В некоторых ситуациях вы не можете точно описать выборку данных использование параметрического распределения. Вместо этого функция плотности вероятности (PDF) или кумулятивная функция распределения (cdf) должна быть оценена из данных. Statistics and Machine Learning Toolbox™ предоставляет несколько возможностей для оценки PDF или cdf от выборочных данных.
Ядерное распределение производит непараметрическую оценку плотности вероятности, которая адаптирует себя к данным, вместо того, чтобы выбрать плотность с конкретной параметрической формой и оценить параметры. Это распределение задано средством оценки плотности ядра, функция сглаживания, которая определяет, форма кривой раньше генерировала PDF и значение полосы пропускания, которое управляет гладкостью получившейся кривой плотности.
Подобно гистограмме ядерное распределение создает функцию, чтобы представлять вероятностное распределение с помощью выборочных данных. Но различающийся гистограмма, которая помещает значения в дискретные интервалы, ядерное распределение, суммирует функции сглаживания компонента для каждого значения данных, чтобы произвести сглаженную, непрерывную кривую вероятности. Следующий график показывает визуальное сравнение гистограммы и ядерного распределения, сгенерированного от тех же выборочных данных.
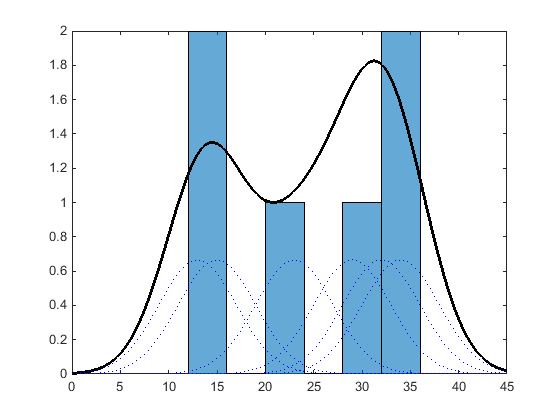
Гистограмма представляет вероятностное распределение путем установления интервалов и размещения каждого значения данных в соответствующий интервал. Из-за этого подхода количества интервала гистограмма производит функцию плотности дискретной вероятности. Эта сила быть неподходящим для определенных приложений, таким как генерация случайных чисел от подходящего распределения.
В качестве альтернативы ядерное распределение создает функцию плотности вероятности (PDF) путем создания отдельной кривой плотности вероятности для каждого значения данных, затем подведения итогов плавных кривых. Этот подход создает одну сглаженную, непрерывную функцию плотности вероятности для набора данных.
Для более общей информации о ядерных распределениях смотрите Ядерное распределение. Для получения информации о том, как работать с ядерным распределением, смотрите Using KernelDistribution Objects и ksdensity.
Эмпирическая кумулятивная функция распределения (ecdf) оценивает cdf случайной переменной путем определения равной вероятности каждому наблюдению в выборке. Из-за этого подхода ecdf является дискретной кумулятивной функцией распределения, которая создает точное совпадение между ecdf и распределением выборочных данных.
Следующий график показывает визуальное сравнение ecdf 20 случайных чисел, сгенерированных от стандартного нормального распределения и теоретического cdf стандартного нормального распределения. Круги указывают на значение ecdf, вычисленного в каждой точке выборочных данных. Пунктирная линия, которая проходит через каждый круг визуально, представляет ecdf, несмотря на то, что ecdf не является непрерывной функцией. Сплошная линия показывает теоретический cdf стандартного нормального распределения, от которого чертились случайные числа в выборочных данных.
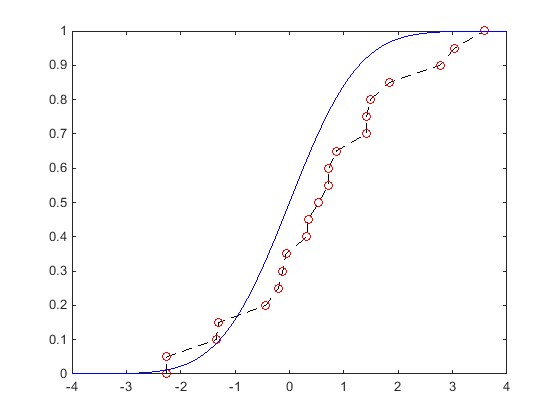
ecdf похож в форме на теоретический cdf, несмотря на то, что это не точное совпадение. Вместо этого ecdf является точным совпадением выборочным данным. ecdf является дискретной функцией и не является гладким, особенно в хвостах, где данные могут быть разреженными. Можно сглаживать распределение с хвостами Парето, с помощью paretotails функция.
Для получения дополнительной информации и дополнительные опции синтаксиса, смотрите ecdf. Чтобы создать непрерывную функцию на основе cdf значений, вычисленных из выборочных данных, смотрите Кусочное Линейное Распределение.
Кусочное линейное распределение оценивает полный cdf для выборочных данных путем вычисления cdf значения в каждой отдельной точке, и затем линейно соединения этих значений, чтобы сформировать непрерывную кривую.
Следующий график показывает cdf для кусочного линейного распределения на основе выборки измерений веса пациентов больницы. Круги представляют каждую отдельную точку данных (измерение веса). Черная линия, которая проходит через каждую точку данных, представляет кусочное линейное распределение cdf для выборочных данных.
