В этом примере показано, как настроить гиперпараметры модели машины опорных векторов (SVM) классификации при помощи гипероптимизации параметров управления в приложении Classification Learner. Сравните эффективность набора тестов обученного optimizable SVM к той из лучше всего выполняющей предварительно установленной модели SVM.
В MATLAB® Командное окно, загрузите ionosphere набор данных, и составляет таблицу, содержащую данные. Разделите таблицу на наборы обучающих данных и наборы тестов.
load ionosphere tbl = array2table(X); tbl.Y = Y; rng('default') % For reproducibility of the data split partition = cvpartition(Y,'Holdout',0.15); idxTrain = training(partition); % Indices for the training set tblTrain = tbl(idxTrain,:); tblTest = tbl(~idxTrain,:);
Открытый Classification Learner. Кликните по вкладке Apps, и затем кликните по стреле справа от раздела Apps, чтобы открыть галерею Apps. В группе Machine Learning and Deep Learning нажмите Classification Learner.
На вкладке Classification Learner, в разделе File, выбирают New Session > From Workspace.
В диалоговом окне New Session from Workspace выберите tblTrain таблица из списка Data Set Variable.
Как показано в диалоговом окне, приложение выбирает переменные отклика и переменные предикторы. Переменной отклика по умолчанию является Y. Опция валидации по умолчанию является 5-кратной перекрестной проверкой, чтобы защитить от сверхподбора кривой. В данном примере не изменяйте настройки по умолчанию.
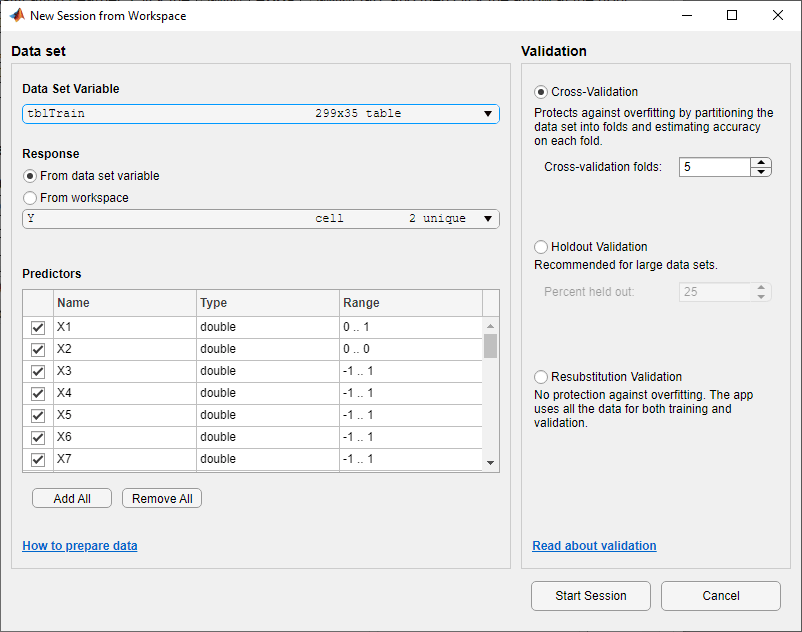
Чтобы принять опции по умолчанию и продолжиться, нажмите Start Session.
Обучите все предварительно установленные модели SVM. На вкладке Classification Learner, в разделе Model Type, кликают по стреле, чтобы открыть галерею. В группе Support Vector Machines нажмите All SVMs. В разделе Training нажмите Train. Приложение обучает один из каждого типа модели SVM и отображает модели в панели Models.
Совет
Если у вас есть Parallel Computing Toolbox™, можно обучить все модели SVM (All SVMs) одновременно путем нажатия кнопки Use Parallel в разделе Training перед нажатием Train. После того, как вы нажимаете Train, диалоговое окно Opening Parallel Pool открывается и остается открытым, в то время как приложение открывает параллельный пул рабочих. В это время вы не можете взаимодействовать с программным обеспечением. После того, как пул открывается, приложение обучает модели SVM одновременно.
