
Загрузите patients набор данных. Составьте таблицу от набора данных. Каждая строка соответствует одному пациенту, и каждый столбец соответствует диагностической переменной. Используйте Smoker переменная как переменная отклика и остальная часть переменных как предикторы.
load patients
tbl = table(Diastolic,Systolic,Gender,Height,Weight,Age,Smoker);Разделите данные на набор обучающих данных tblTrain и валидация установила tblValidation при помощи стратифицированного раздела затяжки. Программное обеспечение резервирует приблизительно 30% наблюдений для набора данных валидации и использует остальную часть наблюдений для обучающего набора данных.
rng("default") % For reproducibility of the partition c = cvpartition(tbl.Smoker,"Holdout",0.30); trainingIndices = training(c); validationIndices = test(c); tblTrain = tbl(trainingIndices,:); tblValidation = tbl(validationIndices,:);
Обучите классификатор нейронной сети при помощи набора обучающих данных. Задайте Smoker столбец tblTrain как переменная отклика. Оцените модель в каждой итерации при помощи набора валидации. Задайте, чтобы отобразить учебную информацию в каждой итерации при помощи Verbose аргумент значения имени. По умолчанию учебный процесс заканчивается рано, если потеря перекрестной энтропии валидации больше или равна минимальной потере перекрестной энтропии валидации, вычисленной до сих пор, шесть раз подряд. Чтобы изменить число раз, потере валидации позволяют быть больше или быть равной минимуму, задать ValidationPatience аргумент значения имени.
Mdl = fitcnet(tblTrain,"Smoker", ... "ValidationData",tblValidation, ... "Verbose",1);
|==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 1| 2.602935| 26.866935| 0.262009| 0.001800| 2.793048| 0| | 2| 1.470816| 42.594723| 0.058323| 0.001460| 1.247046| 0| | 3| 1.299292| 25.854432| 0.034910| 0.000456| 1.507857| 1| | 4| 0.710465| 11.629107| 0.013616| 0.000617| 0.889157| 0| | 5| 0.647783| 2.561740| 0.005753| 0.000957| 0.766728| 0| | 6| 0.645541| 0.681579| 0.001000| 0.000706| 0.776072| 1| | 7| 0.639611| 1.544692| 0.007013| 0.005517| 0.776320| 2| | 8| 0.604189| 5.045676| 0.064190| 0.000534| 0.744919| 0| | 9| 0.565364| 5.851552| 0.068845| 0.000504| 0.694226| 0| | 10| 0.391994| 8.377717| 0.560480| 0.000370| 0.425466| 0| |==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 11| 0.383843| 0.630246| 0.110270| 0.000749| 0.428487| 1| | 12| 0.369289| 2.404750| 0.084395| 0.000531| 0.405728| 0| | 13| 0.357839| 6.220679| 0.199197| 0.000353| 0.378480| 0| | 14| 0.344974| 2.752717| 0.029013| 0.000330| 0.367279| 0| | 15| 0.333747| 0.711398| 0.074513| 0.000328| 0.348499| 0| | 16| 0.327763| 0.804818| 0.122178| 0.000348| 0.330237| 0| | 17| 0.327702| 0.778169| 0.009810| 0.000365| 0.329095| 0| | 18| 0.327277| 0.020615| 0.004377| 0.000380| 0.329141| 1| | 19| 0.327273| 0.010018| 0.003313| 0.000432| 0.328773| 0| | 20| 0.327268| 0.019497| 0.000805| 0.000776| 0.328831| 1| |==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 21| 0.327228| 0.113983| 0.005397| 0.000509| 0.329085| 2| | 22| 0.327138| 0.240166| 0.012159| 0.000333| 0.329406| 3| | 23| 0.326865| 0.428912| 0.036841| 0.000381| 0.329952| 4| | 24| 0.325797| 0.255227| 0.139585| 0.000339| 0.331246| 5| | 25| 0.325181| 0.758050| 0.135868| 0.000890| 0.332035| 6| |==========================================================================================|
Создайте график, который сравнивает учебную потерю перекрестной энтропии и потерю перекрестной энтропии валидации в каждой итерации. По умолчанию, fitcnet хранит информацию потери в TrainingHistory свойство объекта Mdl. Можно получить доступ к этой информации при помощи записи через точку.
iteration = Mdl.TrainingHistory.Iteration; trainLosses = Mdl.TrainingHistory.TrainingLoss; valLosses = Mdl.TrainingHistory.ValidationLoss; plot(iteration,trainLosses,iteration,valLosses) legend(["Training","Validation"]) xlabel("Iteration") ylabel("Cross-Entropy Loss")

Проверяйте итерацию, которая соответствует минимальной потере валидации. Финал возвратил модель Mdl модель, обученная в этой итерации.
[~,minIdx] = min(valLosses); iteration(minIdx)
ans = 19
Оцените потерю перекрестной проверки моделей нейронной сети с различными сильными местами регуляризации и выберите силу регуляризации, соответствующую лучшей модели выполнения.
Считайте файл примера CreditRating_Historical.dat в таблицу. Данные о предикторе состоят из финансовых отношений и информации об отрасли промышленности для списка корпоративных клиентов. Переменная отклика состоит из кредитных рейтингов, присвоенных рейтинговым агентством. Предварительно просмотрите первые несколько строк набора данных.
creditrating = readtable("CreditRating_Historical.dat");
head(creditrating)ans=8×8 table
ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ ______ ______ _______ ________ _____ ________ _______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB' }
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
48631 0.194 0.263 0.062 1.017 0.228 4 {'BBB'}
43768 0.121 0.413 0.057 3.647 0.466 12 {'AAA'}
39255 -0.117 -0.799 0.01 0.179 0.082 4 {'CCC'}
62236 0.087 0.158 0.049 0.816 0.324 2 {'BBB'}
39354 0.005 0.181 0.034 2.597 0.388 7 {'AA' }
Поскольку каждое значение в ID переменная является уникальным идентификатором клиента, то есть, length(unique(creditrating.ID)) равно количеству наблюдений в creditrating, ID переменная является плохим предиктором. Удалите ID переменная из таблицы, и преобразует Industry переменная к categorical переменная.
creditrating = removevars(creditrating,"ID");
creditrating.Industry = categorical(creditrating.Industry);Преобразуйте Rating переменная отклика к порядковому categorical переменная.
creditrating.Rating = categorical(creditrating.Rating, ... ["AAA","AA","A","BBB","BB","B","CCC"],"Ordinal",true);
Создайте cvpartition объект для стратифицированной 5-кратной перекрестной проверки. cvp делит данные в пять сгибов, где каждый сгиб имеет примерно те же пропорции различных кредитных рейтингов. Установите случайный seed на значение по умолчанию для воспроизводимости раздела.
rng("default") cvp = cvpartition(creditrating.Rating,"KFold",5);
Вычислите ошибку классификации перекрестных проверок для классификаторов нейронной сети с различными сильными местами регуляризации. Попробуйте сильные места регуляризации порядка 1/n, где n является количеством наблюдений. Задайте, чтобы стандартизировать данные перед обучением модели нейронной сети.
