После того, как вы выберете конкретный тип модели, чтобы обучаться, например, дерево решений или машина опорных векторов (SVM), можно настроить модель путем выбора различных расширенных настроек. Например, можно изменить максимальное количество разделений для дерева решений или ограничения поля SVM. Некоторые из этих опций являются внутренними параметрами модели или гиперпараметрами, которые могут строго влиять на ее эффективность. Вместо того, чтобы вручную выбрать эти опции, можно использовать гипероптимизацию параметров управления в рамках приложения Classification Learner, чтобы автоматизировать выбор гиперзначений параметров. Для данного типа модели приложение пробует различные комбинации гиперзначений параметров при помощи схемы оптимизации, которая стремится минимизировать ошибку классификации модели и возвращает модель оптимизированными гиперпараметрами. Можно использовать получившуюся модель, когда вы были бы любая другая обученная модель.
Примечание
Поскольку гипероптимизация параметров управления может привести к сверхподобранной модели, рекомендуемый подход должен создать отдельный набор тестов прежде, чем импортировать ваши данные в приложение Classification Learner. После того, как вы обучаете свою optimizable модель, вы видите, как она выполняет на вашем наборе тестов. Для примера смотрите, Обучают Классификатор Используя Гипероптимизацию параметров управления в Приложении Classification Learner.
Чтобы выполнить оптимизацию гиперпараметра в Classification Learner, выполните эти шаги:
Выберите тип модели и решите который гиперпараметры оптимизировать. Смотрите Избранные Гиперпараметры, чтобы Оптимизировать.
Примечание
Гипероптимизация параметров управления не поддерживается для логистической регрессии или моделей приближения ядра.
(Необязательно) Задайте, как оптимизация выполняется. Для получения дополнительной информации см. Опции Оптимизации.
Обучите свою модель. Используйте Минимальную Диаграмму погрешностей Классификации, чтобы отследить результаты оптимизации.
Смотрите свою обученную модель. Смотрите Результаты оптимизации.
В приложении Classification Learner, в разделе Model Type вкладки Classification Learner, кликают по стреле, чтобы открыть галерею. Галерея включает optimizable модели, что можно обучить гипероптимизацию параметров управления использования.
После того, как вы выбираете optimizable модель, можно выбрать, какой из ее гиперпараметров вы хотите оптимизировать. В разделе Model Type выберите Advanced > Advanced. Приложение открывает диалоговое окно, в котором можно установить флажки Optimize для гиперпараметров, которые вы хотите оптимизировать. Под Values задайте фиксированные значения для гиперпараметров, которые вы не хотите оптимизировать или которые не optimizable.
Эта таблица описывает гиперпараметры, которые можно оптимизировать для каждого типа модели и поисковой области значений каждого гиперпараметра. Это также включает дополнительные гиперпараметры, для которых можно задать фиксированные значения.
| Модель | Гиперпараметры Optimizable | Дополнительные гиперпараметры | Примечания |
|---|---|---|---|
| Optimizable Tree |
|
| Для получения дополнительной информации см. Усовершенствованные Древовидные Опции. |
| Optimizable Discriminant |
|
Для получения дополнительной информации см. Усовершенствованные Дискриминантные Опции. | |
| Optimizable Naive Bayes |
|
|
Для получения дополнительной информации см. Усовершенствованные Наивные Байесовы Опции. |
| Optimizable SVM |
|
Для получения дополнительной информации см. Усовершенствованные Опции SVM. | |
| Optimizable KNN |
| Для получения дополнительной информации см. Усовершенствованные Опции KNN. | |
| Optimizable Ensemble |
|
|
Для получения дополнительной информации см. Усовершенствованные Опции Ансамбля. |
| Optimizable Neural Network |
|
|
Для получения дополнительной информации см. Усовершенствованные Опции Нейронной сети. |
По умолчанию приложение Classification Learner выполняет гиперпараметр, настраивающийся при помощи Байесовой оптимизации. Цель Байесовой оптимизации и оптимизации в целом, состоит в том, чтобы найти точку, которая минимизирует целевую функцию. В контексте гиперпараметра, настраивающего приложение, точка является набором гиперзначений параметров, и целевая функция является функцией потерь или ошибкой классификации. Для получения дополнительной информации об основах Байесовой оптимизации смотрите Байесов Рабочий процесс Оптимизации.