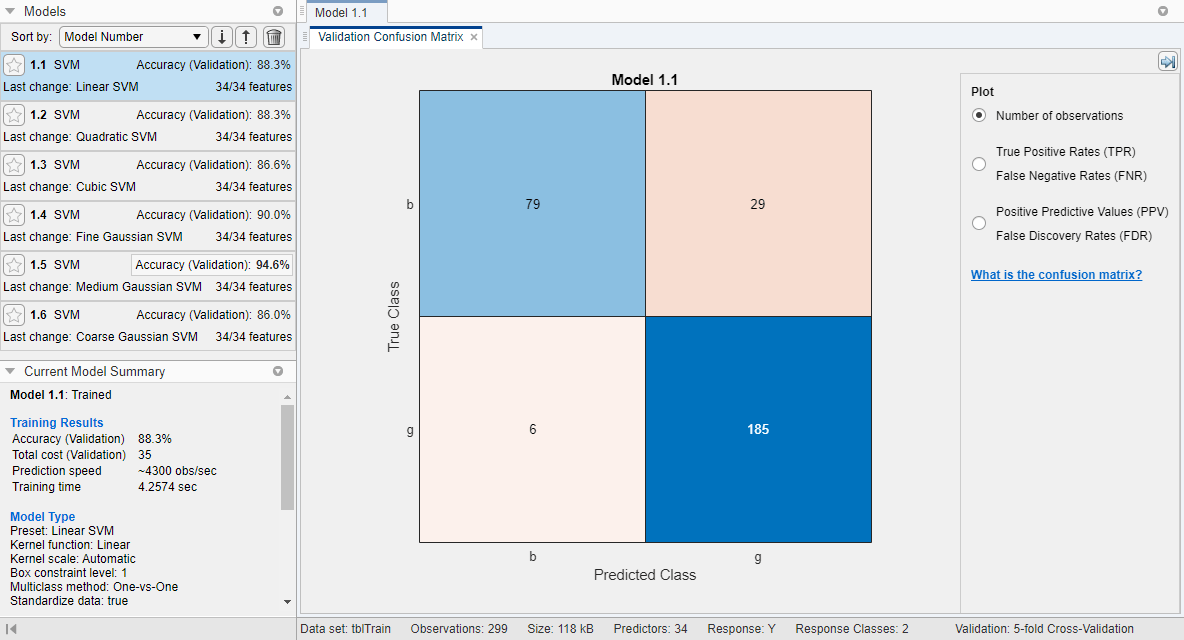
Отображения приложения матрица беспорядка валидации для первой модели (модель 1.1). Синие значения указывают на правильные классификации, и красные значения указывают на неправильные классификации. Панель Models слева показывает точность валидации для каждой модели.
Примечание
Валидация вводит некоторую случайность в результаты. Ваши результаты проверки допустимости модели могут варьироваться от результатов, показанных в этом примере.
Выберите optimizable модель SVM, чтобы обучаться. На вкладке Classification Learner, в разделе Model Type, кликают по стреле, чтобы открыть галерею. В группе Support Vector Machines нажмите Optimizable SVM. Приложение отключает кнопку Use Parallel, когда вы выбираете optimizable модель.
Выберите гиперпараметры модели, чтобы оптимизировать. В разделе Model Type выберите Advanced > Advanced. Приложение открывает диалоговое окно, в котором можно установить флажки Optimize для гиперпараметров, которые вы хотите оптимизировать. По умолчанию все флажки для доступных гиперпараметров устанавливаются. В данном примере снимите флажки Optimize для Kernel function и Standardize data. По умолчанию приложение отключает флажок Optimize для Kernel scale каждый раз, когда функция ядра имеет фиксированное значение кроме Gaussian. Выберите Gaussian функция ядра, и устанавливает флажок Optimize для Kernel scale. Нажмите OK.
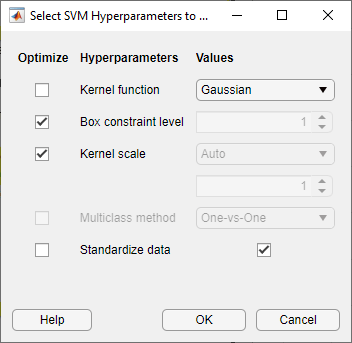
В разделе Training нажмите Train.