1/size(creditrating,1)
ans = 2.5432e-04
lambda = (0:0.5:5)*1e-4; cvloss = zeros(length(lambda),1); for i = 1:length(lambda) cvMdl = fitcnet(creditrating,"Rating","Lambda",lambda(i), ... "CVPartition",cvp,"Standardize",true); cvloss(i) = kfoldLoss(cvMdl,"LossFun","classiferror"); end
Постройте график результатов. Найдите силу регуляризации, соответствующую самой низкой ошибке классификации перекрестных проверок.
plot(lambda,cvloss) xlabel("Regularization Strength") ylabel("Cross-Validation Loss")

[~,idx] = min(cvloss); bestLambda = lambda(idx)
bestLambda = 5.0000e-05
Обучите классификатор нейронной сети с помощью bestLambda сила регуляризации.
Mdl = fitcnet(creditrating,"Rating","Lambda",bestLambda, ... "Standardize",true)
Mdl =
ClassificationNeuralNetwork
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Rating'
CategoricalPredictors: 6
ClassNames: [AAA AA A BBB BB B CCC]
ScoreTransform: 'none'
NumObservations: 3932
LayerSizes: 10
Activations: 'relu'
OutputLayerActivation: 'softmax'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
OptimizeHyperparametersОбучите классификатор нейронной сети с помощью OptimizeHyperparameters аргумент, чтобы улучшить получившийся классификатор. Используя этот аргумент вызывает fitcnet минимизировать потерю перекрестной проверки по некоторым проблемным гиперпараметрам с помощью Байесовой оптимизации.
Считайте файл примера CreditRating_Historical.dat в таблицу. Данные о предикторе состоят из финансовых отношений и информации об отрасли промышленности для списка корпоративных клиентов. Переменная отклика состоит из кредитных рейтингов, присвоенных рейтинговым агентством. Предварительно просмотрите первые несколько строк набора данных.
creditrating = readtable("CreditRating_Historical.dat");
head(creditrating)ans=8×8 table
ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ ______ ______ _______ ________ _____ ________ _______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB' }
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
48631 0.194 0.263 0.062 1.017 0.228 4 {'BBB'}
43768 0.121 0.413 0.057 3.647 0.466 12 {'AAA'}
39255 -0.117 -0.799 0.01 0.179 0.082 4 {'CCC'}
62236 0.087 0.158 0.049 0.816 0.324 2 {'BBB'}
39354 0.005 0.181 0.034 2.597 0.388 7 {'AA' }
Поскольку каждое значение в ID переменная является уникальным идентификатором клиента, то есть, length(unique(creditrating.ID)) равно количеству наблюдений в creditrating, ID переменная является плохим предиктором. Удалите ID переменная из таблицы, и преобразует Industry переменная к categorical переменная.
creditrating = removevars(creditrating,"ID");
creditrating.Industry = categorical(creditrating.Industry);Преобразуйте Rating переменная отклика к порядковому categorical переменная.
creditrating.Rating = categorical(creditrating.Rating, ... ["AAA","AA","A","BBB","BB","B","CCC"],"Ordinal",true);
Разделите данные в наборы обучающих данных и наборы тестов. Используйте приблизительно 80% наблюдений, чтобы обучить модель нейронной сети, и 20% наблюдений проверять производительность обученной модели на новых данных. Используйте cvpartition разделить данные.
rng("default") % For reproducibility of the partition c = cvpartition(creditrating.Rating,"Holdout",0.20); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set creditTrain = creditrating(trainingIndices,:); creditTest = creditrating(testIndices,:);
Обучите классификатор нейронной сети путем передачи обучающих данных creditTrain к fitcnet функция, и включает OptimizeHyperparameters аргумент. Для воспроизводимости установите AcquisitionFunctionName к "expected-improvement-plus" в HyperparameterOptimizationOptions структура. Чтобы попытаться получить лучшее решение, определите номер шагов оптимизации к 100 вместо значения по умолчанию 30. fitcnet выполняет Байесовую оптимизацию по умолчанию. Чтобы использовать поиск сетки или случайный поиск, установите Optimizer поле в HyperparameterOptimizationOptions.
rng("default") % For reproducibility Mdl = fitcnet(creditTrain,"Rating","OptimizeHyperparameters","auto", ... "HyperparameterOptimizationOptions", ... struct("AcquisitionFunctionName","expected-improvement-plus", ... "MaxObjectiveEvaluations",100))
|============================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes | | | result | | runtime | (observed) | (estim.) | | | | | |============================================================================================================================================| | 1 | Best | 0.55944 | 4.4429 | 0.55944 | 0.55944 | none | true | 0.05834 | 3 | | 2 | Best | 0.21329 | 18.59 | 0.21329 | 0.22705 | relu | true | 5.0811e-08 | [ 1 25] | | 3 | Accept | 0.74189 | 0.82112 | 0.21329 | 0.21335 | sigmoid | true | 0.57986 | 126 | | 4 | Accept | 0.4501 | 1.0542 | 0.21329 | 0.21351 | tanh | false | 0.018683 | 10 | | 5 | Accept | 0.23045 | 63.554 | 0.21329 | 0.21579 | relu | true | 4.6536e-09 | [ 1 229 3] | | 6 | Accept | 0.74189 | 0.78256 | 0.21329 | 0.21781 | relu | true | 6.1298 | 294 | | 7 | Accept | 0.74189 | 0.3333 | 0.21329 | 0.21338 | relu | true | 27.304 | [ 1 3] | | 8 | Accept | 0.2651 | 16.999 | 0.21329 | 0.21358 | relu | true | 8.0246e-07 | [ 37 2] | | 9 | Accept | 0.22759 | 19.265 | 0.21329 | 0.21361 | tanh | false | 3.1805e-09 | [ 15 1] | | 10 | Accept | 0.23713 | 19.309 | 0.21329 | 0.21358 | tanh | false | 2.5491e-07 | [ 23 2] | | 11 | Accept | 0.21774 | 95.59 | 0.21329 | 0.21368 | tanh | false | 7.5659e-09 | [ 3 20 285] | | 12 | Accept | 0.27813 | 40.925 | 0.21329 | 0.21365 | relu | false | 3.3558e-09 | 140 | | 13 | Accept | 0.21805 | 56.019 | 0.21329 | 0.21368 | relu | false | 0.00012665 | [ 2 208 22] | | 14 | Accept | 0.74189 | 0.38445 | 0.21329 | 0.21346 | relu | false | 0.96119 | [ 39 119 4] | | 15 | Accept | 0.26414 | 15.215 | 0.21329 | 0.21339 | relu | false | 2.023e-06 | [ 26 17] | | 16 | Accept | 0.29593 | 47.519 | 0.21329 | 0.21339 | tanh | true | 3.3214e-09 | [300 127] | | 17 | Accept | 0.28798 | 84.109 | 0.21329 | 0.21339 | tanh | true | 3.101e-05 | [ 64 165] | | 18 | Accept | 0.74189 | 0.56853 | 0.21329 | 0.21338 | tanh | true | 1.2557 | [153 94] | | 19 | Accept | 0.22982 | 83.717 | 0.21329 | 0.2134 | tanh | true | 4.427e-07 | [ 5 4 292] | | 20 | Accept | 0.22505 | 51.26 | 0.21329 | 0.2134 | sigmoid | false | 3.189e-09 | [ 7 162] | |============================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes | | | result | | runtime | (observed) | (estim.) | | | | | |============================================================================================================================================| | 21 | Accept | 0.21456 | 60.938 | 0.21329 | 0.21341 | sigmoid | false | 2.5984e-06 | [ 3 224] | | 22 | Accept | 0.7136 | 0.44787 | 0.21329 | 0.21337 | sigmoid | false | 0.015582 | 6 | | 23 | Accept | 0.27146 | 42.77 | 0.21329 | 0.21335 | sigmoid | false | 1.2532e-07 | 123 | | 24 | Accept | 0.22028 | 48.545 | 0.21329 | 0.21333 | none | false | 3.2499e-09 | [ 30 146] | | 25 | Accept | 0.21329 | 13.21 | 0.21329 | 0.2133 | none | false | 6.8052e-07 | [ 8 2] | | 26 | Accept | 0.21424 | 13.527 | 0.21329 | 0.21328 | none | false | 0.00082724 | [ 1 7 225] | | 27 | Accept | 0.74189 | 0.30095 | 0.21329 | 0.21328 | none | false | 2.7706 | [ 2 201] | | 28 | Accept | 0.21551 | 24.077 | 0.21329 | 0.21331 | none | false | 4.2331e-05 | [ 1 19 52] | | 29 | Accept | 0.2206 | 53.353 | 0.21329 | 0.21334 | none | false | 4.2518e-08 | 266 | | 30 | Accept | 0.21996 | 6.5484 | 0.21329 | 0.21334 | none | true | 3.3059e-09 | 13 | | 31 | Accept | 0.21551 | 17.833 | 0.21329 | 0.21334 | none | true | 2.6343e-07 | [ 3 19 3] | | 32 | Accept | 0.28576 | 81.849 | 0.21329 | 0.21334 | sigmoid | true | 3.1878e-09 | [ 16 294] | | 33 | Accept | 0.2206 | 5.8928 | 0.21329 | 0.21334 | none | true | 3.3018e-08 | 28 | | 34 | Accept | 0.21488 | 71.221 | 0.21329 | 0.21334 | sigmoid | true | 7.9762e-07 | [ 1 5 286] | | 35 | Accept | 0.31564 | 24.922 | 0.21329 | 0.21334 | sigmoid | true | 1.1735e-07 | [ 51 8] | | 36 | Accept | 0.21678 | 48.21 | 0.21329 | 0.21332 | none | true | 2.1257e-08 | [ 4 27 210] | | 37 | Accept | 0.21742 | 59.952 | 0.21329 | 0.21332 | sigmoid | true | 1.8694e-05 | [ 3 235] | | 38 | Accept | 0.22092 | 29.291 | 0.21329 | 0.21332 | none | true | 1.3405e-05 | [ 7 77 8] | | 39 | Accept | 0.74189 | 0.31529 | 0.21329 | 0.21332 | tanh | false | 31.775 | [ 4 8] | | 40 | Accept | 0.27082 | 149.94 | 0.21329 | 0.21332 | tanh | false | 3.6794e-05 | [219 240] | |============================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes | | | result | | runtime | (observed) | (estim.) | | | | | |============================================================================================================================================| | 41 | Accept | 0.21678 | 20.465 | 0.21329 | 0.21334 | sigmoid | true | 3.81e-06 | [ 2 16 25] | | 42 | Accept | 0.22155 | 9.4112 | 0.21329 | 0.20714 | none | false | 0.00019388 | 285 | | 43 | Accept | 0.21742 | 25.778 | 0.21329 | 0.20712 | none | true | 2.1217e-06 | [ 87 3] | | 44 | Accept | 0.21488 | 60.391 | 0.21329 | 0.20711 | relu | false | 3.3101e-05 | [ 1 5 257] | | 45 | Accept | 0.21488 | 13.197 | 0.21329 | 0.21329 | none | false | 4.5453e-06 | [ 1 3] | | 46 | Accept | 0.21488 | 10.038 | 0.21329 | 0.20777 | none | false | 3.4008e-08 | [ 1 5] | | 47 | Accept | 0.21488 | 12.93 | 0.21329 | 0.20775 | sigmoid | false | 1.006e-05 | [ 1 3] | | 48 | Accept | 0.21996 | 6.8334 | 0.21329 | 0.21332 | sigmoid | true | 3.829e-06 | 2 | | 49 | Accept | 0.22155 | 126.94 | 0.21329 | 0.21332 | sigmoid | true | 0.00015279 | [133 92 283] | | 50 | Best | 0.21202 | 48.253 | 0.21202 | 0.21206 | relu | true | 0.00020411 | [ 1 158 39] | | 51 | Accept | 0.29053 | 140.77 | 0.21202 | 0.2122 | relu | true | 4.8947e-05 | [ 14 259 264] | | 52 | Accept | 0.24666 | 46.379 | 0.21202 | 0.21236 | relu | true | 0.0017423 | [ 96 60] | | 53 | Accept | 0.2314 | 132.63 | 0.21202 | 0.21238 | relu | true | 0.0004174 | [237 295] | | 54 | Accept | 0.36968 | 1.3587 | 0.21202 | 0.20862 | relu | true | 0.00058355 | 1 | | 55 | Accept | 0.22791 | 38.591 | 0.21202 | 0.21217 | sigmoid | true | 2.537e-05 | [ 63 1 23] | | 56 | Accept | 0.22314 | 50.941 | 0.21202 | 0.21218 | sigmoid | false | 1.9802e-06 | [ 10 1 174] | | 57 | Accept | 0.22505 | 10.489 | 0.21202 | 0.21384 | tanh | true | 4.2741e-07 | 5 | | 58 | Accept | 0.21488 | 135.54 | 0.21202 | 0.21234 | none | false | 2.1727e-07 | [234 300 1] | | 59 | Accept | 0.42912 | 35.118 | 0.21202 | 0.2116 | relu | true | 0.0010189 | [ 2 271 4] | | 60 | Accept | 0.31818 | 59.012 | 0.21202 | 0.21147 | relu | true | 3.179e-09 | 281 | |============================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes | | | result | | runtime | (observed) | (estim.) | | | | | |============================================================================================================================================| | 61 | Accept | 0.21678 | 42.051 | 0.21202 | 0.21143 | sigmoid | false | 4.8212e-07 | [ 1 2 110] | | 62 | Accept | 0.21583 | 53.945 | 0.21202 | 0.21134 | none | false | 2.0278e-05 | [298 2] | | 63 | Accept | 0.2136 | 8.4188 | 0.21202 | 0.20979 | none | true | 1.0782e-06 | 1 | | 64 | Accept | 0.2171 | 43.599 | 0.21202 | 0.21116 | none | false | 4.6304e-05 | [268 4] | | 65 | Accept | 0.21488 | 48.532 | 0.21202 | 0.21111 | none | true | 2.743e-07 | [297 2] | | 66 | Accept | 0.21901 | 6.22 | 0.21202 | 0.21064 | none | false | 8.4149e-05 | [ 1 42] | | 67 | Accept | 0.32517 | 31.934 | 0.21202 | 0.21055 | sigmoid | true | 3.2658e-05 | [ 1 1 131] | | 68 | Accept | 0.26891 | 63.64 | 0.21202 | 0.2105 | sigmoid | true | 5.5718e-06 | 287 | | 69 | Accept | 0.22664 | 65.645 | 0.21202 | 0.21063 | tanh | false | 2.4001e-08 | [276 2] | | 70 | Accept | 0.21488 | 17.145 | 0.21202 | 0.21209 | none | true | 2.6613e-07 | [ 1 89 2] | | 71 | Accept | 0.31119 | 183.97 | 0.21202 | 0.21325 | sigmoid | true | 6.9584e-09 | [283 219 251] | | 72 | Accept | 0.26669 | 69.335 | 0.21202 | 0.21209 | relu | false | 4.3556e-05 | [296 56] | | 73 | Accept | 0.26478 | 41.246 | 0.21202 | 0.21239 | relu | false | 7.2907e-07 | [163 13 30] | | 74 | Accept | 0.21202 | 38.512 | 0.21202 | 0.21205 | relu | true | 9.7142e-06 | [ 1 206] | | 75 | Accept | 0.21392 | 12.254 | 0.21202 | 0.21202 | sigmoid | true | 6.7548e-06 | [ 1 18 4] | | 76 | Accept | 0.22123 | 70.416 | 0.21202 | 0.21311 | none | false | 9.381e-06 | [ 21 299 96] | | 77 | Accept | 0.21774 | 8.8834 | 0.21202 | 0.21268 | none | false | 3.2274e-09 | 3 | | 78 | Accept | 0.21488 | 26.186 | 0.21202 | 0.21358 | none | true | 4.9871e-07 | [ 1 269] | | 79 | Accept | 0.22155 | 7.719 | 0.21202 | 0.21364 | sigmoid | false | 1.0684e-06 | 1 | | 80 | Accept | 0.28798 | 127.45 | 0.21202 | 0.21359 | tanh | true | 5.792e-07 | [298 179] | |============================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes | | | result | | runtime | (observed) | (estim.) | | | | | |============================================================================================================================================| | 81 | Accept | 0.21869 | 42.326 | 0.21202 | 0.21396 | none | true | 3.2482e-09 | [292 4 30] | | 82 | Accept | 0.21456 | 4.5781 | 0.21202 | 0.21398 | none | false | 1.0932e-07 | 1 | | 83 | Accept | 0.21456 | 56.88 | 0.21202 | 0.21401 | tanh | false | 4.2509e-08 | [ 1 245] | | 84 | Accept | 0.21424 | 13.453 | 0.21202 | 0.21405 | sigmoid | false | 3.2874e-09 | [ 1 26] | | 85 | Accept | 0.21678 | 10.635 | 0.21202 | 0.21404 | tanh | true | 4.1779e-08 | [ 1 8] | | 86 | Accept | 0.22028 | 47.716 | 0.21202 | 0.212 | none | true | 1.1854e-06 | [295 32] | | 87 | Accept | 0.21742 | 33.925 | 0.21202 | 0.212 | relu | false | 3.9749e-08 | [ 1 153] | | 88 | Accept | 0.21392 | 36.047 | 0.21202 | 0.21424 | tanh | false | 9.5415e-06 | [ 1 103] | | 89 | Accept | 0.21233 | 16.3 | 0.21202 | 0.21423 | tanh | false | 1.0503e-06 | [ 1 17 2] | | 90 | Accept | 0.23299 | 9.2509 | 0.21202 | 0.21427 | relu | false | 1.3237e-05 | 1 | | 91 | Accept | 0.21488 | 3.4455 | 0.21202 | 0.212 | none | true | 3.546e-09 | [ 1 110] | | 92 | Accept | 0.21742 | 10.494 | 0.21202 | 0.21431 | relu | true | 5.6941e-05 | [ 1 29] | | 93 | Accept | 0.21647 | 9.7543 | 0.21202 | 0.21431 | tanh | true | 1.895e-06 | [ 1 4] | | 94 | Accept | 0.21456 | 33.436 | 0.21202 | 0.21431 | relu | true | 6.2404e-07 | [ 1 160] | | 95 | Accept | 0.21901 | 2.8367 | 0.21202 | 0.21433 | none | false | 0.00013257 | [ 1 1] | | 96 | Accept | 0.21424 | 35.446 | 0.21202 | 0.21182 | sigmoid | false | 2.1124e-08 | [ 1 131] | | 97 | Accept | 0.21742 | 13.191 | 0.21202 | 0.2143 | relu | true | 1.0947e-05 | [ 2 13 15] | | 98 | Best | 0.2117 | 8.2787 | 0.2117 | 0.21427 | tanh | true | 3.183e-09 | 1 | | 99 | Accept | 0.54895 | 4.6185 | 0.2117 | 0.21009 | relu | false | 3.3662e-09 | [ 1 4] | | 100 | Accept | 0.27972 | 49.201 | 0.2117 | 0.2128 | relu | false | 3.7247e-08 | [239 20] |