Можно задать, как настройка гиперпараметра выполняется. Например, можно изменить метод оптимизации в поиск сетки или ограничить учебное время. На вкладке Classification Learner, в разделе Model Type, выбирают Advanced > Optimizer Options. Приложение открывает диалоговое окно, в котором можно выбрать опции оптимизации.
Эта таблица описывает доступные опции оптимизации и их значения по умолчанию.
| Опция | Описание |
|---|---|
| Optimizer | Значения оптимизатора:
|
| Acquisition function | Когда приложение выполняет Байесовую оптимизацию для настройки гиперпараметра, это использует функцию захвата, чтобы определить следующий набор гиперзначений параметров, чтобы попробовать. Значения функции захвата:
Для получения дополнительной информации о том, как эти функции захвата работают в контексте Байесовой оптимизации, смотрите Типы Функции Захвата. |
| Iterations | Каждая итерация соответствует комбинации гиперзначений параметров, которые пробует приложение. Когда вы используете Байесовую оптимизацию или случайный поиск, задаете положительное целое число, которое определяет номер итераций. Значением по умолчанию является Когда вы используете поиск сетки, приложение игнорирует значение Iterations и оценивает потерю в каждой точке в целой сетке. Можно установить учебное ограничение по времени останавливать процесс оптимизации преждевременно. |
| Training time limit | Чтобы установить учебное ограничение по времени, выберите эту опцию и установите опцию Maximum training time in seconds. По умолчанию приложение не имеет учебного ограничения по времени. |
| Maximum training time in seconds | Установите учебное ограничение по времени в секундах как положительное вещественное число. Значением по умолчанию является 300. Время выполнения может превысить учебное ограничение по времени, потому что этот предел не прерывает оценку итерации. |
| Number of grid divisions | Когда вы используете поиск сетки, устанавливаете положительное целое число как количество значений попытки приложения каждого числового гиперпараметра. Приложение игнорирует это значение для категориальных гиперпараметров. Значением по умолчанию является 10. |
После определения, который гиперпараметры модели оптимизировать и устанавливающий любые дополнительные (дополнительные) опции оптимизации, обучите свою optimizable модель. На вкладке Classification Learner, в разделе Training, нажимают Train. Приложение создает Minimum Classification Error Plot, который оно обновляет, когда оптимизация запускает.
Примечание
Когда вы обучаете optimizable модель, приложение отключает кнопку Use Parallel. После того, как обучение завершено, приложение делает кнопку доступной снова, когда вы выбираете nonoptimizable модель. Кнопка прочь по умолчанию.
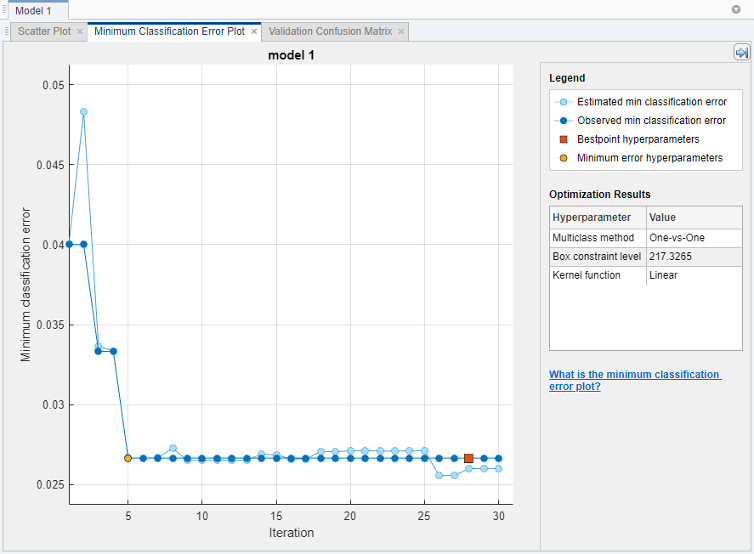
Минимальная диаграмма погрешностей классификации отображает следующую информацию:
Estimated minimum classification error – Каждая голубая точка соответствует оценке минимальной ошибки классификации, вычисленной процессом оптимизации при считании всех наборов гиперзначений параметров попробованными до сих пор, включая текущую итерацию.
