Процентили набора данных
Y = prctile(X,p)X для процентов p в интервале [0,100].
Если X вектор, затем Y скаляр или вектор с той же длиной как количество процентилей, которые требуют (length(p)). Y(i) содержит p(i) процентиль.
Если X матрица, затем Y вектор-строка или матрица, где количество строк Y равно количеству процентилей, которые требуют (length(p)). iстрока th Y содержит p(i) процентили каждого столбца X.
Для многомерных массивов, prctile действует по первому неодноэлементному измерению X.
T-обзор [2] является вероятностной структурой данных, которая является разреженным представлением эмпирической кумулятивной функции распределения (CDF) набора данных. T-обзор полезен для вычислительных приближений основанной на ранге статистики (таких как процентили и квантили) из онлайновых или распределенных данных способом, которые допускают управляемую точность, особенно около хвостов распределения данных.
Для данных, которые распределяются в различных разделах, t-обзор вычисляет оценки квантиля (и оценки процентили) для каждого раздела данных отдельно, и затем комбинирует оценки при поддержании постоянной памяти связанная и постоянная относительная точность расчета ( для q th квантиль). По этим причинам t-обзор практичен для работы с длинными массивами.
Чтобы оценить квантили, массив, который распределяется в различных разделах, сначала создайте t-обзор в каждом разделе данных. T-обзор кластеризирует данные в разделе и обобщает каждый кластер центроидным значением и накопленным весом, который представляет количество отсчетов, способствующее кластеру. T-обзор использует большие кластеры (широко расставленные центроиды), чтобы представлять области CDF, которые являются около q = 0.5 и использует небольшие кластеры (плотно распределенные центроиды), чтобы представлять области CDF, которые являются около q = 0 или q = 1.
T-обзор управляет размером кластера при помощи масштабирующейся функции, которая сопоставляет квантиль q с индексом k параметром сжатия . Таким образом,
где отображение k является монотонным с минимальным значением k (0, δ) = 0 и максимальное значение k (1, δ) = δ. Следующий рисунок показывает масштабирующуюся функцию для δ = 10.
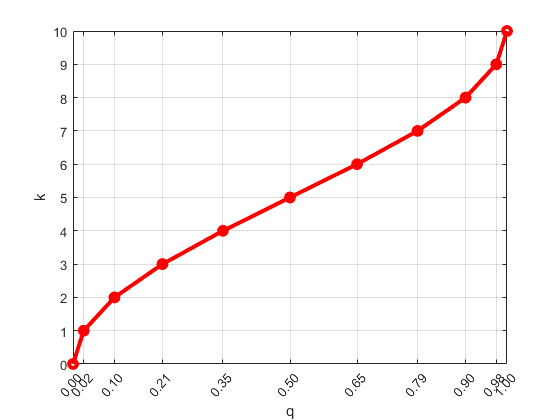
Масштабирующаяся функция переводит квантиль q в масштабный коэффициент k для того, чтобы дать переменные шаги размера в q. В результате размеры кластера неравны (больше вокруг центральных квантилей и меньший около q = 0 или q = 1). Меньшие кластеры допускают лучшую точность около ребер данных.
Чтобы обновить t-обзор с новым наблюдением, которое имеет вес и местоположение, найдите кластер самым близким к новому наблюдению. Затем добавьте вес и обновите центроид кластера на основе взвешенного среднего, при условии, что обновленный вес кластера не превышает ограничение размера.
Можно объединить независимые t-обзоры от каждого раздела данных путем взятия объединения t-обзоров и слияния их центроидов. Объединить t-обзоры, первый вид кластеры из всех независимых t-обзоров в порядке убывания кластерных весов. Затем объедините соседние кластеры, когда они будут соответствовать ограничению размера, чтобы сформировать новый t-обзор.
Если вы формируете t-обзор, который представляет набор полных данных, можно оценить конечные точки (или контуры) каждого кластера в t-обзоре и затем использовать интерполяцию между конечными точками каждого кластера, чтобы найти точные оценки квантиля.
Для n - вектор элемента X, prctile возвращает процентили при помощи основанного на сортировке алгоритма можно следующим образом:
Отсортированные элементы в X взяты в качестве 100 (0.5/n) th, 100 (1.5/n) th..., 100 ([n – 0.5]/n) th процентили. Например:
Для вектора данных пяти элементов такой как {6, 3, 2, 10, 1}, отсортированные элементы {1, 2, 3, 6, 10} соответственно соответствуют 10-м, 30-м, 50-м, 70-м, и 90-м процентилям.
Для вектора данных шести элементов такой как {6, 3, 2, 10, 8, 1}, отсортированные элементы {1, 2, 3, 6, 8, 10} соответственно соответствуют (50/6) th, (150/6) th, (250/6) th, (350/6) th, (450/6) th, и (550/6) th процентили.
prctile линейная интерполяция использования, чтобы вычислить процентили для процентов между 100 (0.5/n) и 100 ([n – 0.5]/n).
prctile присваивает минимальные или максимальные значения элементов в X к процентилям, соответствующим процентам вне той области значений.
prctile обработки NaNs как отсутствующие значения и удаляет их.
[1] Лэнгфорд, E. “Квартили в элементарной статистике”, журнал образования статистики. Издание 14, № 3, 2006.