__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 100 reached.
Total function evaluations: 100
Total elapsed time: 3855.2145 seconds
Total objective function evaluation time: 3767.578
Best observed feasible point:
Activations Standardize Lambda LayerSizes
___________ ___________ _________ __________
tanh true 3.183e-09 1
Observed objective function value = 0.2117
Estimated objective function value = 0.25267
Function evaluation time = 8.2787
Best estimated feasible point (according to models):
Activations Standardize Lambda LayerSizes
___________ ___________ __________ _____________
none false 4.2331e-05 1 19 52
Estimated objective function value = 0.2128
Estimated function evaluation time = 23.627
Mdl =
ClassificationNeuralNetwork
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Rating'
CategoricalPredictors: 6
ClassNames: [AAA AA A BBB BB B CCC]
ScoreTransform: 'none'
NumObservations: 3146
HyperparameterOptimizationResults: [1×1 BayesianOptimization]
LayerSizes: [1 19 52]
Activations: 'none'
OutputLayerActivation: 'softmax'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [753×7 table]
Properties, Methods
Mdl обученный ClassificationNeuralNetwork классификатор. Модель соответствует лучшей предполагаемой допустимой точке, в противоположность лучшей наблюдаемой допустимой точке. (Для получения дополнительной информации на этом различии, смотрите bestPoint.) Можно использовать запись через точку, чтобы получить доступ к свойствам Mdl. Например, можно задать Mdl.HyperparameterOptimizationResults получить больше информации об оптимизации модели нейронной сети.
Найдите точность классификации модели на наборе тестовых данных. Визуализируйте результаты при помощи матрицы беспорядка.
modelAccuracy = 1 - loss(Mdl,creditTest,"Rating", ... "LossFun","classiferror")
modelAccuracy = 0.8053
confusionchart(creditTest.Rating,predict(Mdl,creditTest))

Модель все предсказала классы в одном модуле истинных классов, означая, что все предсказания выключены не больше, чем одной оценкой.
Обучите классификатор нейронной сети с помощью OptimizeHyperparameters аргумент, чтобы улучшить получившуюся точность классификации. Используйте hyperparameters функция, чтобы задать больше, чем значения по умолчанию для количества используемых слоев и область значений размера слоя.
Считайте файл примера CreditRating_Historical.dat в таблицу. Данные о предикторе состоят из финансовых отношений и информации об отрасли промышленности для списка корпоративных клиентов. Переменная отклика состоит из кредитных рейтингов, присвоенных рейтинговым агентством.
creditrating = readtable("CreditRating_Historical.dat");Поскольку каждое значение в ID переменная является уникальным идентификатором клиента, то есть, length(unique(creditrating.ID)) равно количеству наблюдений в creditrating, ID переменная является плохим предиктором. Удалите ID переменная из таблицы, и преобразует Industry переменная к categorical переменная.
creditrating = removevars(creditrating,"ID");
creditrating.Industry = categorical(creditrating.Industry);Преобразуйте Rating переменная отклика к порядковому categorical переменная.
creditrating.Rating = categorical(creditrating.Rating, ... ["AAA","AA","A","BBB","BB","B","CCC"],"Ordinal",true);
Разделите данные в наборы обучающих данных и наборы тестов. Используйте приблизительно 80% наблюдений, чтобы обучить модель нейронной сети, и 20% наблюдений проверять производительность обученной модели на новых данных. Используйте cvpartition разделить данные.
rng("default") % For reproducibility of the partition c = cvpartition(creditrating.Rating,"Holdout",0.20); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set creditTrain = creditrating(trainingIndices,:); creditTest = creditrating(testIndices,:);
Перечислите гиперпараметры, доступные для этой проблемы подбора кривой Rating ответ.
params = hyperparameters("fitcnet",creditTrain,"Rating"); for ii = 1:length(params) disp(ii);disp(params(ii)) end
1
optimizableVariable with properties:
Name: 'NumLayers'
Range: [1 3]
Type: 'integer'
Transform: 'none'
Optimize: 1
2
optimizableVariable with properties:
Name: 'Activations'
Range: {'relu' 'tanh' 'sigmoid' 'none'}
Type: 'categorical'
Transform: 'none'
Optimize: 1
3
optimizableVariable with properties:
Name: 'Standardize'
Range: {'true' 'false'}
Type: 'categorical'
Transform: 'none'
Optimize: 1
4
optimizableVariable with properties:
Name: 'Lambda'
Range: [3.1786e-09 31.7864]
Type: 'real'
Transform: 'log'
Optimize: 1
5
optimizableVariable with properties:
Name: 'LayerWeightsInitializer'
Range: {'glorot' 'he'}
Type: 'categorical'
Transform: 'none'
Optimize: 0
6
optimizableVariable with properties:
Name: 'LayerBiasesInitializer'
Range: {'zeros' 'ones'}
Type: 'categorical'
Transform: 'none'
Optimize: 0
7
optimizableVariable with properties:
Name: 'Layer_1_Size'
Range: [1 300]
Type: 'integer'
Transform: 'log'
Optimize: 1
8
optimizableVariable with properties:
Name: 'Layer_2_Size'
Range: [1 300]
Type: 'integer'
Transform: 'log'
Optimize: 1
9
optimizableVariable with properties:
Name: 'Layer_3_Size'
Range: [1 300]
Type: 'integer'
Transform: 'log'
Optimize: 1
10
optimizableVariable with properties:
Name: 'Layer_4_Size'
Range: [1 300]
Type: 'integer'
Transform: 'log'
Optimize: 0
11
optimizableVariable with properties:
Name: 'Layer_5_Size'
Range: [1 300]
Type: 'integer'
Transform: 'log'
Optimize: 0
Чтобы попробовать больше слоев, чем значение по умолчанию 1 - 3, установите область значений NumLayers (optimizable переменный 1) к его максимальному допустимому размеру, [1 5]. Кроме того, установите Layer_4_Size и Layer_5_Size (optimizable переменные 10 и 11, соответственно), чтобы быть оптимизированным.
params(1).Range = [1 5]; params(10).Optimize = true; params(11).Optimize = true;
Установите область значений всех размеров слоя (optimizable переменные 7 - 11) к [1 400] вместо [1 300] по умолчанию.