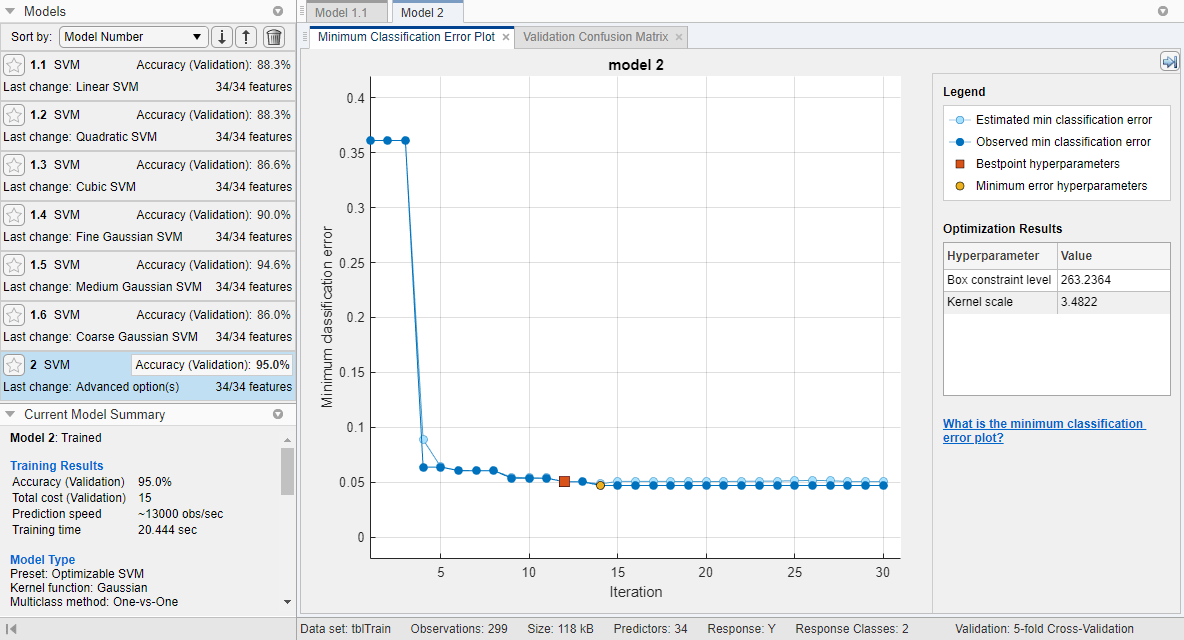
Отображения приложения Minimum Classification Error Plot, когда это запускает процесс оптимизации. В каждой итерации приложение пробует различную комбинацию гиперзначений параметров и обновляет график с минимальной ошибкой классификации валидаций, наблюдаемой до той итерации, обозначенной в темно-синем. Когда приложение завершает процесс оптимизации, оно выбирает набор оптимизированных гиперпараметров, обозначенных красным квадратом. Для получения дополнительной информации смотрите Минимальную Диаграмму погрешностей Классификации.
Списки приложений оптимизированные гиперпараметры и в разделе Optimization Results справа от графика и в разделе Optimized Hyperparameters панели Current Model Summary.
Примечание
В общем случае результаты оптимизации не восстанавливаемы.
Сравните обученные предварительно установленные модели SVM с обученной optimizable моделью. В панели Models приложение подсвечивает самый высокий Accuracy (Validation) путем выделения его в поле. В этом примере обученная optimizable модель SVM превосходит шесть предварительно установленных моделей по характеристикам.
Обученная optimizable модель не всегда имеет более высокую точность, чем обученные предварительно установленные модели. Если обученная optimizable модель не выполняет хорошо, можно попытаться получить лучшие результаты путем выполнения оптимизации для дольше. В разделе Model Type выберите Advanced > Optimizer Options. В диалоговом окне увеличьте значение Iterations. Например, можно дважды кликнуть значение по умолчанию 30 и введите значение 60. Затем нажмите OK.
Поскольку гиперпараметр, настраивающийся часто, приводит к сверхподобранным моделям, проверяйте эффективность optimizable модели SVM на наборе тестов и сравните его с эффективностью лучшей предварительно установленной модели SVM. Начните путем импорта тестовых данных в приложение.
На вкладке Classification Learner, в разделе Testing, выбирают Test Data > From Workspace.
В диалоговом окне Import Test Data выберите tblTest таблица из списка Test Data Set Variable.
Как показано в диалоговом окне, приложение идентифицирует переменные отклика и переменные предикторы.
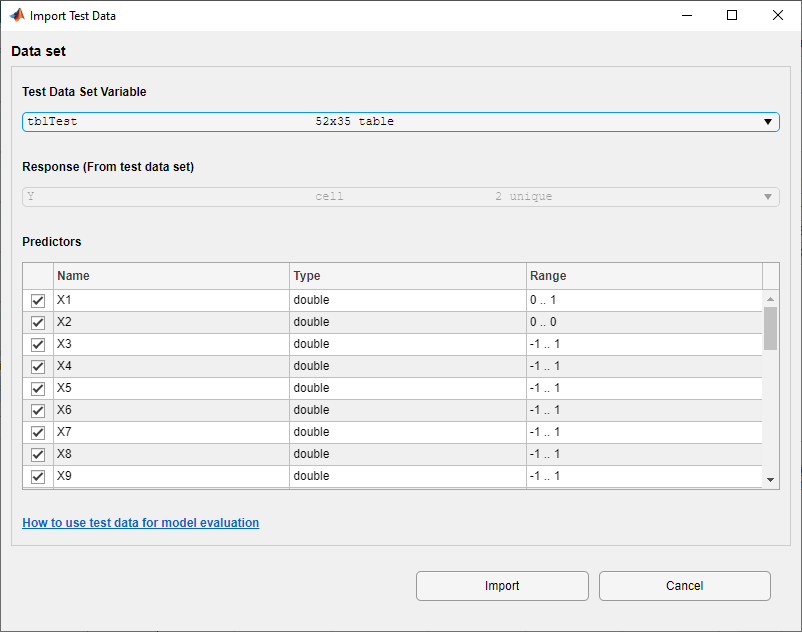
Нажмите Import.