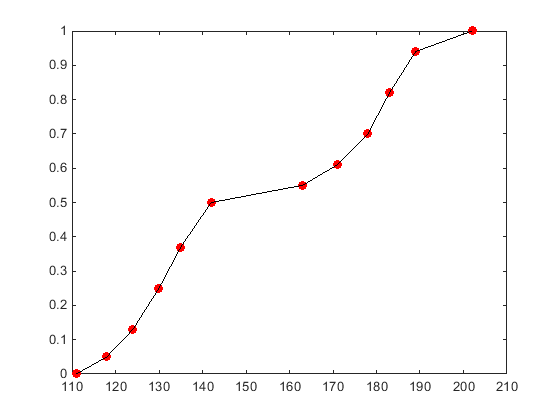
Кусочное линейное распределение линейно соединяется, cdf значения, вычисленные в каждых выборочных данных, указывают, чтобы сформировать непрерывную кривую. В отличие от этого, эмпирическая кумулятивная функция распределения создала использование ecdf функция производит дискретный cdf. Например, случайные числа, сгенерированные от ecdf, могут только включать значения x, содержавшиеся в исходных выборочных данных. Случайные числа, сгенерированные от кусочного линейного распределения, могут включать любое значение x между более низкими и верхними контурами выборочных данных.
Поскольку кусочное линейное распределение cdf создается из значений, содержавшихся в выборочных данных, получившаяся кривая часто не сглаженна, особенно в хвостах, где данные могут быть разреженными. Можно сглаживать распределение с хвостами Парето, с помощью paretotails функция.
Для получения информации о том, как работать с кусочным линейным распределением, смотрите Используя PiecewiseLinearDistribution Объекты.
Хвосты Парето используют кусочный подход, чтобы улучшить подгонку непараметрического cdf путем сглаживания хвостов распределения. Можно соответствовать ядерному распределению, эмпирическому cdf или пользовательскому средству оценки к средним значениям данных, затем подгонка обобщила кривые распределения Парето к хвостам. Этот метод особенно полезен, когда выборочные данные разреженны в хвостах.
Следующий график показывает эмпирический cdf (ecdf) выборки данных, содержащей 20 случайных чисел. Сплошная линия представляет ecdf, и пунктирная линия представляет эмпирический cdf подгонкой хвостов Парето к более низким и верхним 10 процентам данных. Круги обозначают контуры для более низких и верхних 10 процентов данных.
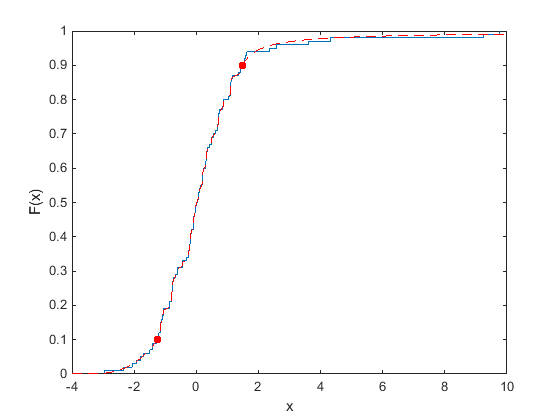
Подбор кривой хвостам Парето к более низким и верхним 10 процентам выборочных данных делает cdf более сглаженное в хвостах, где данные разреженны. Для получения дополнительной информации о работе с хвостами Парето смотрите paretotails.
Треугольное распределение обеспечивает упрощенное представление вероятностного распределения, когда ограниченные выборочные данные доступны. Это непрерывное распределение параметрируется нижним пределом, пиковым местоположением и верхним пределом. Эти точки линейно соединяются, чтобы оценить PDF выборочных данных. Можно использовать среднее значение, медиану или режим данных как пиковое местоположение.
Следующий график показывает треугольному распределению PDF случайной выборки 10 целых чисел от 0 до 5. Нижний предел является самым маленьким целым числом в выборочных данных, и верхний предел является самым большим целым числом. Пик для этого графика в режиме или большей части часто происходящего значения, в выборочных данных.
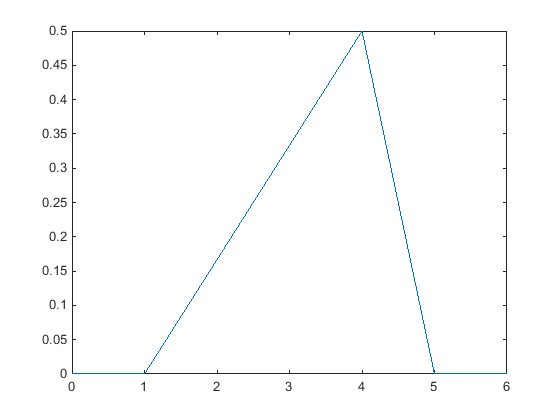
Бизнес-приложения, такие как симуляция и управление проектами иногда используют треугольное распределение, чтобы создать модели, когда ограниченные выборочные данные существуют. Для получения дополнительной информации смотрите Треугольное распределение.
ecdf | ksdensity | paretotails