for ii = 7:11 params(ii).Range = [1 400]; end
Обучите классификатор нейронной сети путем передачи обучающих данных creditTrain к fitcnet функция, и включает OptimizeHyperparameters набор аргумента к params. Для воспроизводимости установите AcquisitionFunctionName к "expected-improvement-plus" в HyperparameterOptimizationOptions структура. Чтобы попытаться получить лучшее решение, определите номер шагов оптимизации к 100 вместо значения по умолчанию 30.
rng("default") % For reproducibility Mdl = fitcnet(creditTrain,"Rating","OptimizeHyperparameters",params, ... "HyperparameterOptimizationOptions", ... struct("AcquisitionFunctionName","expected-improvement-plus", ... "MaxObjectiveEvaluations",100))
|============================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes | | | result | | runtime | (observed) | (estim.) | | | | | |============================================================================================================================================| | 1 | Best | 0.74189 | 2.9388 | 0.74189 | 0.74189 | sigmoid | true | 0.68961 | [104 1 5 3 1] | | 2 | Best | 0.2225 | 91.12 | 0.2225 | 0.24316 | relu | true | 0.00058564 | [ 38 208 162] | | 3 | Accept | 0.64081 | 15.805 | 0.2225 | 0.2269 | sigmoid | true | 1.9768e-06 | [ 1 25 1 287 7] | | 4 | Best | 0.21964 | 42.124 | 0.21964 | 0.22319 | none | false | 1.3353e-06 | 320 | | 5 | Accept | 0.74189 | 0.27365 | 0.21964 | 0.21968 | relu | true | 2.7056 | [ 1 2 1] | | 6 | Accept | 0.29752 | 119.81 | 0.21964 | 0.21968 | relu | true | 1.0503e-06 | [301 31 400] | | 7 | Accept | 0.24285 | 49.214 | 0.21964 | 0.21968 | relu | true | 3.9171e-07 | [ 3 142 56] | | 8 | Accept | 0.74189 | 0.5032 | 0.21964 | 0.21968 | none | true | 0.18455 | 338 | | 9 | Best | 0.21551 | 10.569 | 0.21551 | 0.21553 | none | false | 1.8409e-07 | [ 16 3 7] | | 10 | Best | 0.21456 | 58.812 | 0.21456 | 0.21712 | none | false | 3.335e-07 | [ 14 1 389 36] | | 11 | Accept | 0.21774 | 31.378 | 0.21456 | 0.21458 | none | false | 0.0015351 | [ 14 66 66 400] | | 12 | Accept | 0.21774 | 10.648 | 0.21456 | 0.21459 | none | false | 0.00089509 | [ 8 399] | | 13 | Best | 0.21424 | 30.123 | 0.21424 | 0.21427 | sigmoid | false | 1.4746e-06 | [ 2 43 2 34 18] | | 14 | Accept | 0.74189 | 11.099 | 0.21424 | 0.21427 | sigmoid | false | 0.00086753 | [ 2 220 36 224 170] | | 15 | Accept | 0.63636 | 12.882 | 0.21424 | 0.2143 | sigmoid | false | 8.1218e-06 | [ 3 67 55 2 18] | | 16 | Accept | 0.23363 | 57.487 | 0.21424 | 0.21431 | sigmoid | false | 8.5124e-08 | [171 21 1 7] | | 17 | Accept | 0.21964 | 55.479 | 0.21424 | 0.21438 | none | false | 4.7023e-05 | [ 26 250 10 8 66] | | 18 | Accept | 0.22028 | 85.705 | 0.21424 | 0.21433 | none | false | 1.1411e-07 | [104 186 99] | | 19 | Accept | 0.21583 | 94.815 | 0.21424 | 0.21434 | none | false | 0.001281 | [153 320 2 2 238] | | 20 | Accept | 0.74189 | 3.6128 | 0.21424 | 0.21445 | sigmoid | false | 0.080845 | [309 2 400] | |============================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes | | | result | | runtime | (observed) | (estim.) | | | | | |============================================================================================================================================| | 21 | Accept | 0.29053 | 129.97 | 0.21424 | 0.21444 | relu | true | 5.2378e-07 | [ 47 13 122 345 49] | | 22 | Accept | 0.74189 | 0.56884 | 0.21424 | 0.21447 | sigmoid | false | 22.67 | [237 13 2] | | 23 | Accept | 0.74189 | 0.52117 | 0.21424 | 0.21443 | none | false | 26.916 | [354 1 7 29] | | 24 | Accept | 0.56008 | 14.031 | 0.21424 | 0.21436 | relu | true | 1.1199e-05 | [ 74 20 4 1] | | 25 | Accept | 0.21933 | 50.083 | 0.21424 | 0.21437 | none | false | 6.5138e-05 | [ 10 28 266] | | 26 | Accept | 0.21996 | 96.38 | 0.21424 | 0.2144 | none | false | 8.653e-06 | [ 28 140 91 254] | | 27 | Accept | 0.21647 | 21.086 | 0.21424 | 0.21439 | none | false | 7.8745e-05 | [ 87 1 21 14] | | 28 | Accept | 0.23109 | 36.618 | 0.21424 | 0.21446 | sigmoid | false | 2.9094e-06 | [111 4] | | 29 | Accept | 0.22028 | 60.117 | 0.21424 | 0.21446 | none | false | 3.4241e-09 | [ 87 183 2 21] | | 30 | Accept | 0.74189 | 0.76418 | 0.21424 | 0.21434 | relu | true | 0.096418 | [ 26 10 385] | | 31 | Accept | 0.30896 | 96.39 | 0.21424 | 0.21433 | relu | true | 1.4796e-08 | [356 7 185] | | 32 | Accept | 0.22568 | 16.277 | 0.21424 | 0.21442 | sigmoid | false | 5.385e-07 | [ 23 2] | | 33 | Accept | 0.2953 | 73.411 | 0.21424 | 0.21451 | relu | true | 6.7579e-05 | [237 2 167] | | 34 | Accept | 0.22092 | 142.27 | 0.21424 | 0.21452 | none | false | 3.2199e-09 | [ 13 8 386 231] | | 35 | Accept | 0.32804 | 59.882 | 0.21424 | 0.21425 | relu | true | 1.7207e-08 | [335 2] | | 36 | Accept | 0.26446 | 42.748 | 0.21424 | 0.21426 | sigmoid | false | 7.6024e-09 | 170 | | 37 | Accept | 0.25938 | 25.846 | 0.21424 | 0.21556 | sigmoid | false | 1.4964e-06 | 67 | | 38 | Accept | 0.23363 | 29.88 | 0.21424 | 0.21699 | sigmoid | false | 1.3302e-06 | [ 41 12 1 13 2] | | 39 | Accept | 0.21488 | 18.38 | 0.21424 | 0.21429 | none | false | 3.3766e-09 | [325 1 26] | | 40 | Accept | 0.21488 | 4.6847 | 