Вычислите точность лучшей предварительно установленной модели и optimizable модели на tblTest данные.
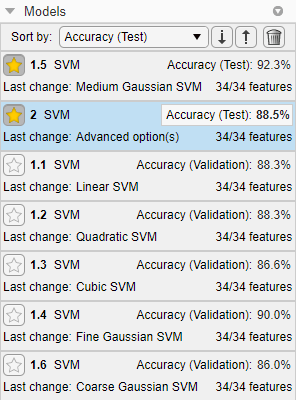
Во-первых, в панели Models, кликните по значкам звезды рядом с моделью Medium Gaussian SVM и моделью Optimizable SVM.
Для каждой модели выберите модель в панели Models, и затем выберите Test All > Test Selected в разделе Testing. Приложение вычисляет эффективность набора тестов модели, обученной на полном наборе данных, включая данные об обучении и валидации.
Сортировка моделей на основе точности набора тестов. В панели Models откройте список Sort by и выберите Accuracy (Test).
В этом примере обученная optimizable модель не выполняет, а также обученная предварительно установленная модель на данных о наборе тестов.
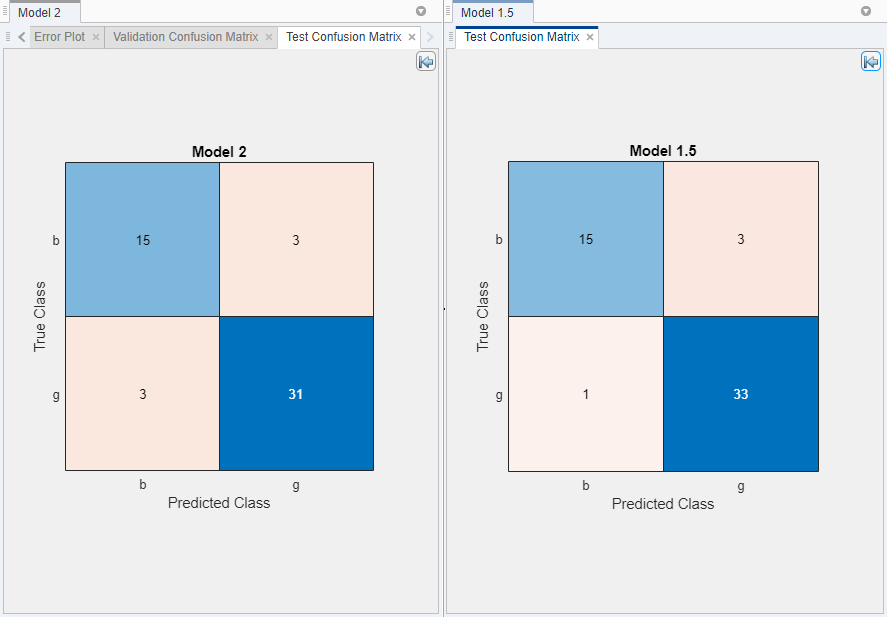
Визуально сравните эффективность набора тестов моделей. Для каждой из звездообразных моделей выберите модель в панели Models. На вкладке Classification Learner, в разделе Plots, кликают по стреле, чтобы открыть галерею, и затем нажать Confusion Matrix (Test) в группе Test Results.
Перестройте размещение графиков лучше сравнить их. Во-первых, закройте матрицу беспорядка валидации для Model 1.1. Затем на вкладке Classification Learner, в разделе Plots, нажимают кнопку Layout и выбирают Compare models. Нажмите кнопку опций графика Hide![]() в правых верхних из графиков сделать больше комнаты для графиков.
в правых верхних из графиков сделать больше комнаты для графиков.
Чтобы возвратиться к первоначальному макету, можно нажать кнопку Layout в разделе Plots и выбрать Single model (Default).