Оценка основана на верхнем доверительном интервале текущей ошибочной модели цели классификации, как упомянуто в описании Bestpoint hyperparameters.
Если вы используете сетку поисковый или случайный поиск, чтобы выполнить гипероптимизацию параметров управления, приложение не отображает эти голубые точки.
Observed minimum classification error – Каждая темно-синяя точка соответствует наблюдаемой минимальной ошибке классификации, вычисленной до сих пор процессом оптимизации. Например, в третьей итерации, темно-синяя точка соответствует минимуму ошибки классификации, наблюдаемой в первых, вторых, и третьих итерациях.
Bestpoint hyperparameters – Красный квадрат указывает на итерацию, которая соответствует оптимизированным гиперпараметрам. Можно найти значения оптимизированных гиперпараметров перечисленными в верхнем правом углу графика под Optimization Results.
Оптимизированные гиперпараметры не всегда обеспечивают наблюдаемую минимальную ошибку классификации. Когда приложение выполняет гиперпараметр, настраивающийся при помощи Байесовой оптимизации (см. Опции Оптимизации для краткого введения), это выбирает набор гиперзначений параметров, который минимизирует верхний доверительный интервал ошибочной модели цели классификации, а не набор, который минимизирует ошибку классификации. Для получения дополнительной информации смотрите 'Criterion','min-visited-upper-confidence-interval' аргумент пары "имя-значение" bestPoint.
Minimum error hyperparameters – Желтая точка указывает на итерацию, которая соответствует гиперпараметрам, которые дают к наблюдаемой минимальной ошибке классификации.
Для получения дополнительной информации смотрите 'Criterion','min-observed' аргумент пары "имя-значение" bestPoint.
Если вы используете поиск сетки, чтобы выполнить гипероптимизацию параметров управления, Bestpoint hyperparameters и Minimum error hyperparameters являются тем же самым.
Упускающая суть в графике соответствует NaN минимальные ошибочные значения классификации.
Когда приложение закончило настраивать гиперпараметры модели, оно возвращает модель, обученную с оптимизированными гиперзначениями параметров (Bestpoint hyperparameters). Метрики модели, отображенные графики и экспортируемая модель соответствуют этой обученной модели с фиксированными гиперзначениями параметров.
Чтобы смотреть результаты оптимизации обученной optimizable модели, выберите модель в Models, разделяют на области и смотрят на панель Current Model Summary.
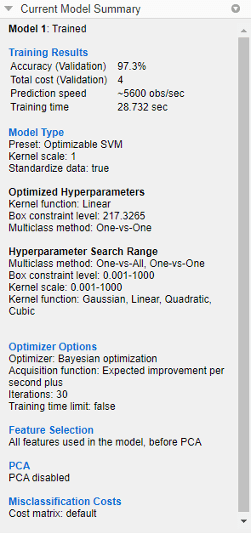
Панель Current Model Summary включает эти разделы:
Training Results – Показывает эффективность optimizable модели
Model Type – Отображает тип optimizable модели и перечисляет любые фиксированные гиперзначения параметров
Optimized Hyperparameters – Перечисляет значения оптимизированных гиперпараметров
Hyperparameter Search Range – Отображает поисковые области значений для оптимизированных гиперпараметров
Optimizer Options – Показывает выбранные варианты оптимизатора
Когда вы выполняете настройку гиперпараметра с помощью Байесовой оптимизации, и вы экспортируете получившуюся обученную optimizable модель в рабочую область как структура, структура включает BayesianOptimization объект в HyperParameterOptimizationResult поле . Объект содержит результаты оптимизации, выполняемой в приложении.
Когда вы генерируете MATLAB® код из обученной optimizable модели, сгенерированный код использует фиксированные и оптимизированные гиперзначения параметров модели, чтобы обучаться на новых данных. Сгенерированный код не включает процесс оптимизации. Для получения информации о том, как выполнить Байесовую оптимизацию, когда вы используете подходящую функцию, смотрите, что Байесова Оптимизация Использует Подходящую Функцию.