0.21424 | 0.21429 | none | false | 3.8762e-08 | [ 1 13] | |============================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes | | | result | | runtime | (observed) | (estim.) | | | | | |============================================================================================================================================| | 41 | Accept | 0.21964 | 16.462 | 0.21424 | 0.21436 | none | false | 8.2526e-05 | [ 97 11] | | 42 | Accept | 0.22123 | 12.431 | 0.21424 | 0.21569 | none | false | 0.00049767 | [ 42 14 13 4 2] | | 43 | Accept | 0.31691 | 59.148 | 0.21424 | 0.215 | relu | true | 0.00029442 | [ 1 12 384 4 31] | | 44 | Accept | 0.2225 | 82.411 | 0.21424 | 0.215 | relu | true | 3.2207e-09 | [ 2 331 19 74 12] | | 45 | Accept | 0.26478 | 55.779 | 0.21424 | 0.21501 | relu | false | 3.2107e-09 | [ 35 179 14 2] | | 46 | Accept | 0.29021 | 61.335 | 0.21424 | 0.21501 | relu | false | 5.7389e-06 | [ 42 318] | | 47 | Accept | 0.24348 | 129.66 | 0.21424 | 0.21501 | relu | false | 1.3815e-05 | [104 285 121 2 22] | | 48 | Accept | 0.74189 | 0.25805 | 0.21424 | 0.21498 | relu | false | 0.060763 | [ 51 1 26] | | 49 | Accept | 0.25524 | 229.69 | 0.21424 | 0.21498 | relu | false | 1.0038e-07 | [ 11 379 336 33] | | 50 | Accept | 0.24062 | 86.121 | 0.21424 | 0.21499 | relu | false | 4.5255e-07 | [ 8 207 24 285] | | 51 | Accept | 0.27622 | 36.186 | 0.21424 | 0.21499 | relu | false | 6.5926e-09 | 190 | | 52 | Accept | 0.21519 | 45.365 | 0.21424 | 0.215 | tanh | false | 3.2561e-09 | [ 1 170] | | 53 | Accept | 0.22791 | 42.993 | 0.21424 | 0.21661 | tanh | false | 4.052e-09 | [ 2 72 46] | | 54 | Accept | 0.2384 | 56.734 | 0.21424 | 0.21501 | tanh | false | 2.7916e-07 | [199 2 4] | | 55 | Accept | 0.29402 | 400.74 | 0.21424 | 0.2148 | tanh | false | 8.6815e-06 | [358 241 347 187] | | 56 | Accept | 0.21488 | 57.685 | 0.21424 | 0.21618 | sigmoid | false | 9.7045e-08 | [ 1 343] | | 57 | Accept | 0.50731 | 14.593 | 0.21424 | 0.2206 | tanh | false | 0.014697 | [ 1 325] | | 58 | Accept | 0.24507 | 105.57 | 0.21424 | 0.22011 | tanh | false | 1.2961e-08 | [ 53 7 6 364 20] | | 59 | Accept | 0.25683 | 337.11 | 0.21424 | 0.21973 | tanh | false | 5.2292e-08 | [160 173 398 188 2] | | 60 | Accept | 0.21424 | 52.362 | 0.21424 | 0.21365 | none | false | 1.9773e-08 | [265 3 8 144] | |============================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes | | | result | | runtime | (observed) | (estim.) | | | | | |============================================================================================================================================| | 61 | Accept | 0.21901 | 112.95 | 0.21424 | 0.21345 | relu | true | 3.8578e-05 | [ 3 398 139 4] | | 62 | Accept | 0.21551 | 70.941 | 0.21424 | 0.21345 | tanh | false | 1.6012e-07 | [ 1 347] | | 63 | Accept | 0.29561 | 179.56 | 0.21424 | 0.21345 | tanh | false | 5.0988e-07 | [ 52 395 29 179 90] | | 64 | Accept | 0.28894 | 16.156 | 0.21424 | 0.21342 | tanh | false | 3.6595e-08 | 43 | | 65 | Accept | 0.23808 | 110.07 | 0.21424 | 0.21347 | tanh | true | 3.2378e-09 | [ 3 376 75] | | 66 | Accept | 0.23522 | 37.116 | 0.21424 | 0.21346 | tanh | true | 1.1144e-07 | [ 6 100 2] | | 67 | Accept | 0.30451 | 207.92 | 0.21424 | 0.21345 | tanh | true | 4.2187e-06 | [ 64 162 73 215 253] | | 68 | Accept | 0.21519 | 64.314 | 0.21424 | 0.21344 | tanh | true | 3.2005e-09 | [ 1 1 4 42 182] | | 69 | Accept | 0.22823 | 18.554 | 0.21424 | 0.21343 | tanh | true | 3.0624e-08 | [ 2 1 18 2] | | 70 | Accept | 0.4965 | 0.24191 | 0.21424 | 0.21341 | tanh | true | 0.0062297 | 1 | | 71 | Accept | 0.23872 | 59.935 | 0.21424 | 0.2134 | tanh | true | 3.3039e-09 | [ 5 248 6] | | 72 | Accept | 0.24348 | 126.52 | 0.21424 | 0.21338 | tanh | true | 9.1602e-09 | [ 11 1 353 125 26] | | 73 | Accept | 0.33058 | 15.405 | 0.21424 | 0.21333 | tanh | true | 5.149e-09 | 38 | | 74 | Accept | 0.22664 | 93.852 | 0.21424 | 0.21338 | tanh | true | 5.1801e-08 | [ 3 22 13 2 390] | | 75 | Accept | 0.21456 | 39.525 | 0.21424 | 0.21346 | none | false | 9.9076e-07 | [ 8 321 1 14] | | 76 | Accept | 0.24094 | 144.33 | 0.21424 | 0.21341 | tanh | false | 4.8372e-09 | [146 376 4 4] | | 77 | Accept | 0.43134 | 61.629 | 0.21424 | 0.21356 | relu | false | 2.487e-06 | [203 1 325 33 8] | | 78 | Accept | 0.22028 | 185.83 | 0.21424 | 0.21355 | tanh | false | 3.8579e-09 | [210 1 270 256 7] | | 79 | Accept | 0.28894 | 88.793 | 0.21424 | 0.21353 | relu | false | 1.6973e-08 | [ 92 364] | | 80 | Accept | 0.21488 | 15.626 | 0.21424 | 0.21344 | none | false | 4.8495e-08 | [158 1 95 8] | |============================================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Activations | Standardize | Lambda | LayerSizes | | | result | | runtime | (observed) | (estim.) | | | | | |============================================================================================================================================| | 81 | Accept | 0.24634 | 25.257 | 0.21424 | 0.21345 | tanh | true | 3.86e-09 | [ 35 1 51] | | 82 | Accept | 0.21488 | 60.696 | 0.21424 | 0.21257 | sigmoid | false | 1.1764e-06 | [ 1 379] | | 83 | Accept | 0.21964 | 90.211 | 0.21424 | 0.21255 | none | false | 3.2479e-09 | [ 24 341 70 161] | | 84 | Accept | 0.74189 | 0.87744 | 0.21424 | 0.21248 | tanh | false | 19.804 | [125 2 355] | | 85 | Accept | 0.21583 | 46.265 | 0.21424 | 0.21243 | none | false | 3.8097e-05 | [126 1 111 52] | | 86 | Accept | 0.21647 | 94.709 | 0.21424 | 0.21241 | none | false | 4.4626e-05 | [ 60 381 2 257 7] | | 87 | Accept | 0.22409 | 91.623 | 0.21424 | 0.21309 | sigmoid | false | 3.2244e-09 | [ 74 122 6 141] | | 88 | Accept | 0.22982 | 82.493 | 0.21424 | 0.21233 | sigmoid | false | 6.6053e-08 | [ 37 299 3] | | 89 | Accept | 0.22028 | 45.673 | 0.21424 | 0.2123 | none | false | 0.00022752 | [ 6 146 67 11 14] | | 90 | Best | 0.21392 | 104.36 | 0.21392 | 0.21218 | none | true | 4.7915e-09 | [351 52 361 2] | | 91 | Accept | 0.21996 | 22.493 | 0.21392 | 0.21209 | none | true | 3.4932e-09 | [ 17 186 18] | | 92 | Accept | 0.21488 | 4.1562 | 0.21392 | 0.21187 | none | true | 3.8203e-09 | [ 3 1 91] | | 93 | Accept | 0.2206 | 91.939 | 0.21392 | 0.21199 | none | true | 2.6478e-07 | [128 226 140] | | 94 | Accept | 0.22028 | 32.482 | 0.21392 | 0.2119 | none | true | 1.0985e-08 | [ 32 266 81] | | 95 | Accept | 0.21996 | 8.1232 | 0.21392 | 0.21176 | none | true | 3.4762e-09 | 129 | | 96 | Accept | 0.21488 | 20.198 | 0.21392 | 0.21167 | none | true | 9.3788e-08 | [155 1 368 8 393] | | 97 | Accept | 0.21488 | 7.8171 | 0.21392 | 0.21165 | none | true | 4.6151e-08 | [257 1 9] | | 98 | Accept | 0.21996 | 25.05 | 0.21392 | 0.21148 | none | true | 5.0115e-08 | [ 61 392] | | 99 | Accept | 0.21869 | 223.66 | 0.21392 | 0.21139 | none | true | 3.7372e-09 | [397 361 2 26] | | 100 | Accept | 0.74189 | 0.73109 | 0.21392 | 0.21136 | tanh | true | 29.506 | [ 11 9 398] |

__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 100 reached.
Total function evaluations: 100
Total elapsed time: 6645.9313 seconds
Total objective function evaluation time: 6315.0249
Best observed feasible point:
Activations Standardize Lambda LayerSizes
___________ ___________ __________ ________________________
none true 4.7915e-09 351 52 361 2
Observed objective function value = 0.21392
Estimated objective function value = 0.21501
Function evaluation time = 104.357
Best estimated feasible point (according to models):
Activations Standardize Lambda LayerSizes
___________ ___________ __________ __________
sigmoid false 1.1764e-06 1 379
Estimated objective function value = 0.21136
Estimated function evaluation time = 60.6733
Mdl =
ClassificationNeuralNetwork
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Rating'
CategoricalPredictors: 6
ClassNames: [AAA AA A BBB BB B CCC]
ScoreTransform: 'none'
NumObservations: 3146
HyperparameterOptimizationResults: [1×1 BayesianOptimization]
LayerSizes: [1 379]
Activations: 'sigmoid'
OutputLayerActivation: 'softmax'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
Найдите точность классификации модели на наборе тестовых данных. Визуализируйте результаты при помощи матрицы беспорядка.
testAccuracy = 1 - loss(Mdl,creditTest,"Rating", ... "LossFun","classiferror")
testAccuracy = 0.8053
confusionchart(creditTest.Rating,predict(Mdl,creditTest))

Модель все предсказала классы в одном модуле истинных классов, означая, что все предсказания выключены не больше, чем одной оценкой.
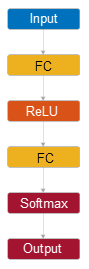
Классификатор нейронной сети по умолчанию имеет следующую структуру слоя.
| Структура | Описание |
|---|---|
|
| Введите — Этот слой соответствует данным о предикторе в Tbl или X. |
Первый полносвязный слой — Этот слой имеет 10 выходных параметров по умолчанию.
| |
Функция активации ReLU —
| |
Итоговый полносвязный слой — Этот слой имеет K выходные параметры, где K является количеством классов в переменной отклика.
| |
Функция Softmax (и для двоичного файла и для классификации мультиклассов) — Результаты соответствуют предсказанным классификационным оценкам (или апостериорные вероятности). | |
| Вывод Этот слой соответствует предсказанным меткам класса. |
Для примера, который показывает, как классификатор нейронной сети с этой структурой слоя возвращает предсказания, смотрите, Предсказывают Используя Структуру Слоя Классификатора Нейронной сети.
Всегда пытайтесь стандартизировать числовые предикторы (см. Standardize). Стандартизация делает предикторы нечувствительными к шкалам, по которым они измеряются.
[1] Glorot, Ксавьер и Иосуа Бенхио. “Изучая трудность учебных глубоких нейронных сетей прямого распространения”. В Продолжениях тринадцатой международной конференции по вопросам искусственного интеллекта и статистики, стр 249–256. 2010.
[2] Он, Kaiming, Сянюй Чжан, Шаоцин Жэнь и Цзянь Сунь. “Копаясь глубоко в выпрямителях: Превосходная эффективность человеческого уровня на imagenet классификации”. В Продолжениях международной конференции IEEE по вопросам компьютерного зрения, стр 1026–1034. 2015.
[3] Nocedal, J. и С. Дж. Райт. Числовая Оптимизация, 2-й редактор, Нью-Йорк: Спрингер, 2006.
ClassificationNeuralNetwork | predict | loss | hyperparameters | margin | edge | ClassificationPartitionedModel | CompactClassificationNeuralNetwork